[PYTHON - 머신러닝_캐글_실습-02]안전 운전자 예측 모델링★베이지안 최적화★LightGBM★K-폴드 교차검증
1. 베이스라인 모델
1) 데이터 불러오기
2) 피처 엔지니어링
--> 명목형 피처 원-핫 인코딩
--> 필요 없는 피처 제거
3) 평가지표 계산 함수 작성
--> 정규화 지니계수
4) 모델 훈련
--> 모델 : LightGBM
--> 훈련 / 검증 : Out of Fold (OOF)
--> 성능 검증
2. 피처 엔지니어링
all_data = pd.concat([train , test] , ignore_index= True)
all_data = all_data.drop('target' , axis = 1) # 타깃값 제거
all_data==> 훈련 데이터와 테스트 데이터의 합치기
==> 두 데이터에 동일한 인코딩 적용하기 위해
3. 명목형 피처 ONE-HOT 인코딩
from sklearn.preprocessing import OneHotEncoder
# 명목형 피처 추출
cat_features = [feature for feature in all_features if 'cat' in feature]
# 이름에 cat이 포함된 피처가 명목형 피처이다.
onehot_encoder = OneHotEncoder() # 원-핫 인코더 객체 생성
# 인코딩
encoded_cat_matrix = onehot_encoder.fit_transform(all_data[cat_features])
encoded_cat_matrix==> 이름에 cat이 포함된 피처가 명목형 피처이다.
from scipy import sparse
all_data_sprs = sparse.hstack([sparse.csr_matrix(all_data[remaining_features]) , encoded_cat_matrix] , format= 'csr')
all_data_sprs==> 명목형 피처에서 제거하고 남은 열에 대하여 csr_matrix()로 CSR 처리 이후 hstack()으로 행렬을 수평 방향으로 합친다.
num_train = len(train) # 훈련 데이터 개수
# 훈련 데이터와 테스트 데이터 나누기
X = all_data_sprs[:num_train]
X_test = all_data_sprs[num_train :]
y = train['target'].values==> 전체 데이터를 훈련 데이터와 테스트 데이터로 나눈다.
==> 타깃값 y에 할당한다.
1> LightGBM 용 gini() 함수
def gini(preds , dtrain):
labels = dtrain.get_label()
return 'gini' , eval_gini(labels , preds ) , True
# 'gini' : 평가지표이름 , eval_gini(labels,preds) : 평가점수 , True : 평가 점수가 높을수록 좋은지 여부4. 모델 훈련 및 성능 검증
https://knowallworld.tistory.com/386
[PYTHON - 머신러닝_캐글_교차검증]★K-폴드 교차검증★충화 K-폴드 교차검증★folds.split(data)★
1. 교차검증 ==> 일반적으로 훈련 데이터로 모델을 훈련하고, 테스트 데이터로 예측해 모델 성능을 측정한다. ==> 모델을 훈련만 하고, 성능을 검증해 보지 않으면 2가지 문제 발생 ㉠ 모델이 과대
knowallworld.tistory.com
==> K폴드 교차 검증
1> OOF(Out of Fold prediction) 예측 방식
==> K 폴드 교차 검증을 수행하면서 각 폴드마다 테스트 데이터로 예측하는 방식이다.
==> K 폴드 교차 검증을 하면서 폴드마다
1) 훈련 데이터로 모델을 훈련하고,
2)검증 데이터로 모델 성능을 측정하며 ,
3) 테스트 데이터로 최종 타깃 확률도 예측한다. 훈련된 모델로 마지막에 한 번만 예측하는 것이 아니다. 각 폴드별 모델로 여러번 예측해 평균을 내는 방식이다.
2> OOF(Out of Fold prediction) 예측 절차
1) 전체 훈련 데이터를 K개 그룹으로 나눈다.
2) K개 그룹 중 한 그룹은 검증 데이터, 나머지 K-1 그룹은 훈련 데이터로 지정한다.
3) 훈련 데이터로 모델을 훈련한다.
4) 훈련된 모델을 이용해 검증 데이터로 타깃 확률을 예측하고, 전체 테스트 데이터로도 타깃값 확률을 예측한다.
5) 검증 데이터로 구한 예측 확률과 테스트 데이터로 구한 예측 확률을 기록한다.
6) 검증 데이터를 다른 그룹으로 바꿔가며 2~5번 절차를 K번 반복한다.
7) K개 그룹의 검증 데이터로 예측한 확률을 훈련 데이터 실제 타깃값과 비교해 성능 평가점수를 계산한다.
8) 테스트 데이터로 구한 K개 예측 확률의 평균을 구한다.
3> OOF(Out of Fold prediction) 방식으로 LightGBM 훈련
==> 타깃값이 불균형하므로, K폴드가 아닌 층화 K폴드를 수행한다.
# OOF 방식으로 LightGBM 훈련
from sklearn.model_selection import StratifiedKFold
# 층화 K 폴드 교차 검증기
folds = StratifiedKFold(n_splits= 5 , shuffle= True , random_state= 1991)==> n_splits 파라미터로 전달한 수만큼 폴드를 나눈다. 여기서는 5개로 나누었다. shuffle = True 를 전달하면 폴드를 나눌때 데이터를 섞어준다.
params = {'objective' : 'binary' , 'learning_rate' : 0.01 , 'force_row_wise' : True , 'random_state' : 0}==> LightGBM의 하이퍼파라미터 설정
== > 이진분류 문제이므로 objective 파라미터는 binary로 설정했다. 학습률은 0.01로, 랜덤 스테이트 값은 9으로 설정했다. force_row_wise : True 는 경고 문구를 없애려고 추가한 파라미터이다.
# OOF 방식으로 훈련된 모델로 검증 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_val_preds = np.zeros(X.shape[0])
# ==> oof_val_preds 는 검증 데이터를 활용해 예측한 확률값을 저장하는 배열이다. K 폴드로 나누어도 훈련 데이터 전체가 결국엔 한 번씩 검증 데이터로 활용된다. 따라서 oof_val_preds 배열 크기는 훈련 데이터와 같아야 한다.
# 훈련 데이터 개수는 X.shpae[0]으로 구한다.
# OOF 방식으로 훈련된 모델로 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_test_preds = np.zeros(X_test.shape[0])
# oof_test_preds는 테스트 데이터를 활용해 예측한 확률값을 저장하는 배열이다. 최종 제출에 사용할 값이므로 크기는 테스트 데이터와 같아야한다. 테스트 데이터 개수는 X_test.shape[0]으로 구한다.
oof_val_preds = np.zeros(X.shape[0])
==> OOF 방식으로 훈련된 모델로 검증 데이터 타깃값을 예측한 확률을 담을 1차원 배열
==> 훈련 데이터 개수로 채워진 0
oof_test_preds = np.zeros(X_test.shape[0])
==> OOF 방식으로 훈련된 모델로 테스트 데이터 타깃값을 예측한 확률을 담을 1차원 배열
5. LightGBM 모델 검증
1) folds = StratifiedKFold(n_splits= 5 , shuffle= True , random_state= 1991)
print(i for i in folds.split(X,y))
for idx, (train_idx , valid_idx) in enumerate(folds.split(X, y)): # 훈련 데이터 , 타깃 데이터
print(f'idx : {idx}')
print(f'train_idx : {train_idx}')
print(f'valid_idx : {valid_idx}')idx : 0
train_idx : [ 0 1 3 ... 595209 595210 595211]
valid_idx : [ 2 5 15 ... 595181 595188 595190]
idx : 1
train_idx : [ 0 1 2 ... 595207 595209 595211]
valid_idx : [ 8 10 25 ... 595201 595208 595210]
2) 훈련용, 검증용 데이터 설정 , LightGBM 전용 데이터셋 생성
# 훈련용 데이터, 검증용 데이터 설정
X_train , y_train = X[train_idx] , y[train_idx] # 훈련용 데이터
X_valid , y_valid = X[valid_idx] , y[valid_idx] # 검증용 데이터
# LightGBM 전용 데이터셋 생성
dtrain = lgb.Dataset(X_train , y_train) # LightGBM 전용 훈련 데이터 셋
dvalid = lgb.Dataset(X_valid , y_valid) # LightGBM 전용 검증 데이터 셋3) LightGBM 모델 훈련
# LightGBM 모델 훈련
lgb_model = lgb.train(params = params , # 훈련용 하이퍼파라미터
train_set = dtrain, # 훈련 데이터 셋
num_boost_round = 1000, # 부스팅 반복 횟수
valid_sets= dvalid , # 성능 평가용 검증 데이터 셋
feval = gini, # 검증용 평가지표
early_stopping_rounds = 100, # 조기종료 조건
verbose_eval = 100 ) # 100번째마다 점수 출력4) 테스트 데이터를 활용한 OOF 예측
# 테스트 데이터를 활용해 OOF 예측
oof_test_preds += lgb_model.predict(X_test)/folds.n_splits
# 모델 성능 평가를 위한 검증 데이터 타깃값 예측
oof_val_preds[valid_idx] += lgb_model.predict(X_valid)==> oof_test_preds 는 훈련된 모델에 테스트 데이터를 주어 타깃 확률값을 예측한다.
==> folds.n_splits = 5
==> 폴드가 5번 반복되면 oof_val_preds 내 모든 값이 검증 데이터 예측 확률로 업데이트가 된다.
5) 정규화 지니계수 계산
# 검증 데이터 예측 확률에 대한 정규화 지니계수
gini_score = eval_gini(y_valid , oof_val_preds[valid_idx])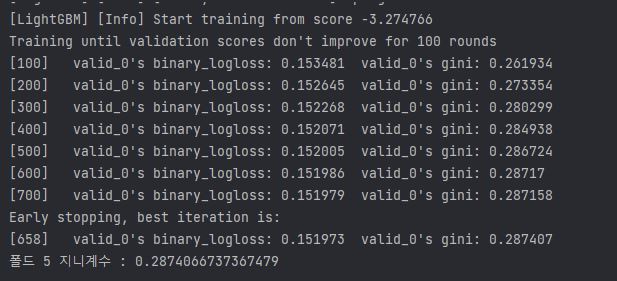
==> 모델 훈련시 verbose_eval = 100 으로 설정해서 100번째 이터레이션마다 성능 평가점수 출력
==> 성능 평가점수는 검증용 데이터로 계산한 값이다.
==> 로그 손실(logloss)는 이진 분류 할때 LightGBM의 기본평가 지표이다.
==> 모델 훈련 시 feval 파라미터에 전달한 gini() 함수의 계산값을 오른쪽에 출력, feval 파라미터에 사용자 정의 함수 전달하지 않으면 logloss만 출력한다.
==> 이터레이션 반복할 수 록 지니계수가 커진다.
==> num_boost_rounds = 1000 전달 ==> 부스팅 최대 반복 횟수가 1000번인데 다 채우지 못하고 조기종료한다.
==> early_stopping_rounds = 100으로 지정하여 , 100번 연속으로 지니계수가 최대값을 갱신하지 못하면 종료한다.
6. 성능 개선 1 : LightGBM 모델
1> 파생 피처 추가
all_data['num_missing'] = (all_data == -1).sum(axis = 1) ==> 첫번째 , 한 데이터가 가진 결측값 개수를 파생 피처로 만들어본다. -1 이 결측값이므로 결측값 개수를 구하려면 -1 개수를 구하면 된다.
==> 데이터 하나당 결측값 개수를 파생 피처로 추가
# 명목형 피처 , calc 분류의 피처를 제외한 피처
remaining_features = [feature for feature in all_features if ('cat' not in feature and 'calc' not in feature)]
# num_missing을 remaining_features 에 추가
remaining_features.append('num_missing')
remaining_features==> 명목형 피처 , calc 분류의 피처를 제외한 피처
remaining_features = ['ps_ind_01', 'ps_ind_03', 'ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin','ps_ind_13_bin','ps_ind_14','ps_ind_15','ps_ind_16_bin','ps_ind_17_bin','ps_ind_18_bin','ps_reg_01','ps_reg_02','ps_reg_03','ps_car_11','ps_car_12','ps_car_13','ps_car_14','ps_car_15', 'num_missing']
ind_features = [feature for feature in all_features if 'ind' in feature]
is_first_feature = True
for ind_feature in ind_features:
if is_first_feature:
all_data['mix_ind'] = all_data[ind_feature].astype(str) + '-'
is_first_feature = False
else:
all_data['mix_ind'] += all_data[ind_feature].astype(str) + '-'
==> 모든 값이 '-'로 연결되었다.
cat_count_features = []
for feature in cat_features+['mix_ind']:
val_counts_dict = all_data[feature].value_counts().to_dict()
all_data[f'{feature}_count'] = all_data[feature].apply(lambda x: val_counts_dict[x])
cat_count_features.append(f'{feature}_count')encoded_cat_matrix : 원-핫 인코딩된 명목형 피처
remaining_features : 명목형 피처와 calc 분류의 피처를 제외한 피처들(+ num_missing)
cat_count_features : mix_ind를 포함한 명목형 피처의 고윳값별 개수 파생 피처
from scipy import sparse
# 필요 없는 피처들
drop_features = ['ps_ind_14' , 'ps_ind_10_bin' , 'ps_ind_11_bin' , 'ps_ind_12_bin' , 'ps_ind_13_bin' , 'ps_car_14']
# remaining_features , cat_count_features 에서 drop_features를 제거한 데이터
all_data_remaining = all_data[remaining_features + cat_count_features].drop(drop_features , axis = 1)
# 데이터 합치기
all_data_sprs = sparse.hstack([sparse.csr_matrix(all_data_remaining) , encoded_cat_matrix] ,format = 'csr')==> scipy 라이브러리의 sparse 모듈로 csr 형태로 행렬 합치기
2> 데이터 나누기
num_train = len(train) # 훈련 데이터 개수
# 훈련 데이터와 테스트 데이터 나누기
X = all_data_sprs[:num_train]
X_test = all_data_sprs[num_train :]
y = train['target'].values3> 하이퍼파라미터 최적화
==> 성능이 우수한 모델을 만들기 위하여 베이지안 최적화 기법을 활용하여 하이퍼파라미터를 조정해야한다.'
베이지안 최적화 : 사전 정보를 바탕으로 최적 하이퍼파라미터 값을 확률적으로 추정하며 탐색하는 기법
https://knowallworld.tistory.com/390
[PYTHON - 머신러닝_캐글_모델]★하이퍼파라미터 최적화★그리드 서치★랜덤서치★베이지안 최적
1. 하이퍼파라미터 ==> 하이퍼파라미터는 사용자가 직접 설정해야 하는 값이다. ==> 모델이 좋은 성능을 내려면 하이퍼파라미터가 어떤 값을 가지면 좋을지를 찾는 작업이 하리어파라미터 최적화
knowallworld.tistory.com
import lightgbm as lgb
from sklearn.model_selection import train_test_split
# 8:2 비율로 훈련 데이터, 검증 데이터 분리(베이지안 최적화 수행용)
X_train , X_valid , y_train , y_valid = train_test_split(X,y, test_size=0.2 , random_state=0)
# 베이지안 최적화용 데이터셋
bayes_dtrain = lgb.Dataset(X_train , y_train)
bayes_dvalid = lgb.Dataset(X_valid, y_valid)==> 베이지안 최적화용 데이터 셋
하이퍼파라미터 범위 설정 :
1> 하이퍼 파라미터 범위를 점점 좁히는 방법 :
ex ) 0~1 범위의 하이퍼파라미터 찾고 다음에는 0.5주변으로 범위를 좁히기
# 베이지안 최적화를 위한 하이퍼파라미터 범위
param_bounds = {'num_leaves' : (30 , 40) , # 개별 트리가 가질 수 있는 최대 말단 노드 개수 , 트리 복잡도 결정, 값이 클수록 좋다.
'lambda_l1' : (0.7 , 0.9), # L1 규제 조정값 , 값이 클수록 과대적합 방지 효과
'lambda_l2' : (0.9 , 1), # L2 규제 조정값 , 값이 클수록 과대적합 방지 효과
'feature_fraction' : (0.6 , 0.7), # 개별 트리를 훈련할 때 사용할 피처 샘플링 비율
'bagging_fraction' : (0.6 , 0.9), # 개별 트리를 훈련할 때 사용할 데이터 샘플링 비율
'min_child_samples' : (6 , 10) , # 말단 노드가 되기 위해 필요한 최소 데이터 개수 , 값이 클수록 과대적합 방지
'min_child_weight' : (10 , 40)} # 과대적합 방지 위한 값
# 값이 고정된 하이퍼파라미터
fixed_params = {'objective' : 'binary' , # 훈련 목적 , 회귀에서는 'regression' , 이진분류에서는 'binary' , 다중분류에서는 'multiclass' 사용
'learning_rate' : 0.005, # 학습률( 부스팅 이터레이션을 반복하면서 모델을 업데이트하는 데 사용 되는 비율)
'bagging_freq' : 1, # 배깅 수행 빈도, 몇번의 이터레이션마다 배깅 수행할 지 결정
'force_row_wise' : True, # 메모리 용량이 충분하지 않을 때 메모리 효율을 높이는 파라미터
'random_state' : 1991} # 랜덤 시드값 (코드를 반복 실행해도 같은 결과가 나오게 지정하는 값)