전체 글
-
[SQLD -02] ★NATURAL JOIN★JOIN 총정리★2023.03.11
-
[SQLD-01] ★OUTER JOIN★내부조인(INNER JOIN)★카티션★2023.03.11
-
JetBrains DataGrip(sql IDE) 사용해보기2023.03.06
-
[외교부 데이터 분석_지도 시각화]Python Mapboxgl 활용하기2023.02.23
[SQLD -03] ★DECODE★CROSS JOIN★
1. DECODE
CREATE TABLE 조직 (조직ID VARCHAR2(12) , 조직명 VARCHAR2(16));
CREATE TABLE 영업고객 (고객번호 NUMBER , 고객구분코드 VARCHAR2(3) , 담당조직ID VARCHAR2(4));
INSERT INTO 조직 (조직ID, 조직명) VALUES ('0tjq' ,'강남 본점');
INSERT INTO 조직 (조직ID, 조직명) VALUES ('wzqf' ,'영등포 지점');
INSERT INTO 조직 (조직ID, 조직명) VALUES ('m1gk' ,'신촌 지점');
INSERT INTO 조직 (조직ID, 조직명) VALUES ('hyao' ,'을지로 지점');
INSERT INTO 영업고객 (고객번호, 고객구분코드 , 담당조직ID) VALUES (1 ,'A1' , '0tjq');
INSERT INTO 영업고객 (고객번호, 고객구분코드 , 담당조직ID) VALUES (2 ,'A1' , 'wzqf');
INSERT INTO 영업고객 (고객번호, 고객구분코드 , 담당조직ID) VALUES (3 ,'A1' , 'wzqf');
INSERT INTO 영업고객 (고객번호, 고객구분코드 , 담당조직ID) VALUES (4 ,'B1' , 'm1gk');
INSERT INTO 영업고객 (고객번호, 고객구분코드 , 담당조직ID) VALUES (5 ,'B1' , NULL);
INSERT INTO 영업고객 (고객번호, 고객구분코드 , 담당조직ID) VALUES (6 ,'A1' , NULL);
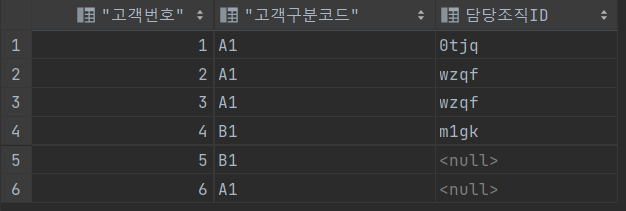
SELECT A.고객번호, A.고객구분코드 , B.조직명
FROM 영업고객 A, 조직 B
WHERE B.조직ID = DECODE(A.고객구분코드 , 'B1' , '0tjq' , A.담당조직ID)
ORDER BY A.고객번호;==> A.고객구분코드가 'B1' 이면 '0tjq' return , 아니면 A.담당조직 ID 출력
==> B.조직 ID ==> 고객구분코드가 B1 이면 담당조직 ID 0tjq , A1이면 wzqf, m1gk 출력
1 A 1 강남본점
2 A1 영등포지점
3 A1 영등포지점
4 B1 강남본점
5 B1 강남본점
2. CROSS JOIN
SELECT * FROM 조직 A CROSS JOIN 영업고객 B
WHERE B.담당조직ID = A.조직ID
3. LEFT OUTER JOIN
SELECT * FROM 조직 A LEFT OUTER JOIN 영업고객 B
ON B.담당조직ID = A.조직ID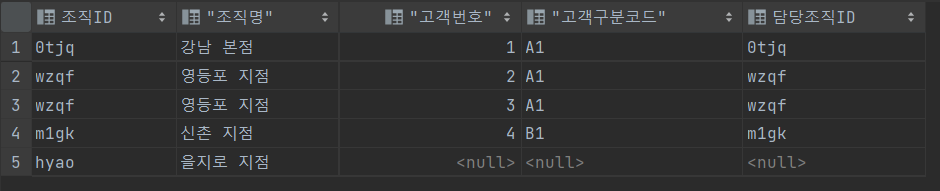
4. RIGHT OUTER JOIN
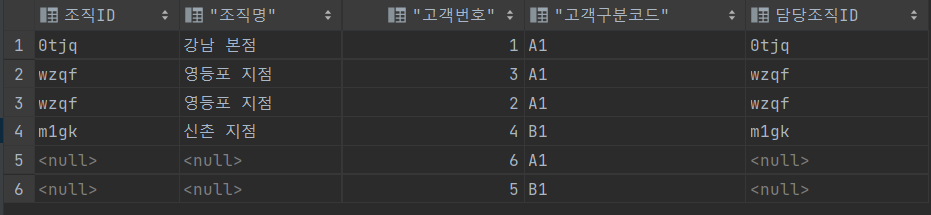
5. INNER JOIN

'SQL > SQLD' 카테고리의 다른 글
[SQLD -02] ★NATURAL JOIN★JOIN 총정리★
1. NATURAL JOIN
CREATE TABLE T1 (C1 VARCHAR2(2) , C2 VARCHAR2(2));
CREATE TABLE T2 (C1 VARCHAR2(2) , C3 VARCHAR2(2));
-- DROP TABLE T1;
-- DROP TABLE T2;
INSERT INTO T1 (C1, C2) VALUES (1 ,'A');
INSERT INTO T1 (C1, C2) VALUES (2 ,'B');
INSERT INTO T1 (C1, C2) VALUES (3 ,'C');
--
INSERT INTO T2 (C1, C3) VALUES (1 ,'A');
INSERT INTO T2 (C1, C3) VALUES (1 ,'B');
INSERT INTO T2 (C1, C3) VALUES (2 ,'B');
INSERT INTO T2 (C1, C3) VALUES (3 ,'C');
INSERT INTO T2 (C1, C3) VALUES (3 ,'A');
INSERT INTO T2 (C1, C3) VALUES (4 ,'B');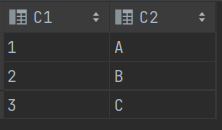
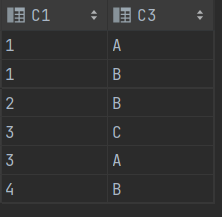
SELECT * FROM T1 A NATURAL JOIN T2 B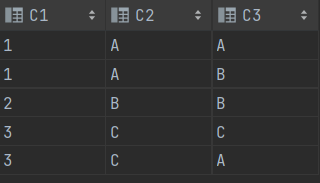
==> Natural Join 절은 양쪽 테이블의 C1 칼럼을 기준으로 등가 조인(EQUIJOIN) 한다.
2. JOIN 총정리
1> OUTER JOIN
SELECT * FROM T1 A ,T2 B WHERE A.C1 = B.C1==> B테이블을 A테이블 옆에 모두 추가하기(A 테이블의 C1 열 기준으로)
==> FROM 절 바로 뒤에 있는 테이블명이 기준점이다! WHERE 절은 신경끄기
2> FULL OUTER JOIN
SELECT * FROM T1 A FULL OUTER JOIN T2 B ON A.C1 = B.C1SELECT * FROM T1 A FULL OUTER JOIN T2 B ON A.C1(+) = B.C1SELECT * FROM T1 A ,T2 B WHERE A.C1(+) = B.C1
==> A테이블을 기준으로 B테이블 추가 ==> A테이블에 없는 경우 B테이블 값들 이어 붙이기
==> + 가 붙여져있을 경우 옆에 있는 테이블에 있는 모든 값을 추가한다.
SELECT * FROM T1 A ,T2 B WHERE A.C1 = B.C1(+)SELECT * FROM T1 A FULL OUTER JOIN T2 B ON A.C1 = B.C1(+)
==> A 테이블 기준으로 B테이블 추가하는데, A테이블에 없는 값 있을 경우 생략한다.
==> + 가 붙여져있을 경우 옆에 있는 테이블에 있는 모든 값을 추가한다.(A값 모두 추가)
3> RIGHT OUTER JOIN
SELECT * FROM T1 A RIGHT OUTER JOIN T2 B ON A.C1 = B.C1SELECT * FROM T1 A RIGHT OUTER JOIN T2 B ON A.C1(+) = B.C1==> T2 B 를 기준으로 조인 ==> A.C1(+)의 옆에 B를 다 추가한다.

4> LEFT OUTER JOIN
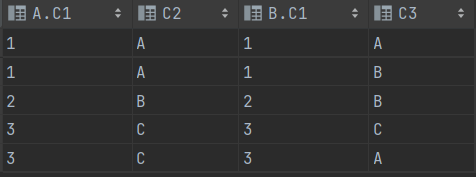
SELECT * FROM T1 A LEFT OUTER JOIN T2 B ON A.C1 = B.C1SELECT * FROM T1 A LEFT OUTER JOIN T2 B ON A.C1 = B.C1(+)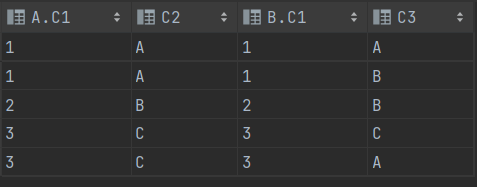
==> T1 A 를 기준으로 조인 ==> B.C1(+)의 옆에 A를 다 추가한다.
5> INNER JOIN
SELECT * FROM T1 A INNER JOIN T2 B ON A.C1 = B.C1SELECT * FROM T1 A INNER JOIN T2 B ON A.C1 = B.C1(+)SELECT * FROM T2 B INNER JOIN T1 A ON B.C1 = A.C1
SELECT * FROM T1 A INNER JOIN T2 B ON A.C1(+) = B.C1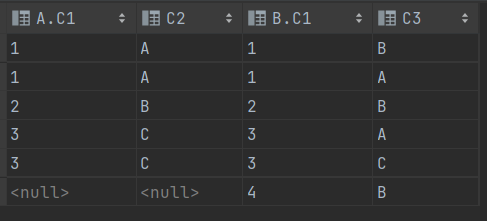
6> NATURAL JOIN
SELECT * FROM T1 A NATURAL JOIN T2 B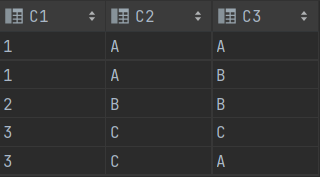
SELECT * FROM T2 A NATURAL JOIN T1 B
7> USING JOIN
SELECT * FROM T1 A JOIN T2 B USING (C1)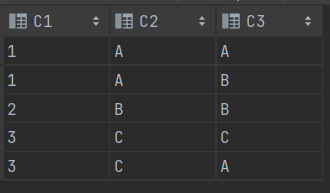
==> 등가 조인 ==> 지정한 컬럼을 기준으로
8> LEFT JOIN
'SQL > SQLD' 카테고리의 다른 글
[SQLD-01] ★OUTER JOIN★내부조인(INNER JOIN)★카티션★
1. OUTER JOIN
CREATE TABLE 고객 (고객번호 NUMBER PRIMARY KEY , 고객명 VARCHAR2(9));
CREATE TABLE 주문 (주문번호 NUMBER PRIMARY KEY , 고객번호 VARCHAR2(9) , 주문금액 VARCHAR2(9));==> VARCHAR2(9) ==> 한글 하나당 3 byte
INSERT INTO 고객 (고객번호, 고객명) VALUES (1, '김대원');
INSERT INTO 고객 (고객번호, 고객명) VALUES (2, '노영미');
INSERT INTO 고객 (고객번호, 고객명) VALUES (3, '김경진');
INSERT INTO 고객 (고객번호, 고객명) VALUES (4, '박하연');
INSERT INTO 주문 (주문번호, 고객번호, 주문금액) VALUES (2001, 1 , 40000);
INSERT INTO 주문 (주문번호, 고객번호, 주문금액) VALUES (2002, 2 , 15000);
INSERT INTO 주문 (주문번호, 고객번호, 주문금액) VALUES (2003, 2 , 7000);
INSERT INTO 주문 (주문번호, 고객번호, 주문금액) VALUES (2004, 2 , 8000);
INSERT INTO 주문 (주문번호, 고객번호, 주문금액) VALUES (2005, 2 , 20000);
INSERT INTO 주문 (주문번호, 고객번호, 주문금액) VALUES (2006, 3 , 5000);
INSERT INTO 주문 (주문번호, 고객번호, 주문금액) VALUES (2007, 3 , 9000);SELECT * FROM 고객;
SELECT * FROM 주문;
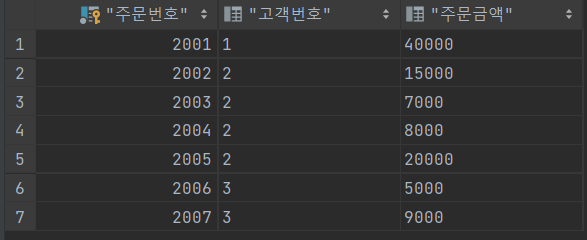
SELECT *
FROM 고객 A, 주문 B
WHERE B.고객번호(+) = A.고객번호
AND B.주문금액(+) > 10000;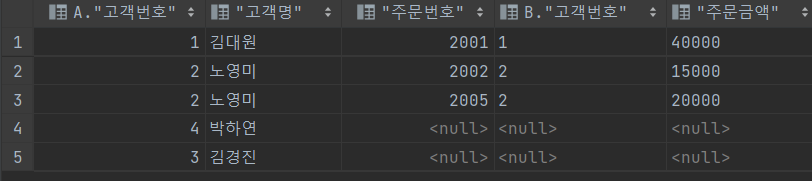
OUTER JOIN
주문 테이블을 고객 테이블(+) 가 없는 을 기준으로 JOIN 시킨다.
SELECT *
FROM 고객 A, 주문 B
WHERE B.고객번호 = A.고객번호(+);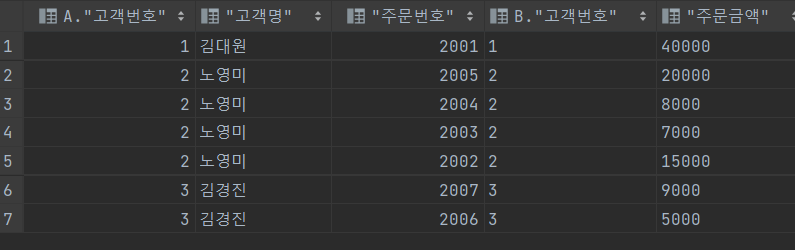
SELECT SUM(B.주문금액) / COUNT (DISTINCT A.고객번호) AS R1
FROM 고객 A, 주문 B
WHERE B.고객번호(+) = A.고객번호
AND B.주문금액(+) > 10000;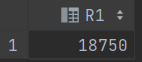
2. 카티션
CREATE TABLE T1 (C1 VARCHAR2(2) , C2 VARCHAR2(2) );
CREATE TABLE T2 (C1 VARCHAR2(2) , C2 VARCHAR2(2) );
INSERT INTO T1 (C1 , C2) VALUES (1, 'A');
INSERT INTO T1 (C1 , C2) VALUES (2, 'B');
INSERT INTO T1 (C1 , C2) VALUES (3, 'C');
INSERT INTO T1 (C1 , C2) VALUES (4, 'D');
INSERT INTO T2 (C1 , C2) VALUES (1, 'A');
INSERT INTO T2 (C1 , C2) VALUES (1, 'B');
INSERT INTO T2 (C1 , C2) VALUES (2, 'A');
INSERT INTO T2 (C1 , C2) VALUES (3, 'B');
INSERT INTO T2 (C1 , C2) VALUES (3, 'C');
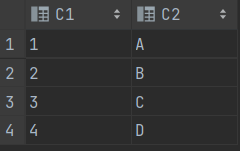
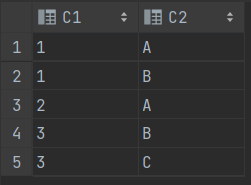
SELECT *
FROM T1 A , T2 B
WHERE A.C1 >=2 AND B.C2 IN('A' , 'C')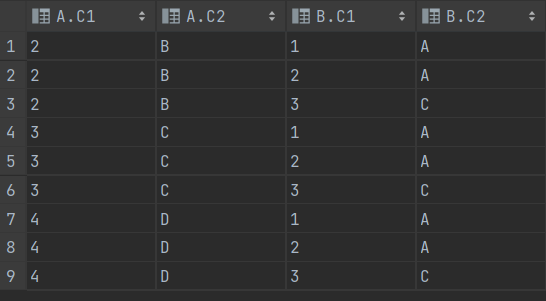
==> 조인 조건이 누락되면 카티션 곱 집합이 생성된다.
3. 표준조인(INNER JOIN)
CREATE TABLE T1 (C1 VARCHAR2(2) , C2 VARCHAR2(2));
CREATE TABLE T2 (C1 VARCHAR2(2) , C2 VARCHAR2(2));
INSERT INTO T1 (C1, C2) VALUES (1 ,'A');
INSERT INTO T1 (C1, C2) VALUES (2 ,'B');
INSERT INTO T1 (C1, C2) VALUES (3 ,'C');
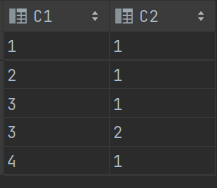
INSERT INTO T2 (C1, C2) VALUES (1 ,1);
INSERT INTO T2 (C1, C2) VALUES (2 ,1);
INSERT INTO T2 (C1, C2) VALUES (3 ,1);
INSERT INTO T2 (C1, C2) VALUES (3 ,2);
INSERT INTO T2 (C1, C2) VALUES (4 ,1);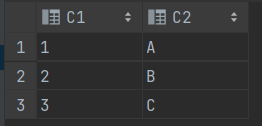
SELECT * FROM T1 A INNER JOIN T2 B
ON B.C1 = A.C1 WHERE A.C1 >=2;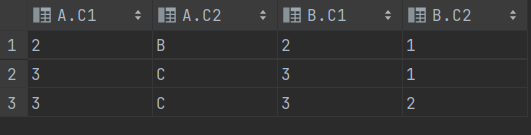
==> INNER JOIN은 ON 절에 조건 기술
==> 공통적인거 써놓는다.
'SQL > SQLD' 카테고리의 다른 글
JetBrains DataGrip(sql IDE) 사용해보기
1. JetBrains의 DataGrip 설치하기
https://www.jetbrains.com/datagrip/download/#section=windows
Download DataGrip: Cross-Platform IDE for Databases & SQL
Download the latest version of DataGrip for Windows, macOS or Linux.
www.jetbrains.com

2. Oracle 연결하기

https://knowallworld.tistory.com/56
ORACLE_SQL 설치부터 SQL_DEVELOPER 까지(오류 해결)
1. ORACLE 홈페이지 21c 다운로드(22.07.08 기준 최신버전) 캡쳐를 잘 못했지만 경로 설정부분 default로 되어있는 거 체크하고 그냥 계속 다음 누른다. ==> 관리자 계정 설정시 아이디 : system 비밀번호 : 1
knowallworld.tistory.com
참고
3. Oracle driver 설치


4. SCOTT 연결하기

'IT에대해 알아보자 > SQL' 카테고리의 다른 글
| ORACLE_SQL 설치부터 SQL_DEVELOPER 까지(오류 해결) (0) | 2022.07.08 |
|---|
[외교부 인턴-마지막날(총정리)]2022 데이터 분석 청년인재 양성 사업-후기_02
4. 외교부에서의 업무 Start
외교부의 내부망 ID , PW 를 할당 받고 , 출입증 카드까지 받은 뒤에 본격적으로 외교부 업무를 시작하게 되었다.(10월경)

9월은 업무 적응 기간이 필요해 한달간은 업무 전반적인 내용에 대해 파악하는 시간을 가졌으며, 남는 시간엔 취준에 몰두해야만 한단 생각에 코테에 집중했다.(나름 3~4개 회사의 코테도 통과했다.)
10월부턴 전세계 공관별 문서 발급과 관련한 Raw Data를 받아 직접 정제하고 전처리하는 업무를 부여 받았다.
매주 주간보고서 작성을 통해 사무관님께 피드백을 받았으며 분석의 방향성을 정하였다.
여러 분석결과를 도출하였는데, 이를 Notion에 업로드 할 예정이다.

5. 외교부에서의 공부
머신러닝, 기초통계에 대해 부족함을 느끼게 되면서, 적절한 분석결과가 도출 되지 못하였다.
이에,
https://knowallworld.tistory.com/category/%EA%B8%B0%EC%B4%88%ED%86%B5%EA%B3%84
'기초통계' 카테고리의 글 목록
knowallworld.tistory.com
https://knowallworld.tistory.com/category/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D
'머신러닝' 카테고리의 글 목록
knowallworld.tistory.com
==> 기초통계와 머신러닝에 대해 공부하면서 분석을 진행하였다.
6. 외교부에서의 인턴 최종 후기
부서내 직원분들께서 잘 챙겨주시기도 하고, 밥도 자주사주시고, 회식도 있으면 같이 데리고 가주시고 했다.
업무상으로는 기술적인 부분에서는 내가 얻어낸 것은 없긴했다. 나 혼자 터득한 것일 뿐.. 근데 어느 회사를 가도 비슷할 수 도 있지 않을까 생각을 한다.
다만, 분석의 방향을 잡는데 도와주시기도 했고, 도움이 아예 안된건 아니다. 고려아연에서의 인턴경험으로 클라우드에 대해 관심이 생겼으나, 흥미는 없었다. 그러나 외교부는 달랐다.
외교부내 데이터로 분석을 하면서 나의 갖고 있는 생각을 남들에게 전달하는 점이 흥미로웠다. 이에 , 효율적이고 더욱더 효과적인 분석결과를 도출하기 위해서 대학원 준비(취준 병행)도 하기로 마음 먹었다.
내가 하고 싶은 일을 다소 늦다고 생각할 수 있는 나이에 찾았다. IT 전공자지만, IT 전공자라기엔 부족한 실력을 가졌다고 생각하는 나로써는 , 이제는 데이터 분석 분야에 몰입하는 길 밖에 없다고 생각한다.
6개월이라는 시간이 정말 빠르게 지나간다. 계획을 철저히 세우고 진행했다 생각했는데도 불구하고 아쉬움이 남는 6개월이 된거 같다. 다시 백수가 되겠지만, 이 경험이 헛되지 않도록 취준 다시 빠이팅 하려한다!!
------------ 1 편 ------------
https://knowallworld.tistory.com/404
[외교부 인턴-마지막날(총정리)]2022 공공빅데이터 분석 청년인재 양성 사업-후기_01
1. 외교부에서의 첫 날 나는 외교부 영사서비스과(통합전자행정시스템구축 T/F팀)에 배치 받았다. 정부서울청사의 경우 본관과 별관이 존재하는데, 별관에 주로 외교부의 많은 부서들이 존재한
knowallworld.tistory.com
========================================
2022 공공빅데이터 분석 청년인재 양성 사업
========================================
https://knowallworld.tistory.com/46
[2022 데이터분석 청년인재-01-후기] 서류 지원 및 면접 이후 합격까지
1. 서류 전형 5가지 질문 1) 해당 사업에 대한 지원동기. 2)분석을 통한 극복한 점. 3) 소속조직에서 친분형성 하면서 일을 처리한 경험 4) 정보수집으로 긍정적 성과 도출한 점 5) 교육에서 본인이
knowallworld.tistory.com
https://knowallworld.tistory.com/225
[2022 데이터분석 청년인재-02-후기] 5월 비대면 교육부터 8월 교육까지
1. 비대면 교육 1> 비대면 교육 사이트에서 5월 말부터~6월말(대면 교육) 까지 들어야 한다. 강의는 기초통계 , R , PYTHON , 빅데이터 관련 기초 강의들을 듣는다. ==> IT 전공자 입장에선 컴퓨터 언어
knowallworld.tistory.com
'인턴일지 > 외교부_일지' 카테고리의 다른 글
| [외교부 인턴-마지막날(총정리)]2022 데이터 분석 청년인재 양성 사업-후기_01 (0) | 2023.03.05 |
|---|---|
| [외교부 인턴 일지- d+140 2022.01.20]데이터 분석 청년인재 양성 사업 (1) | 2023.01.20 |
| [외교부 인턴 일지- d+139 2022.01.19]데이터 분석 청년인재 양성 사업 (0) | 2023.01.19 |
| [외교부 인턴 일지- d+128 2022.01.08]데이터 분석 청년인재 양성 사업 (0) | 2023.01.08 |
| [외교부 인턴 일지- d+115 2022.12.26]데이터 분석 청년인재 양성 사업 (0) | 2022.12.29 |
[외교부 인턴-마지막날(총정리)]2022 데이터 분석 청년인재 양성 사업-후기_01
1. 외교부에서의 첫 날
나는 외교부 영사서비스과(통합전자행정시스템구축 T/F팀)에 배치 받았다.
정부서울청사의 경우 본관과 별관이 존재하는데, 별관에 주로 외교부의 많은 부서들이 존재한다.
하지만 , 영사서비스과의 경우 정부서울청사 본관에 위치하였다.
정부서울청사 본관 : 네이버
블로그리뷰 34
m.place.naver.com
서울청사로 들어가기 위해서는 출입문을 통과해야 하는데, 출입증도 필요하고, 임시 출입증을 발급받은 뒤 본관 내부로 가기위해서는 공항에서나 보던 탐지기와 가방은
X-Ray 검사기를 통과시켜야만 출입이 가능하다.
본래 영사서비스과의 T.O는 2명이었으나 동기일수 있던 한분이 포기하면서 나는 동기없이 혼자 인턴 생활을 시작한다는 소식을 듣게 되었다.(아쉬웠다 ㅠ)
첫날 부내 직원분들께 인사를 하였고, 직급의 경우 행정관 , 사무관 , 서기관 등 이전에 다녔던 회사와의 직급체계가 다른점을 깨달았다.

2. 사무실 시설


영사서비스과 사무실은 가벽이 존재해서, 가벽내부에는 외교부 직원실, 가벽외부에는 외교부 아웃소싱 업체 직원실로 나누어져있었다.
나는 첫 두달간은 위 사진의 파티션이 있는 자리가 아닌 밖에 있는 자리에 있었다. 두달 이후에는 아웃소싱 업체의 인원충원에 의해 외교부 직원실 내부로 들어오게 되었고, 파티션이 있는 독립된 내 공간이 생겼다.
그리고 다과들이 존재해서 마음껏(?) 먹을 수 있는 복지를 누렸다.(ACE는 코딩하면서 먹으면 제일 맛있다.)
3. 정부서울청사 시설
정부서울청사의 시설의 경우 오래되어 낡았다.단느낌보단 중후한 느낌이라고 믿고싶다.
의외로 화장실(모든 칸에 비데가 있다!)과 사무실 내부는 깔끔했으며, 청소해주시는 직원분들이 계셔서 청결하였다.

엘리베이터도 15대 정도 있어서 금방금방 온다!
하지만 겨울에 이 건물이 지어진지 40년이 지난 건물임을 뼈저리게 느꼈다. 정부의 지침에 따라 청사 내부 온도를 17˚C로 유지한다는 것이었다!!!!(여름에도 17도는 춥다..)
너무 추웠다.. 패딩입고 장갑끼고 근무를 하였다...;;
아무튼, 여름은 안 겪어봐서 모르지만, 여름엔 덥고 겨울엔 추운 그런 곳이다.



정부서울청사의 경우 20층까지 존재하며, 20층에는 옥상정원이 존재한다!
옥상정원 외부 사진을 찍는것은 위법 사항이라 못 찍었지만, 광화문 뷰, 경복궁 뷰가 다 보인다!
1층에는 빵카페, 편의점, 우체국, NH농협은행이 있어서, 청사내에서 필요한건 다 해결 할 수 있었다.



그리고, 2층에는 구내식당!! 한끼에 4천원, 6천원 짜리 선택 할 수 있는데, 4천원의 경우 뷔페식 , 6천원의 경우 맛있는 메인 DISH가 존재하는 식단이었다.
석식도 있어서 5천원에 한끼 해결하고 운동가야 할때 먹곤 했다.
지내다보니 4천원짜리 뷔페식이 퇴근할때까지 든든해서 4천원짜리 식단을 주로 먹었다.
4. 주변 환경
주변 환경으로는 정말 서울에서 최고라고 생각이 들었다.
이전에 고려아연의 근무지는 논현역에 위치하였는데, 산책하기에는 정말 삭막한 곳이었다.



하지만 서울청사 근처에는 산책할 수 있는 곳이 정말 많았다. 덕수궁 돌담길, 청와대 둘레길, 대한축구협회쪽 산책길 등등.. 엄청 많았다!
주로 팀장님과 함께 점심 먹고 한바퀴 돌면서 스트레스를 날리곤 했다.




퇴근하면서 보는 광화문광장은 내 취업 동기부여에 계속 장작을 불어넣었다. 꼭 좋은 곳에 취업하고 싶다!
--2편에서 계속--
https://knowallworld.tistory.com/405
[외교부 인턴-마지막날(총정리)]2022 공공빅데이터 분석 청년인재 양성 사업-후기_02
4. 외교부에서의 업무 Start 외교부의 내부망 ID , PW 를 할당 받고 , 출입증 카드까지 받은 뒤에 본격적으로 외교부 업무를 시작하게 되었다.(10월경) 9월은 업무 적응 기간이 필요해 한달간은 업무
knowallworld.tistory.com
========================================
2022 공공빅데이터 분석 청년인재 양성 사업
========================================
https://knowallworld.tistory.com/46
[2022 데이터분석 청년인재-01-후기] 서류 지원 및 면접 이후 합격까지
1. 서류 전형 5가지 질문 1) 해당 사업에 대한 지원동기. 2)분석을 통한 극복한 점. 3) 소속조직에서 친분형성 하면서 일을 처리한 경험 4) 정보수집으로 긍정적 성과 도출한 점 5) 교육에서 본인이
knowallworld.tistory.com
https://knowallworld.tistory.com/225
[2022 데이터분석 청년인재-02-후기] 5월 비대면 교육부터 8월 교육까지
1. 비대면 교육 1> 비대면 교육 사이트에서 5월 말부터~6월말(대면 교육) 까지 들어야 한다. 강의는 기초통계 , R , PYTHON , 빅데이터 관련 기초 강의들을 듣는다. ==> IT 전공자 입장에선 컴퓨터 언어
knowallworld.tistory.com
'인턴일지 > 외교부_일지' 카테고리의 다른 글
| [외교부 인턴-마지막날(총정리)]2022 데이터 분석 청년인재 양성 사업-후기_02 (0) | 2023.03.05 |
|---|---|
| [외교부 인턴 일지- d+140 2022.01.20]데이터 분석 청년인재 양성 사업 (1) | 2023.01.20 |
| [외교부 인턴 일지- d+139 2022.01.19]데이터 분석 청년인재 양성 사업 (0) | 2023.01.19 |
| [외교부 인턴 일지- d+128 2022.01.08]데이터 분석 청년인재 양성 사업 (0) | 2023.01.08 |
| [외교부 인턴 일지- d+115 2022.12.26]데이터 분석 청년인재 양성 사업 (0) | 2022.12.29 |
[외교부 데이터 분석_지도 시각화]Python Mapboxgl 활용하기
1. MapBox 가입 및 토큰 갖고 오기
Maps, geocoding, and navigation APIs & SDKs | Mapbox
Integrate custom live maps, location search, and turn-by-turn navigation into any mobile or web app with Mapbox APIs & SDKs. Get started for free.
www.mapbox.com
==> 가입하기

==> 로그인 이후 Go to account 클릭

==> 토큰 Access code 복사하기

==> 프로젝트 폴더내에 config.py 생성 이후 token = 'Access code 첨부'
! pip install --trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pypi.org mapboxgl==> mapoxgl 패키지 설치
'데이터분석 > 외교부_데이터분석' 카테고리의 다른 글
| ★concat★insert★transpose()★[PYTHON] 외교부_데이터분석_프로세스-05 (0) | 2022.11.24 |
|---|---|
| ★정규식(re)★apply★lambda★[PYTHON] 외교부_데이터분석_프로세스-04 (0) | 2022.11.24 |
| ★merge★[PYTHON] 외교부_데이터분석_프로세스-03 (0) | 2022.11.24 |
| ★iloc★loc★rename★fillna★[PYTHON] 외교부_데이터분석_프로세스-02 (0) | 2022.11.23 |
| ★액셀_시트명 뽑아내기[PYTHON] 외교부_데이터분석_프로세스-01 (0) | 2022.11.23 |
[PYTHON - 머신러닝_캐글_실습-03]향후 판매량 예측 모델링 성능향상★np.vstack()★시차 피처★LightGBM★
1. 피처엔지니어링 1 : 개별 데이터 피처 엔지니어링
1> sales_train 이상치 제거 및 전처리
sales_train.head()==> sales_train의 판매가, 판매량 피처의 이상치를 제거한다.
==> 판매가, 판매량이 음수라면 환불 건이거나 오류이다. 이에 판매가, 판매량이 음수인 데이터는 이상치로 간주한다.
==> 판매가가 50,000이상인 데이터, 판매량이 1,000이상인 데이터도 이상치로 간주한다.
==> 결론적으로 0~ 50,000 사이이고, 판매량이 0 ~ 1,000 사이인 데이터만 추출한다.
# 판매가가 0 보다 큰 데이터 추출
sales_train = sales_train[sales_train['판매가'] >0]
# 판매가가 50000보다 작은 데이터 추출
sales_train = sales_train[sales_train['판매가']<50000]
# 판매량이 0보다 큰 데이터 추출
sales_train = sales_train[sales_train['판매량']> 0]
# 판매량이 1,000보다 작은 데이터 추출
sales_train = sales_train[sales_train['판매량']<1000]
2> shops 이상치 제거 및 전처리
shops.head()==> shops에도 상점명이 러시아어로 되어 있다.
==> 상점명의 첫 단어가 도시라는 사실이 있다.
==> 상점명을 이용해 도시 피처를 만들 수 있다.

shops['도시'] = shops['상점명'].apply(lambda x : x.split()[0])
shops['도시'].unique()
array(['!Якутск', 'Адыгея', 'Балашиха', 'Волжский', 'Вологда', 'Воронеж',
'Выездная', 'Жуковский', 'Интернет-магазин', 'Казань', 'Калуга',
'Коломна', 'Красноярск', 'Курск', 'Москва', 'Мытищи', 'Н.Новгород',
'Новосибирск', 'Омск', 'РостовНаДону', 'СПб', 'Самара',
==> 도시명은 범주형 피처이다. 머신러닝 모델은 문자를 인식하지 못하므로 숫자로 바꿔야 한다.
==> 레이블 인코딩을 적용한다.
https://knowallworld.tistory.com/384
[PYTHON - 머신러닝_캐글_데이터 인코딩]★LabelEncoder★One-Hot-Encoder
머신러닝 모델은 문자 데이터를 인식하지 못한다. 이를 문자로 구성된 범주형 데이터는 숫자로 바꿔야 한다. ==> 범주형 데이터를 숫자 형태로 바꾸는 작업을 데이터 인코딩이라고 한다. 1. 레이
knowallworld.tistory.com
==> 레이블 인코딩의 단점은 서로 가까운 숫자를 비슷한 데이터로 판단하여 성능을 떨어뜨릴 수 있다. 트리 기반 모델을 사용할 땐 레이블 인코딩을 해도 큰 지장이 없다.
==> 트리 기반 모델 특성상 분기를 반복하면서 피처 정보를 반영하므로 레이블 인코딩의 단점이 어느 정도 무마 된다.
from sklearn.preprocessing import LabelEncoder
# 레이블 인코더 생성
label_encoder = LabelEncoder()
# 도시 피처 레이블 인코딩
shops['도시'] = label_encoder.fit_transform(shops['도시'])# 상점명 피처를 활용해 도시 피처를 만들어 인코딩을 마쳤다. 이제 상점명 피처는 모델링에 더이상 필요가 없다.
shops = shops.drop('상점명' , axis = 1)
shops.head()
3> items 파생 피처 생성
#items를 활용하여 '첫 판매월' 피처를 구해본다.
# 상품명 피처 제거
items = items.drop(['상품명'], axis =1) # 상품명의 경우 상품ID와 일대일 매칭되어 있어서 제거해도 된다.# 상품이 맨 처음 팔린 날을 피처 추가
items['첫 판매월'] = sales_train.groupby('상품ID').agg({'월ID' : 'min'})['월ID']
items==> 상품 ID에 대해 GROUP화 한뒤 , 월ID의 최소값

items['첫 판매월'] = items['첫 판매월'].fillna(34)==> 훈련 데이터는 2013년 1월 부터 2015년 10월 까지의 판매 내역이다.
==> 월ID는 0부터 33이다.
==> 테스트 데이터는 2015년 11월 판매 내역이다. 월ID는 34이다.
==> 2013년 1월 부터 2015년 10월 까지 한 번도 팔리지 않은 상품이 있다면 그 상품이 처음 팔린 달을 2015년 11월이라고 가정해도 딘다.
==> 첫 판매월 피처의 결측값을 34로 대체 해도 된다.
==> 2015년 11월에도 안 팔릴 수 있다. 하지만 테스트 데이터에 없는 상품이면 아예 고려 대상이 되지 않는다.(테스트 데이터에도 없다는 말은 2015년 11월에도 안 팔렸다는 뜻이다.)
4> item_categories 파생 피처 생성 및 인코딩
==> item_cateories 에서 '대분류'라는 파생 피처를 만들고, 이를 인코딩해본다.
==> item_categories는 상품분류명을 담고 있다. 상품분류명의 첫 단어가 범주 대분류이다.
item_categories['대분류'] = item_categories['상품분류명'].apply(lambda x: x.split()[0])
item_categories['대분류'].value_counts()
def make_etc(x):
if len(item_categories[item_categories['대분류'] == x]) >= 5:
return x
else:
return 'etc'
# 대분류의 고윳값 개수가 5개 미만이면 'etc'로 바꾸기
item_categories['대분류'] = item_categories['대분류'].apply(make_etc)==> 대분류의 고윳값 개수가 5개 미만이면 'etc'로 바꾼다.
# 레이블 인코더 생성
label_encoder = LabelEncoder()
# 대분류 피처 레이블 인코딩
item_categories['대분류'] = label_encoder.fit_transform(item_categories['대분류'])
# 상품분류명 피처 제거
item_categories = item_categories.drop('상품분류명' , axis =1)
item_categories[item_categories['대분류'] == 'etc']| sales_train | 이상치 제거 , 상품ID 수정 |
| shops | 1. 상점명 피처를 활용해 도시 피처 새로 추가 2. 범주형 데이터인 도시 피처 인코딩 3. 상점명 피처 제거 |
| items | 1. 첫 판매월 피처 추가 2. 결측값을 34로 대체 |
| item_Categories | 1. 대분류 피처 추가 2. 고윳값 개수 5개 미만인 대분류 값을 'etc'로 변경 3. 대분류 피처 인코딩 |
2. 피처엔지니어링 2 : 데이터 조합 및 파생 피처 생성
1> 데이터 조합
# 데이터 조합
from itertools import product
train = []
# 월 ID, 상점 ID , 상품 ID 조합 생성
for i in sales_train['월ID'].unique():
all_shop = sales_train.loc[sales_train['월ID'] ==i, '상점ID'].unique()
all_item = sales_train.loc[sales_train['월ID']==i, '상품ID'].unique()
train.append(np.array(list(product([i] , all_shop, all_item))))
idx_features = ['월ID' , '상점ID' , '상품ID'] # 기준 피처
train = pd.DataFrame(np.vstack(train) , columns=idx_features)
train==> np.vstack() ==> 수직행렬 생성

# 파생 피처 생성
group = sales_train.groupby(idx_features).agg({'판매량' : 'sum', '판매가' : 'mean'})
group = group.reset_index()
group = group.rename(columns = {'판매량' : '월간 판매량' , '판매가' : '평균 판매가'})
train = train.merge(group , on = idx_features , how= 'left')
train.head()==> 결측값이 있다는 것은 판매량과 판매가가 0이라는 뜻이다.

# 상품 판매건수 피처 추가
group = sales_train.groupby(idx_features).agg({'판매량' : 'count'})
group = group.reset_index()
group = group.rename(columns = {'판매량' : '판매건수'})
group.head()
train = train.merge(group , on=idx_features , how = 'left')
# 가비지 컬렉션
del group, sales_train
gc.collect()
train.head()
3. 피처엔지니어링 3 : 데이터 합치기
# 테스트 데이터 월ID를 34로 설정
test['월ID'] = 34
# train과 test 이어 붙이기
all_data = pd.concat([train , test.drop('ID' , axis =1)],
ignore_index= True,
keys= idx_features)
# 결측값을 0으로 대체
all_data = all_data.fillna(0)
all_data.head()
# train에 test를 이어붙여 all_data를 만들었다.==> train, test 데이터프레임 이어 붙이기
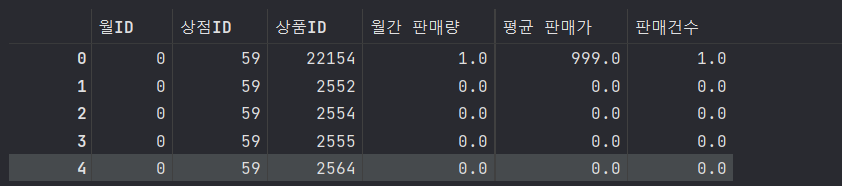
# 나머지 데이터 병합
all_data = all_data.merge(shops, on ='상점ID' , how = 'left')
all_data = all_data.merge(items, on ='상품ID' , how = 'left')
all_data = all_data.merge(item_categories , on='상품분류ID' , how ='left')
# 데이터 다운캐스팅
all_data = downcast(all_data)# 가비지 컬렉션
del shops, items, item_categories
gc.collect()==> shops , items , item_categories 는 all_data에 병합하였으므로 더이상 필요없다.
4. 피처엔지니어링 4 : 시차 피처 생성
==> 시차 피처란 과거 시점에 관한 피처로 , 성능 향상에 도움되는 경우가 많아서 시계열 문제에서 자주 만드는 파생 피처이다.
==> 시차 피처를 만들기 위해선 기준으로 삼을 피처를 먼저 정해야 한다.
==> 타깃값과 관련된 '월간 평균 판매량'이 좋다.
==> 기준 피처별 월간 평균 판매량 피처를 만들어야 한다.
# 기준 피처별 월간 판매량 파생 피처 생성
# 파라미터
# df : DataFrame , mean_features : 새로 만든 월간 평균 판매량 파생 피처명을 저장하는 리스트 , idx_features : 기준 피처
# 기준 피처의 첫 번째 요소는 반드시 '월ID'여야 한다. '월간' 평균 판매량 파생 피처를 만들 것이다.
def add_mean_features(df , mean_features , idx_features):
# 기준 피처 확인
assert (idx_features[0] == '월ID') and \
len(idx_features) in [2,3]
# 기준 피처의 첫 번째 요소가 '월ID'가 맞는지 , 기준 피처 개수가 2개 혹은 3개인지 확인한다. 아닐경우 오류를 발생시킨다.
# 파생 피처명 설정
if len(idx_features) ==2 : # 기준 피처가 2개일 때와 3개일 때로 나누어 설정한다.
feature_name = idx_features[1] + '별 평균 판매량'
else:
feature_name = idx_features[1] + ' ' + idx_features[2] + '별 평균 판매량'
# 기준 피처를 토대로 그룹화해 월간 평균 판매량 구하기
group = df.groupby(idx_features).agg({'월간 판매량' : 'mean'})
group = group.reset_index()
group = group.rename(columns = {'월간 판매량' : feature_name})
# df와 group 병합
df = df.merge(group , on=idx_features , how='left')
# 데이터 다운캐스팅
df = downcast(df, verbose=False)
# verbose = False 를 하면 몇 %를 압축했습니다. 문구가 뜨지 않는다.
# 새로 만든 feature_name 피처명을 mean_features 리스트에 추가
mean_features.append(feature_name)
# 가비지 컬렉션
del group
gc.collect()
return df,mean_features1. assert (idx_features[0] == '월ID') and len(idx_features) in [2,3]
==> 기준 피처의 첫 번째 요소가 '월ID'가 맞는지 , 기준 피처 개수가 2개 혹은 3개인지 확인한다. 아닐경우 오류를 발생시킨다.
2. if len(idx_features) ==2 :
feature_name = idx_features[1] + '별 평균 판매량'
else:
feature_name = idx_features[1] + ' ' + idx_features[2] + '별 평균 판매량'
==> 기준 피처가 2개일 때와 3개일 때로 나누어 설정한다.
3. group = df.groupby(idx_features).agg({'월간 판매량' : 'mean'})
group = group.reset_index()
group = group.rename(columns = {'월간 판매량' : feature_name})
==> 기준 피처를 토대로 그룹화해 월간 평균 판매량 구하기
4. df = df.merge(group , on=idx_features , how='left')
==> df와 group 병합
5. df = downcast(df, verbose=False)
==> 데이터 다운캐스팅
==> verbose = False 를 하면 몇 %를 압축했습니다. 문구가 뜨지 않는다.
6. mean_features.append(feature_name)
==> 새로 만든 feature_name 피처명을 mean_features 리스트에 추가
# 그룹화 기준 피처 중 '상품ID'가 포함된 파생 피처명을 담을 리스트
item_mean_features = []
# ['월ID' , '상품ID'] 로 그룹화한 월간 평균 판매량 파생 피처 생성
all_data , item_mean_features = add_mean_features(df = all_data,
mean_features=item_mean_features,
idx_features=['월ID' , '상품ID'])
# ['월ID' , '상품ID', '도시']로 그룹화한 월간 평균 판매량 파생 피처 생성
all_data , item_mean_features = add_mean_features(df = all_data ,
mean_features= item_mean_features,
idx_features=['월ID' , '상품ID' ,'도시'])
all_data.head()
# 그룹화 기준 피처 중 '상점ID'가 포함된 파생 피처명을 담을 리스트
shop_mean_features = []
# ['월ID' , '상점ID' , '상품분류ID'] 로 그룹화한 월간 평균 판매량 파생 피처 생성
all_data , shop_mean_features = add_mean_features(df = all_data,
mean_features= shop_mean_features,
idx_features=['월ID' , '상점ID', '상품분류ID'])
# 상점ID를 포함한 파생 피처명은 shop_mean_features 리스트에 따로 담았다.
# 상품ID를 포함한 파생 피처명은 item_mean_features 리스트에 담았다.all_data.head()
5. 시차 피처 생성 원리 및 함수 구현
==> 기준 피처별 월간 평균 판매량 피처는
1. 상품ID별 평균 판매량
2. 상품ID + 도시 별 평균판매량
3. 상점ID + 상품분류ID 별 평균 판매량
==> 시차 피처는 현시점 데이터에 과거 시점 데이터를 추가한다는 개념이다. 과거 시점 데이터는 향후 판매량 예측에 유용하기 때문에 사용한다.
def add_lag_features(df , lag_features_to_clip , idx_features , lag_feature , nlags = 3 , clip = False):
# 시차 피처 생성에 필요한 DataFrame 부분만 복사
df_temp = df[idx_features + [lag_feature].copy()]
# 시차 피처 생성
for i in range(1, nlags+1):
# 시차 피처명
lag_feature_name = lag_feature +'_시차' + str(i)
# df_temp 열 이름 설정
df_temp.columns = idx_features + [lag_feature_name]
# df_temp의 date_block_num 피처에 1 더하기
df_temp['월ID'] +=1
# idx_feature를 기준으로 df와 df_temp 병합하기
df = df.merge(df_temp.drop_duplicates(),
on = idx_features,
how = 'left')
# 결측값 0으로 대체
df[lag_feature_name] = df[lag_feature_name].fillna(0)
# 0~20 사이로 제한할 시차 피처명을 lag_features_to_clip에 추가
if clip:
lag_features_to_clip.append(lag_feature_name)
# 데이터 다운캐스팅
df = downcast(df, False)
# 가비지 컬렉션
del df_temp
gc.collect()
return df,lag_features_to_clip
1. df_temp = df[idx_features + [lag_feature].copy()]
==> 시차 피처 생성에 필요한 DataFrame 부분만 복사
==> 기준 피처인 idx_features와 시차 적용 피처인 lag_feature만 추출
==> idx_features는 리스트 타입이고, lag_feature는 문자열 타입이다. 리스트와 문자열은 바로 합칠 수 없다. 따라서, idx + [lag_feature]와 같이 합쳤다.
2. for i in range(1, nlags+1): ==> nlags의 인수의 값만큼 for문을 돌며 시차 피처 생성
3. lag_feature_name = lag_feature +'_시차' + str(i)
==> 새로 만들 시차 피처명
4. df_temp.columns = idx_features + [lag_feature_name]
==> df_temp 열 이름 설정
5. df_temp['월ID'] +=1
==> df_temp의 월ID 피처에 1 더하기
==> 시차 피처를 만드는 핵심 역할로서, 나머지 피처값은 그대로지만 월ID이 한 달씩 밀렸다.
==> 한 달 씩 밀려야 두달 전 세 달 전 피처까지 만들게 된다.
6. df = df.merge(df_temp.drop_duplicates(),
on = idx_features,
how = 'left')
==> idx_feature를 기준으로 df와 df_temp 병합하기
==> 한 달 전 시차 피처들을 만들 수 있다.
7.df[lag_feature_name] = df[lag_feature_name].fillna(0)
==> 병합할 때 매달 데이터가 있는 것이 아니므로 한 달 전 피처가 없을 수 있다. 이런 경우 시차 피처에 결측값이 생긴다. 결측값 0으로 대체
8.if clip:
lag_features_to_clip.append(lag_feature_name)
==> 0~20 사이로 제한할 시차 피처명을 lag_features_to_clip에 추가
6. 시차 피처 생성1 : 월간 판매량
# 기준피처는 '월ID' , '상점ID' , '상품ID'로 하여 월간 판매량의 세 달치 시차 피처를 만들어본다.
# clip = True를 전달해 세 달치 시차 피처를 lag_features_to_clip 리스트에 저장해둔다.
# 월간 판매량은 타깃값이므로 0~20 사이로 제한해야 한다.
lag_features_to_clip = [] # 0~20 사이로 제한할 시차 피처명을 담을 리스트
idx_features = ['월ID' , '상점ID' , '상품ID'] # 기준 피처
# idx_features 를 기준으로 월간 판매량의 세달치 시차 피처 생성
all_data, lag_features_to_clip = add_lag_features(df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features=idx_features,
lag_feature='월간 판매량',
nlags= 3,
clip = True) # 값을 0~20 사이로 제한
all_data.head().T
==> 월간 판매량_시차1 , 월간 판매량_시차2 , 월간 판매량_시차3 피처가 잘 만들어졌다.
==> nlags =3 이니 시차 피처를 3개 만든 것이다.
7. 시차 피처 생성2 : 판매건수, 평균 판매가
==> 판매 건수와 평균 판매가는 타깃값이 아니므로 0~20 사이로 제한할 필요가 없다.
==> clip 파라미터는 생략해도 된다.
# idx_features를 기준으로 판매건수 피처의 세 달치 시차 피처 생성
all_data, lag_features_to_clip = add_lag_features(df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features=idx_features,
lag_feature='판매건수',
nlags= 3)
# idx_features를 기준으로 평균 판매가 피처의 세 달치 시차 피처 생성
all_data, lag_features_to_clip = add_lag_features(df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features=idx_features,
lag_feature='평균 판매가',
nlags= 3)8. 시차 피처 생성3 : 평균 판매량
==> item_mean_features와 shop_mean_features 에 평균 판매량 피처를 저장했다.
==> item_mean_features에는 상품ID별 평균 판매량과 상품ID 도시별 평균 판매량이 저장돼 있다.
==> 두 피처값에 대한 시차 피처를 생성하여 item_mean_features를 순회하며 시차 피처를 생성한다.
==> 월ID , 상점ID , 상품ID를 기준으로 상품ID별 평균 판매량과 상품ID 도시별 평균 판매량의 시차피처를 생성한다.
# idx_features를 기준으로 item_mean_Features 요소별 시차 피처 생성
for item_mean_features in item_mean_features:
all_data, lag_features_to_clip = add_lag_features(df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features=idx_features,
lag_feature=item_mean_features,
nlags= 3,
clip = True) # 값을 0~20 사이로 제한
# item_mean_features 피처 제거
all_data = all_data.drop(item_mean_features, axis =1 )
all_data
#['월ID' , '상점ID' , '상품분류ID']를 기준으로
# shop_mean_features 요소별 시차 피처 생성
for shop_mean_feature in shop_mean_features:
all_data, lag_features_to_clip = add_lag_features(df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features=['월ID' , '상점ID' , '상품분류ID'],
lag_feature=shop_mean_feature,
nlags= 3,
clip = True) # 값을 0~20 사이로 제한
all_data = all_data.drop(shop_mean_features, axis =1 )
all_data
## 시차 피처 생성 마무리 : 결측값 처리
# 월ID가 3 미만인 데이터 제거
all_data = all_data.drop(all_data[all_data['월ID'] < 3].index)
all_data==> 모두 3 달치를 생성하였다. 월 ID 0,1,2인 데이터에는 결측값이 생긴다.
9. 피처엔지니어링 5: 기타 피처 엔지니어링
1> 월간 판매량 시차 피처들의 평균
## 피처 엔지니어링 7 : 기타 피처 엔지니어링
# 기타 피처
# 월간 판매량 시차 피처들의 평균
all_data['월간 판매량 시차평균'] = all_data[['월간 판매량_시차1',
'월간 판매량_시차2',
'월간 판매량_시차3']].mean(axis=1)
#0~20 사이로 값 제한
all_data[lag_features_to_clip + ['월간 판매량' , '월간 판매량 시차평균']] = \
all_data[lag_features_to_clip + ['월간 판매량' , '월간 판매량 시차평균']].clip(0,20)
all_data

==> add_lag_features() 함수에서 값을 조정할 피처들을 lag_features_to_clip 리스트에 저장해두었다.
==> 이 리스트에 더해 타깃값인 월간 판매량과 월간 판매량 시차평균 피처를 0~20으로 조정한다.
2> 시차 변화량
all_data['시차변화량1'] = all_data['월간 판매량_시차1'] / all_data['월간 판매량_시차2']
all_data['시차변화량1'] = all_data['시차변화량1'].replace([np.inf , -np.inf] , np.nan).fillna(0)
all_data['시차변화량2'] = all_data['월간 판매량_시차2'] / all_data['월간 판매량_시차3']
all_data['시차변화량2'] = all_data['시차변화량2'].replace([np.inf , -np.inf] , np.nan).fillna(0) # 무한대와 무한소를 np.nan으로 대체한 후 NaN을 0으로 대체
all_data.head()
all_data['시차변화량2'] = all_data['시차변화량2'].replace([np.inf , -np.inf] , np.nan).fillna(0)
==> 무한대와 무한소를 np.nan으로 대체한 후 NaN을 0으로 대체
3> 신상 여부
all_data['신상여부'] = all_data['첫 판매월'] == all_data['월ID']
# 첫 판매월과 월 ID가 같으면 True , 다르면 False를 신상여부 피처에 추가한다.==-> 첫 판매월이 현재 월과 같다면 신상품일 것이다.
4> 첫 판매 후 경과 기간
# 현재 월에서 첫 판매월을 빼면 첫 판매 후 기간이 얼마나 지났는지 알 수 있다. 이를 첫 판매 후 기간 피처라고 한다.
all_data['첫 판매 후 기간'] = all_data['월ID'] - all_data['첫 판매월']
all_data['월'] = all_data['월ID'] %125> 필요없는 피처 제거
# 지금까지 만든 피처 중 첫 판매월 , 평균 판매가, 판매건수는 모델링에 필요가 없다. 이 피처들을 활용해 다른 파생 피처를 만들었다.
# 첫 판매월은 신상여부, 첫 판매 후 기간 피처를 구하는데 쓰였고, 평균 판매가와 판매건수는 테스트 데이터에서 모두 0이다. 이 세 피처는 제거한다.
# 첫 판매월, 평균 판매가, 판매건수 피처 제거
all_data = all_data.drop(['첫 판매월' , '평균 판매가' , '판매건수'] , axis = 1)
# 다운 캐스팅을 하여 메모리를 아낀다.
all_data = downcast(all_data, False)10. 모델 훈련 및 성능 검증
# 훈련 데이터 (피처)
X_train = all_data[all_data['월ID'] < 33]
X_train = X_train.drop(['월간 판매량'] , axis =1)
# 검증 데이터 (피처)
X_valid = all_data[all_data['월ID'] ==33]
X_valid = X_valid.drop(['월간 판매량'] , axis =1)
# 테스트 데이터 (피처)
X_test = all_data[all_data['월ID'] ==34]
X_test = X_test.drop(['월간 판매량'], axis =1)
# 훈련 데이터 (타깃값)
y_train = all_data[all_data['월ID'] <33]['월간 판매량']
# 검증 데이터 (타깃값)
y_valid = all_data[all_data['월ID'] ==33]['월간 판매량']
# 가비지 컬렉션
del all_data
gc.collect()==> 피처 엔지니어링을 적용해 총 30개 피처를 손에 넣었다. 이 데이터로 모델을 훈련하고 예측할 수 있다.
https://knowallworld.tistory.com/401
[PYTHON - 머신러닝_캐글_실습-02]향후 판매량 예측★데이터 다운캐스팅★memory_usage()★to_numeric()★
1. 피처엔지니어링 1 : 피처명 한글화 sales_train = sales_train.rename(columns = {'date' : '날짜' , 'date_block_num' : '월ID', 'shop_id' : '상점ID', 'item_id' : '상품ID', 'item_price' : '판매가', 'item_cnt_day' : '판매량'}) sales_tr
knowallworld.tistory.com
==> 범주형 데이터에는 상점ID와 상품분류ID 외에 도시, 대분류, 월을 추가했다.
import lightgbm as lgb
# LightGBM 하이퍼파라미터
params = {'metric' : 'rmse',
'num_leaves' : 255,
'learning_rate': 0.005,
'feature_fraction' : 0.75,
'bagging_fraction' : 0.75,
'bagging_freq' : 5,
'force_col_wise' : True,
'random_state' : 10}
cat_features = ['상점ID' , '도시' , '상품분류ID' , '대분류' , '월']
# LightGBM 훈련 및 검증 데이터셋
dtrain = lgb.Dataset(X_train , y_train)
dvalid = lgb.Dataset(X_valid , y_valid)
# LightGBM 모델 훈련
lgb_model = lgb.train(params = params,
train_set = dtrain,
num_boost_round= 1500,
valid_sets=(dtrain, dvalid),
early_stopping_rounds=150,
categorical_feature= cat_features,
verbose_eval= 100)==> early_stopping_rounds ==> 조기 종료 조건 150번

