[PYTHON - 머신러닝_캐글_실습-01]향후 판매량 예측★groupby★boxplot★merge
https://www.kaggle.com/competitions/competitive-data-science-predict-future-sales/data
Predict Future Sales | Kaggle
www.kaggle.com
1. 향후 판매량 예측
==> 2013년 1월 부터 2015년 10월까지 판매 데이터를 기반으로 2015년 11월 판매량 예측
독립변수(피처) : 상점 및 상품에 관한 정보
종속변수(타깃값) : 월간 판매량
==> 월간 판매량은 0~20개 사이여야 한다. ==> 판매량이 20개보다 많으면 20개로 간주한다는 뜻이다.
2. 탐색적 데이터 분석
1> sales_train 데이터
sales_train.head()
==> date 피처는 날짜를 의미
==> date_block_num 피처는 편의상 상용하는 날짜(월) 구분자, 0은 2013년 2월, 1은 2013년 3월
==> item_cnt_Day 피처는 당일 판매량을 나타낸다.
==> 각 상점의 상품별 일일 판매량을 월별로 합친 값이 곧 각 상점의 상품별 월간 판매량이다.
==> date_block_num 피처를 기준으로 그룹화해서 item_cnt_day 값을 합하면 타깃값(월간 판매량)이 된다.
sales_train.info(show_counts = True) # show_counts 는 비결측값 개수 표시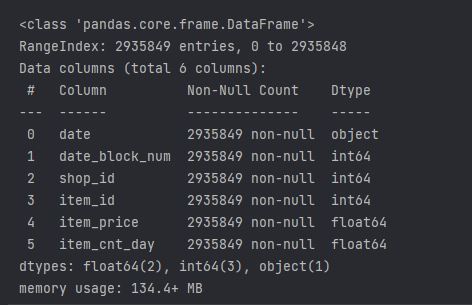
==> 메모리 사용량이 134.4MB
==> 제공한 데이터는 시계열 데이터이다.
==> 시계열 데이터는 시간 흐름이 중요하다.
==> 2013년 1월부터 2015년 9월까지 판매 내역을 훈련 데이터로 사용하고,
==> 2015년 10월 판매 내역을 검증 데이터로 사용한다.
==> 앞 장에서는 여러 폴드로 나눠 훈련 데이터와 검증 데이터를 지정했다.(oof 예측) 하지만 시계열 데이터는 이러면 과거와 미래가 섞이기 때문에 이용할 수 없다.
※ OOF(Out of Fold Prediction) 방식
==> K 폴드 교차 검증을 수행하면서 각 폴드마다 테스트 데이터로 예측하는 방식이다.
==> K 폴드 교차 검증을 하면서 폴드마다
1) 훈련 데이터로 모델을 훈련하고,
2)검증 데이터로 모델 성능을 측정하며 ,
3) 테스트 데이터로 최종 타깃 확률도 예측한다. 훈련된 모델로 마지막에 한 번만 예측하는 것이 아니다. 각 폴드별 모델로 여러번 예측해 평균을 내는 방식이다.
2> shops 데이터

==> shop_name 피처의 값들의 맨 앞 단어들이 도시 이름이다.
==> shop_id 의 경우 sales_train에도 있던 피처이므로 병합이 가능하다.
3> items 데이터

==> 상품명에서는 유용한 정보를 얻기 힘들어, 모델링 할 땐 제거한다.
==> item_id 피처는 sales_train 데이터에도 존재하는 피처이므로, item_id 피처를 기준으로 sales_train과 items를 병합할 수 있다.
4> item_categories 데이터
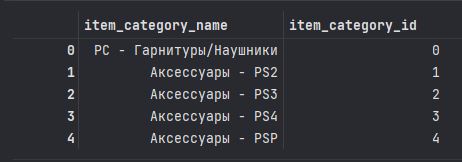
==> 상품분류명과 상품분류 ID로 구성되어 있다.
5> test 데이터

==> 테스트 데이터 식별자인 ID와 상점 ID , 상품ID로 구성돼 있다.
여기서 각 상점의 상품별 월간 판매량을 예측해야한다.
3. 데이터 병합
train = sales_train.merge(shops , on = 'shop_id' , how ='left')
train = train.merge(items , on = 'item_id' , how = 'left')
train = train.merge(item_categories , on = 'item_category_id' , how = 'left')
train
요약표
def resumetable(df):
print(f'데이터셋 형상 : {df.shape}')
summary = pd.DataFrame(df.dtypes , columns = ['데이터타입'])
summary = summary.reset_index()
summary = summary.rename(columns= {'index' : '피처'})
summary['결측값 개수'] = df.isnull().sum().values # 결측값의 개수 세기
summary['고윳값 개수'] = df.nunique().values # 고윳값의 개수 ㅅ기
summary['첫 번째 값'] = df.loc[0].values
summary['두 번째 값'] = df.loc[1].values
return summary
resumetable(train)
==> shop_id , shop_name ==> 개수 동일
==> item_category_id , item_category_name ==> 개수 동일
==> id와 name은 일대일로 매칭된다는 뜻이다.
4. 데이터 시각화
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
sns.boxplot(y='item_cnt_day' , data = train)
# 이상치가 많아 모양이 납작해졌다. 과한 이상치는 제거해야 한다.
==> 이상치 범위가 과도하게 넓어서 납작해보인다.
1> 그룹화
# 그룹화는 회귀 문제에서 자주 쓰인다. groupby() 함수
group = train.groupby('date_block_num').agg({'item_cnt_day' : 'sum'})
# date_block_num 피처를 기준으로 그룹화해 item_cnt_day 피처의 합(sum)을 구하는 코드이다.
# 월별(date_block_num) 월간 판매량(item_cnt_day)의 합을 구한다는 말이다.
group.reset_index()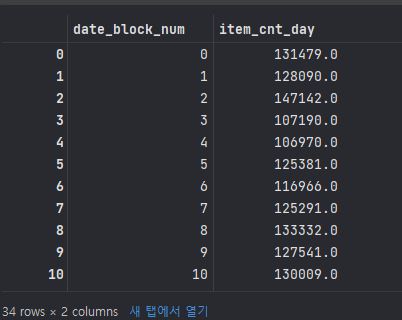
groupby 원리
1. DataFrame에 있는 한 개 이상의 피처를 기준으로 데이터를 분리한다.
2. 분리된 각 그룹에 함수를 적용해 집계값을 구한다.(agg() 메서드로 item_cnt_day 피처에 'sum'함수를 적용해 판매량 합계를 구한다.
3. 기준 피처별로 집계값 결과를 하나로 결합한다.
# sum , mean ,median ,std ,var , count , min , max
mpl.rc('font' , size = 13)
figure , ax = plt.subplots()
figure.set_size_inches(11,5)
# 월별 총 상품 판매량
group_month_sum = train.groupby('date_block_num').agg({'item_cnt_day' : 'sum'})
group_month_sum = group_month_sum.reset_index()
# 월별 총 상품 판매량 막대 그래프
sns.barplot(x = 'date_block_num' , y ='item_cnt_day' , data = group_month_sum)
# 그래프 제목 , x축 라벨, y축 라벨명 설정
ax.set(title = 'Distribution of monthly item counts by date block number' ,
xlabel = 'Date block number' ,
ylabel = 'Monthly item counts')
figure, ax = plt.subplots()
figure.set_size_inches(11,5)
# 상품분류별 총 상품 판매량
group_cat_sum = train.groupby('item_category_id').agg({'item_cnt_day' : 'sum'})
group_cat_sum = group_cat_sum.reset_index()
# 월간 판매량이 10,000개를 초과하는 상품분류만 추출
group_cat_sum = group_cat_sum[group_cat_sum['item_cnt_day'] > 10000]
# 상품분류별 총 상품 판매량 막대 그래프
sns.barplot(x = 'item_category_id' , y = 'item_cnt_day' , data = group_cat_sum)
ax.set(title = 'Distribution of total item counts by item category id' ,
xlabel = 'Date block number',
ylabel = 'Total item counts')
ax.tick_params(axis = 'x' , labelrotation = 90) # x축 라벨 회전
figure , ax = plt.subplots()
figure.set_size_inches(11,5)
# 상점별 총 상품 판매량
group_shop_sum = train.groupby('shop_id').agg({'item_cnt_day' : 'sum'})
group_shop_sum = group_shop_sum.reset_index()
group_shop_sum = group_shop_sum[group_shop_sum['item_cnt_day'] > 10000]
# 상점별 총 상품 판매량 막대 그래프
sns.barplot(x = 'shop_id' , y= 'item_cnt_day' , data = group_shop_sum)
ax.set(title = 'Distribution of total item counts by shop id',
xlabel = 'Date block number',
ylabel = 'Total item counts')
ax.tick_params(axis = 'x' , labelrotation =90)