[PYTHON - 머신러닝_캐글_실습-04]안전 운전자 예측 모델링★XGBoost★LightGBM과 XGBoost 앙상블
1. 성능 개선 ll : XGBoost 모델
XGBoost: 성능이 우수한 트리 기반 부스팅 알고리즘. 결정 트리를 병렬로 배치하는 랜덤 포레스트와 달리 직렬로 배치한다.
https://knowallworld.tistory.com/389
[PYTHON - 머신러닝_캐글_모델]★XGBoost★LightGBM
1. XGBoost(Extreme gradient boosting) ==> 성능이 우수한 트리 기반 부스팅 알고리즘 https://knowallworld.tistory.com/377 [PYTHON - 머신러닝_XGBoost]★pd.options.display.max_columns★정밀도, 재현율, F1-score 1. 부스팅 알고리
knowallworld.tistory.com
2. 피처 엔지니어링
# LightGBM 용 gini() 함수
def gini(preds , dtrain):
labels = dtrain.get_label()
return 'gini' , eval_gini(labels , preds) , True==> LightGBM 용 평가지표(지니계수)는 반환값이 3개로, 평가지표명 , 평가점수, 평가점수가 높으면 좋은지 여부
# XGBoost용 gini() 함수
def gini(preds , dtrain):
labels = dtrain.get_label()
return 'gini' , eval_gini(labels,preds)==> XGBoost 용 지니계수 계산 함수는 반환값이 2개 이다. 평가지표명과 평가점수만 반환한다.
==> 평가점수가 높으면 좋은지 여부는 XGBoost 모델 객체의 train() 메서드에 따로 전달해야한다.
3. 하이퍼파라미터 최적화
1> 데이터셋 준비
import xgboost as xgb
from sklearn.model_selection import train_test_split
# 8:2 비율로 훈련 데이터 , 검증 데이터 분리( 베이지안 최적화 수행용)
X_train , X_valid , y_train , y_valid = train_test_split(X,y, test_size=0.2 , random_state=0)
# 베이지안 최적화용 데이터셋
bayes_dtrain = xgb.DMatrix(X_train , y_train)
bayes_dvalid = xgb.DMatrix(X_valid, y_valid)2> 하이퍼파라미터 범위 설정
# 베이지안 최적화를 위한 하이퍼파라미터 범위
param_bounds = {'max_depth' : (4 , 8) , # 개별 트리의 최대 깊이, 트리 깊이가 깊을수록 모델이 복잡해지고 과대적합 우려
# 값이 클수록 깊이가 한 단계만 늘어나도 메모리 사용량이 급격히 많아진다.
# 일반적으로 3~10 사이의 값을 주로 사용한다.
'subsample' : (0.6 , 0.9), # 개별 트리를 훈련할 때 사용할 데이터 샘플링 비율
# 0~1 사이 값으로 설정할 수 있다.
# 0.5 로 설정하면 전체 데이터의 50%를 사용해 트리를 생성
'colsample_bytree' : (0.7 , 1.0), # 개별 트리를 훈련할 때 사용하는 피처 샘플링 비율
# subsample 과 유사한 개념, subsample은 전체 데이터에서 얼마나 샘플링할지 나타내는 비율
# colsample_bytree는 전체 피처에서 얼마나 샘플링할지 나타내는 비율
# 값이 작을수록 과대적합 방지 효과
'min_child_weight' : (5 , 7), # 과대적합 방지위한 값, 값이 클수록 과대적합 방지 효과가 있다.
'gamma' : (8 , 11), # 말단 노드가 분할하기 위한 최소 손실 감소 값
# 소실 감소가 gamma보다 크면 말단 노드를 분할
# 값이 클수록 과대적합 방지 효과가 있다.
'reg_alpha' : (7 , 9) , # L1 규제 조정 값 , 값이 클수록 과대적합 방지 효과
'reg_lambda' : (1.1 , 1.5), # L2 규제 조정값 , 값이 클수록 과대적합 방지 효과
'scale_pos_weight' : (1.4 , 1.6)} # 뷸균형 데이터 가중치 조정 값 ,
# 타깃값이 불균형할 때 양성 값에 scale_pos_weight 만큼 가중치를 줘서 균형을 맞춤(타깃값 1을 양성 값으로 간주)
# 일반적으로 scale_pos_weight 값을 (음성 타깃값 개수 / 양성 타깃값 개수) 로 설정
# 값이 고정된 하이퍼파라미터
fixed_params = {'objective' : 'binary:logistic' ,# 훈련 목적 , binary : logistic( 확률값을 구하는 이진분류)
# reg : squarederror (회귀 문제)
# 소프트맥스 함수를 사용하는 다중분류에서는 multi : softmax 사용
# 확률값을 구하는 다중분류에서는 'multi : softprob' 사용
'learning_rate' : 0.02, # 학습률( 부스팅 스텝을 반복하면서 모델을 업데이트하는 데 사용되는 비율)
'random_state' : 1991} # 랜덤 시드값(코드를 반복 실행해도 같은 결과가 나오게 지정하는 값)==> 이진분류 문제이므로 objective 는 binary : logistic으로 설정했다.
==> learning_rate 와 random_state도 고정했다.
3> 평가지표 계산 함수 작성
def eval_function(max_depth , subsample , colsample_bytree , min_child_weight , reg_alpha , gamma , reg_lambda , scale_pos_weight) :
# 최적화하려는 평가지표(지니계수) 계산 함수
# 베이지안 최적화를 수행할 하이퍼파라미터
params = {'max_depth' : int(round(max_depth)) , # 개별 트리의 최대깊이
'subsample' : subsample, # 개별 트리를 훈련할 때 사용할 데이터 샘플링 비율
'colsample_bytree' : colsample_bytree , # 개별 트리를 훈련할때 사용하는 피처 샘플링
'min_child_weight' : # 과대적합 방지위한 값
min_child_weight,
'gamma' : gamma, # 말단 노드가 분할하기 위한 최소 손실 감소 값
'reg_alpha' : reg_alpha, # L1 규제 조정값
'reg_lambda' : reg_lambda, # L2 규제 조정값
'scale_pos_weight' : scale_pos_weight} # 불균형 데이터 가중치 조정값
# 값이 고정된 하이퍼파라미터도 추가
params.update(fixed_params)
print('하이퍼파라미터 : ' , params)
# XGBoost 모델 훈련
xgb_model = xgb.train(params = params ,
dtrain = bayes_dtrain,
num_boost_round= 2000,
evals = [(bayes_dvalid , ' bayes_dvalid')],
maximize = True,
feval = gini,
early_stopping_rounds= 200,
verbose_eval= False)
best_iter = xgb_model.best_iteration # 최적 반복횟수
# 검증 데이터로 예측 수행
preds = xgb_model.predict(bayes_dvalid , iteration_range=(0, best_iter))
# 지니계수 계산
gini_score = eval_gini(y_valid, preds)
print(f'지니계수 : {gini_score}\n')
return gini_score==> eval_function() 함수는 XGBoost 하이퍼파라미터를 인수로 받아서 XGBoost를 훈련한 뒤 평가지표인 지니계수를 반환한다.
# XGBoost 모델 훈련 , train() 메서드의 하이퍼파라미터
xgb_model = xgb.train(params = params , # XGBoost 모델의 하이퍼파라미터 목록 , 딕셔너리 타입으로 전달
dtrain = bayes_dtrain, # 훈련 데이터셋, xgboost.DMatrix 타입으로 전달
num_boost_round= 2000, # 부스팅 반복 횟수, 정수형 타입으로 전달
# num_boost_round 값이 클수록 성능이 좋아질 수 있으나 과대적합의 우려가 있다.
# num_boost_round 값이 작으면 반복 횟수가 줄어들어 훈련 시간이 짧아진다.
# 일반적으로 num_boost_round를 늘리면 learning_rate를 줄여야 한다.
evals = [(bayes_dvalid , ' bayes_dvalid')],
# 모델 성능 평가용 검증 데이터셋
# (DMatrix, 문자열) 쌍들을 원소로 갖는 리스트 타입으로 전달, 검증 데이터셋 이름을 원하는 대로 문자열로 정하면 된다.
maximize = True, # feval 평가지수가 높으면 좋은지 여부
feval = gini, # 검증용 평가지표, 사용자 정의 함수 형태
# evals를 활용해 모델 성능을 검증할 때 사용할 사용자 정의 평가지표 함수
# 예측값과 실제값을 파라미터로 전달받아, 평가지표명과 평가점수를 반환하는 함수이다.
early_stopping_rounds= 200,
# 조기종료 조건
# 모델은 기본적으로 num_boost_round만큼 훈련을 반복하며, 매 이터레이션마다 evals로 모델 성능을 평가하여 성능이 연속으로
# 좋아지지 않는다면 훈련을 중단하는데, 훈련 중단에 필요한 최소횟수가 early_stopping_rounds 이다. 즉 , early_stopping_rounds
# 동안 모델 성능이 좋아지지 않는다면 훈련을 중단한다.
# 과대적합 방지 효과
# 조기종료를 적용하기 위해서는 evals 에 검증 데이터가 하나 이상 있어야한다. 또한 evals에 검증 데이터가 여러 개라면 마지막 검증
# 데이터를 기준으로 조기종료 조건을 적용한다.
verbose_eval= False) # 성능 점수 로그 설정 값
# True 로 설정하면 매 부스팅 스텝마다 평가점수르 출력
# 출력값이 너무 많아지는 것을 방지하기위해 verbose_eval로 설정==> xgb 모델 훈련
==> LightGBM 은 기본적으로 훈련 단계에서 성능이 가장 좋았던 반복 횟수 때의 모델을 활용해 예측한다.
best_iter = xgb_model.best_iteration # 최적 반복횟수==> XGBoost는 성능이 가장 좋을 때의 부스팅 반복 횟수를 예측시 iteration_range 파라미터로 명시해줘야 최적 반복 횟수로 훈련된 모델을 활용해 예측한다.
xgb_model = xgb.train(params = params , # XGBoost 모델의 하이퍼파라미터 목록 , 딕셔너리 타입으로 전달
dtrain = bayes_dtrain, # 훈련 데이터셋, xgboost.DMatrix 타입으로 전달
num_boost_round= 2000, # 부스팅 반복 횟수, 정수형 타입으로 전달
# num_boost_round 값이 클수록 성능이 좋아질 수 있으나 과대적합의 우려가 있다.
# num_boost_round 값이 작으면 반복 횟수가 줄어들어 훈련 시간이 짧아진다.
# 일반적으로 num_boost_round를 늘리면 learning_rate를 줄여야 한다.
evals = [(bayes_dvalid , ' bayes_dvalid')],
# 모델 성능 평가용 검증 데이터셋
# (DMatrix, 문자열) 쌍들을 원소로 갖는 리스트 타입으로 전달, 검증 데이터셋 이름을 원하는 대로 문자열로 정하면 된다.
maximize = True, # feval 평가지수가 높으면 좋은지 여부==> evals는 검증 데이터를 전달받는 파라미터로, 검증 데이터와 검증 데이터 이름의 쌍을 튜플로 묶어서 evals = [(bayes_dvalid , 'bayes_dvalid')] 형태로 전달했다.
==> 검증용으로 훈련 데이터와 검증 데이터 모두 사용하고 싶다면 [(bayes_dtrain, 'bayes_dtrain') , (bayes_dvalid , 'bayes_dvalid')] 처럼 전달해도 된다.
==> maximize 파라미터에는 True를 전달하여, 평가점수(지니계수)가 클 수록 좋다는 것을 의미시킨다
# 검증 데이터로 예측 수행
preds = xgb_model.predict(bayes_dvalid , iteration_range=(0, best_iter))==> LightGBM 예측 코드는 lgb_model.predict(X_valid) 이다. Dataset 타입(LightGBM 용 데이터셋 타입) 이 아니라 원본 데이터 타입인 X_valid를 그대로 전달하였다.
==> XGBoost의 predict()에는 데이터를 DMatrix 타입(XGBoost용 데이터셋 타입)으로 전달해야한다.
4> 최적화 수행
from bayes_opt import BayesianOptimization
# 베이지안 최적화 객체 생성
optimizer = BayesianOptimization(f= eval_function, pbounds = param_bounds , random_state= 0)
# 베이지안 최적화 수행
optimizer.maximize(init_points= 3 , n_iter= 6)
# 평가함수 점수가 최대일 때 하이퍼파라미터
max_params = optimizer.max['params']
max_params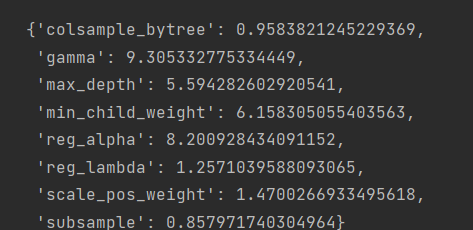
# 정수형 하이퍼파라미터 변환
max_params['max_depth'] = int(round(max_params['max_depth']))
# 값이 고정된 하이퍼파라미터 추가
max_params.update(fixed_params)
max_params
4. 모델 훈련 및 성능 검증
from sklearn.model_selection import StratifiedKFold
# 층화 K 폴드 교차 검증기 생성
folds = StratifiedKFold(n_splits= 5 , shuffle= True , random_state= 1991)
# OOF 방식으로 훈련된 모델로 검증 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_val_preds = np.zeros(X.shape[0])
# OOF 방식으로 훈련된 모델 훈련 , 검증 , 예측
for idx , (train_idx , valid_idx) in enumerate(folds.split(X,y)):
# 각 폴드를 구분하는 문구 출력
print('#' *40, f'폴드 {idx+1} / 폴드 {folds.n_splits}' , '#'*40)
# 훈련용 데이터, 검증용 데이터 설정
X_train , y_train = X[train_idx] , y[train_idx]
X_valid , y_valid = X[valid_idx] , y[valid_idx]
#XGBoost 전용 데이터셋 생성
dtrain = xgb.DMatrix(X_train , y_train)
dvalid = xgb.DMatrix(X_valid , y_valid)
dtest = xgb.DMatrix(X_test)
#XGBoost 모델 훈련
xgb_model = xgb.train(params = max_params,
dtrain = dtrain,
num_boost_round = 2000,
evals = [(dvalid , 'valid')],
maximize = True,
feval = gini,
early_stopping_rounds = 200,
verbose_eval = 100)
# 모델 성능이 가장 좋을 때의 부스팅 반복 횟수 저장
best_iter= xgb_model.best_iteration
# 테스트 데이터를 활용해 OOF 예측
oof_test_preds += xgb_model.predict(dtest, iteration_range = (0 , best_iter))/ folds.n_splits
oof_test_preds_xgb = oof_test_preds
# 모델 성능 평가를 위한 검증 데이터 타깃값 예측
oof_val_preds[valid_idx] += xgb_model.predict(dvalid , iteration_range=(0, best_iter))
# 검증 데이터 예측 확률에 대한 정규화 지니계수
gini_score = eval_gini(y_valid , oof_val_preds[valid_idx])
print(f'폴드 {idx+1} 지니계수 : {gini_score}\n')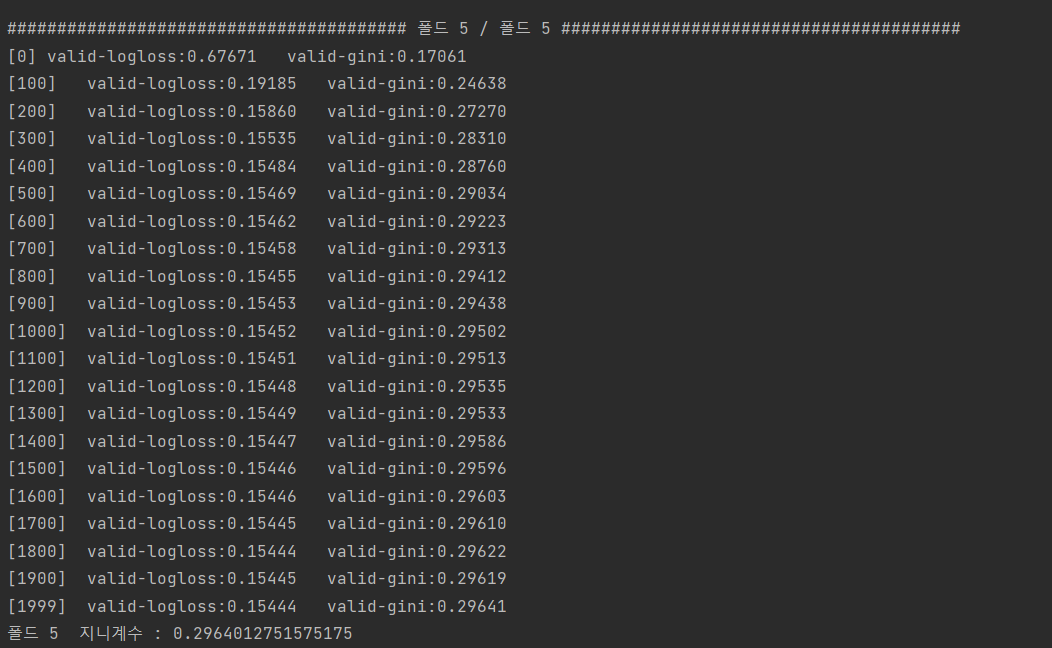
==> 조기종료 조건(early_stopping_rounds)이 200회 이므로 1799에서 가장 좋은 성능을 보였다.
==> 1799에서 지니계수가 0.296401275 였다는 것이다.
print('OOF 검증 데이터 지니계수 : ' , eval_gini(y , oof_val_preds))OOF 검증 데이터 지니계수 : 0.28905038063620453
==> 폴드 5개의 지니계수의 평균값??
https://knowallworld.tistory.com/397
[PYTHON - 머신러닝_캐글_실습-02]안전 운전자 예측 모델링★베이지안 최적화★LightGBM★K-폴드 교차
1. 베이스라인 모델 1) 데이터 불러오기 2) 피처 엔지니어링 --> 명목형 피처 원-핫 인코딩 --> 필요 없는 피처 제거 3) 평가지표 계산 함수 작성 --> 정규화 지니계수 4) 모델 훈련 --> 모델 : LightGBM -->
knowallworld.tistory.com
5. 성능 개선 lll : XGBoost 모델과 LightGBM 앙상블
==> 두 모델의 예측값을 결합하면 더 좋은 점수를 얻을 수 잇다. 여러 모델에서 얻은 예측 결과를 결합해 더 좋은 예측값을 도출하는 방식을 앙상블 이라고 한다.
1> 앙상블 수행
==> LightGBM으로 예측한 확률값을 oof_test_preds_lgb라 하고, XGBoost로 예측한 확률값을 oof_test_preds_xgb라고 한다.
oof_test_preds = oof_test_preds_lgb *0.5 + oof_test_preds_xgb * 0.5
submission['target'] = oof_test_preds==> 각각에 공평하게 50% 씩의 가중치를 부여하여 구한 가중평균을 최종 예측 확률로 정한다.
submission