전체 글
-
[Python, Ver 2.0] 백준 25304번 영수증 ★ map() 활용하기2023.03.27
-
[머신러닝 이론 01-01] 머신러닝과 통계학2023.03.22
[Python, Ver 2.0] 백준 25304번 영수증 ★ map() 활용하기

https://www.acmicpc.net/problem/25304
25304번: 영수증
준원이는 저번 주에 살면서 처음으로 코스트코를 가 봤다. 정말 멋졌다. 그런데, 몇 개 담지도 않았는데 수상하게 높은 금액이 나오는 것이다! 준원이는 영수증을 보면서 정확하게 계산된 것
www.acmicpc.net
VERSION 2.0
import sys
X = int(sys.stdin.readline())
N = int(sys.stdin.readline())
res = 0
for i in range(N):
A = list(map(int , sys.stdin.readline().split()))
res += A[0]*A[-1]
if res == X:
print('Yes')
else:
print('No')==> map() 활용하기
VERSION 1.0
import sys
X = int(sys.stdin.readline())
N = int(sys.stdin.readline())
a=0
res = 0
while True:
if a < N:
A = list(map(int, sys.stdin.readline().split()))
res += A[0]*A[1]
a+=1
#print(res)
else:
break
if res == X:
print('Yes')
else:
print('No')'Python(백준) > 반복문' 카테고리의 다른 글
| [Python , VER2.0] 백준 2439번 별찍기 -2★Range 거꾸로 가기 (0) | 2023.03.27 |
|---|---|
| [Python , VER2.0] 백준 11021번 A+B-7★리스트에 문자열 추가하기 (1) | 2023.03.27 |
| [Python , Ver2.0] 백준 11021번 A+B-7★list(map) (1) | 2023.03.27 |
[Python , VER2.0] 백준 2439번 별찍기 -2★Range 거꾸로 가기

VERSION 2.0
import sys
N = int(sys.stdin.readline())
for i in range(N-1,-1,-1):
A = " " * i
B = "*" * (N-i)
print(A+B)==> range 거꾸로 가기
VERSION 1.0
import sys
N = int(sys.stdin.readline())
for i in range(1,N+1):
print(' '*(N-i)+('*'*i))'Python(백준) > 반복문' 카테고리의 다른 글
| [Python, Ver 2.0] 백준 25304번 영수증 ★ map() 활용하기 (0) | 2023.03.27 |
|---|---|
| [Python , VER2.0] 백준 11021번 A+B-7★리스트에 문자열 추가하기 (1) | 2023.03.27 |
| [Python , Ver2.0] 백준 11021번 A+B-7★list(map) (1) | 2023.03.27 |
[Python , VER2.0] 백준 11021번 A+B-7★리스트에 문자열 추가하기

VERSION 2.0
import sys
T = int(sys.stdin.readline())
res = []
for i in range(T):
A = list(map(int , sys.stdin.readline().split()))
res.append(f"Case #{i+1}: {A[0]} + {A[-1]} = {A[0] +A[-1]}")
for j in range(T):
print(res[j])==> 리스트에 추가할때 문자열 형태로 추가 가능
VERSION 1.0
import sys
T = int(sys.stdin.readline())
a=0
B =[]
while True:
if a!=T:
a+=1
res = 0
A = list(map(int, sys.stdin.readline().split()))
res = A[0] + A[-1]
print("Case #{}: {} + {} = {}".format(a, A[0] , A[1] , res))
else:
break'Python(백준) > 반복문' 카테고리의 다른 글
| [Python, Ver 2.0] 백준 25304번 영수증 ★ map() 활용하기 (0) | 2023.03.27 |
|---|---|
| [Python , VER2.0] 백준 2439번 별찍기 -2★Range 거꾸로 가기 (0) | 2023.03.27 |
| [Python , Ver2.0] 백준 11021번 A+B-7★list(map) (1) | 2023.03.27 |
[Python , Ver2.0] 백준 11021번 A+B-7★list(map)
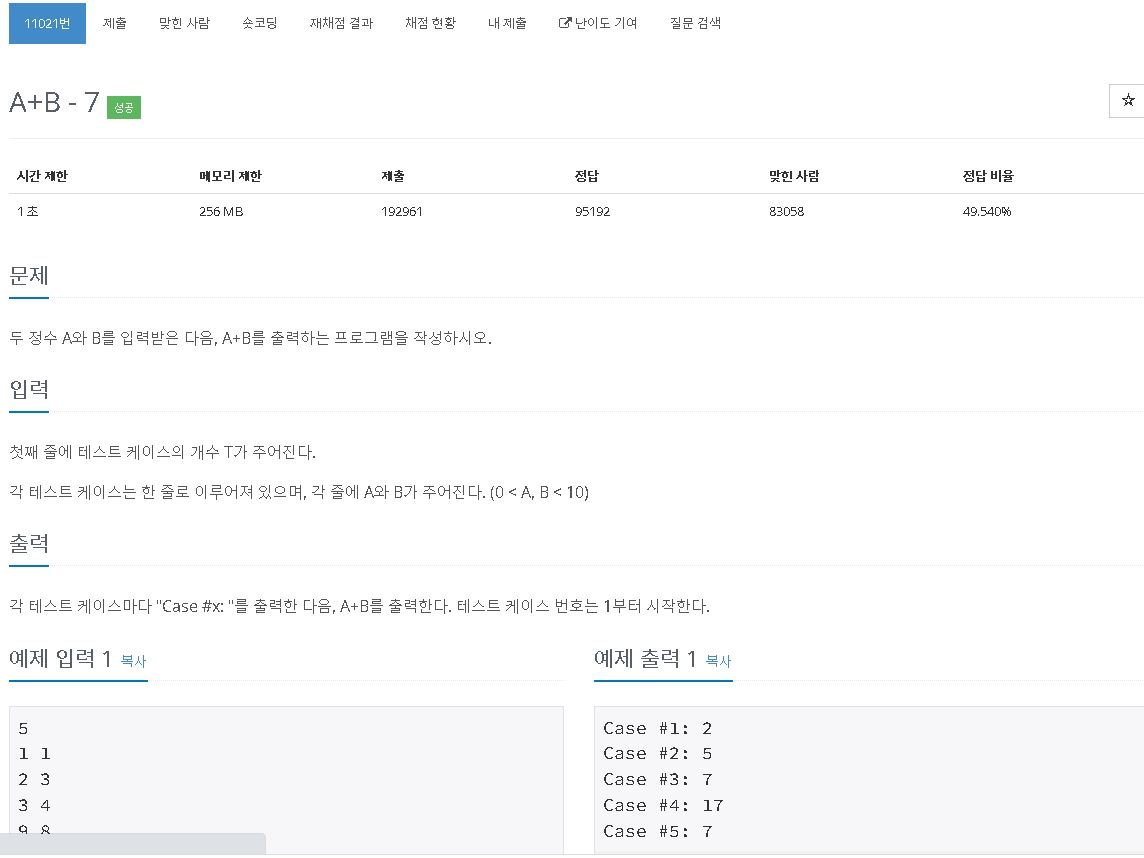
VERSION 2.0
import sys
T = int(sys.stdin.readline())
res = []
for i in range(T):
A = list(map(int, sys.stdin.readline().split()))
res.append(A[0]+A[-1])
for j in range(T):
print(f"Case #{j+1}: {res[j]}")==> list(map) 다시 기억하기
VERSION 1.0
import sys
T = int(sys.stdin.readline())
a=0
B =[]
while True:
if a!=T:
a+=1
res = 0
A = list(map(int, sys.stdin.readline().split()))
res = A[0] + A[-1]
B.append(res)
else:
break
for i in range(len(B)):
print("Case #{} : {}".format(i+1, B[i]) )
'Python(백준) > 반복문' 카테고리의 다른 글
| [Python, Ver 2.0] 백준 25304번 영수증 ★ map() 활용하기 (0) | 2023.03.27 |
|---|---|
| [Python , VER2.0] 백준 2439번 별찍기 -2★Range 거꾸로 가기 (0) | 2023.03.27 |
| [Python , VER2.0] 백준 11021번 A+B-7★리스트에 문자열 추가하기 (1) | 2023.03.27 |
[머신러닝 이론 01-01] 머신러닝과 통계학
1. 머신러닝과 통계학
1> 머신러닝 : 예측력이 얼마나 높은가에 집중
ex) 사진을 얼마나 정확히 구별하느냐 또는 고객의 구매를 얼마나 정확히 예측하는가를 기준
==> 분석 모형의 복잡성(complexity)가 높으며, 과적합(overfitting) 해결에 집중한다.
과적합(Overfitting) : 학습데이터를 과하게 학습하여 예측데이터에 대한 정확도가 감소
'머신러닝 > 머신러닝_이론' 카테고리의 다른 글
[SQLD 2-03] ★COUNT OVER★PRECEDING, FOLLOWING★TOP★ROW LIMITING★START WITH★CONNECT BY★정규표현
1. WINDOWS 함수 COUNT OVER
SELECT EMPNO , ENAME , SAL , COUNT(*) OVER (
ORDER BY SAL RANGE BETWEEN 50 PRECEDING AND 100 FOLLOWING) AS C1 FROM EMP
WHERE DEPTNO = 20
==> 각 SAL 값의 범위를 50뺀값에서 100 더한 값을 범위로 지정한다.
==> 750~850
==> 1050 ~ 1200
==> 2925 ~ 3075
==> 2950 ~ 3100
2. SELECT 문의 처리순서
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
3. TOP 절
SELECT TOP (4) WITH TIES * FROM EMP ORDER BY SAL DESC;==> WITH TIES
SELECT * FROM (SELECT EMPNO , ENAME , SAL , RANK() OVER (ORDER BY SAL DESC) AS RN FROM EMP)
WHERE RN <=4;
3. ROW LIMITING 절
1> ROW_NUMBER
SELECT * FROM
(SELECT EMPNO, ENAME , SAL , ROW_NUMBER() over (ORDER BY SAL DESC) AS RN FROM EMP)
WHERE RN <=3
2> OFFSET
SELECT EMPNO, ENAME, SAL FROM EMP
ORDER BY SAL DESC OFFSET 3 ROWS;==> 3번째 행 제외하고 출력
3> FETCH
==> 반환할 행의 개수나 백분율 지정
SELECT EMPNO, ENAME, SAL FROM EMP
ORDER BY SAL DESC FETCH FIRST 3 ROWS ONLY ;==> 위의 3개의 행 반환
4> WITH TIES
SELECT EMPNO, ENAME, SAL FROM EMP
ORDER BY SAL DESC FETCH NEXT 10 ROWS WITH TIES;==> 상위 10개 행 반환
4. SELF JOIN
SELECT A.ENAME , B.EMPNO , B.ENAME FROM EMP A, EMP B
WHERE A.ENAME = 'JONES'
SELECT A.ENAME , B.EMPNO , B.ENAME FROM EMP A, EMP B
WHERE A.ENAME = 'JONES' AND B.MGR = A.EMPNO;
==> JONES 의 EMPNO와 MGR이 같은 것들 출력
5. 계층쿼리
SELECT EMPNO, ENAME, MGR FROM EMP
START WITH ENAME = 'JONES'
CONNECT BY MGR = PRIOR EMPNOSTART WITH 절 : 루트 노드를 생성하며 1번만 수행
CONNECT BY 절 : 루트 노드의 하위 노드를 생성하고 결과가 없을 때까지 반복 수행

==> 이전의 쿼리의 EMPNO와 현재 MGR이 동일한거 출력하기
==> ENAME이 JONES인거를 루트 노드로 지정한다.
6. PIVOT TABLE , UNPIVOT
CREATE TABLE EMP (
JOB varchar2(20) NOT NULL,
DEPTNO VARCHAR2(10),
SAL VARCHAR2(9));
INSERT INTO EMP (JOB, DEPTNO, SAL)
SELECT 'ANALYST', 10, 3000 FROM DUAL UNION ALL
SELECT 'CLERK', 10, 1000 FROM DUAL UNION ALL
SELECT 'CLERK', 20, 2000 FROM DUAL UNION ALL
SELECT 'CLERK', 20, 1500 FROM DUAL UNION ALL
SELECT 'ANALYST', 10, 4000 FROM DUAL UNION ALL
SELECT 'CLERK', 20, 1200 FROM DUAL UNION ALL
SELECT 'CLERK', 10, 800 FROM DUAL;==> UNION ALL 활용하여 테이블 추가
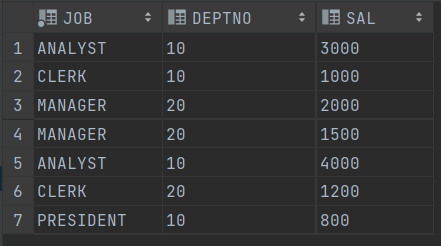
SELECT * FROM (SELECT JOB , DEPTNO , SAL FROM EMP WHERE
DEPTNO IN (10,20))
PIVOT (SUM(SAL) FOR DEPTNO IN (10,20)) ORDER BY JOB
7. 정규표현
SELECT REGEXP_SUBSTR('ABC' , 'A.+') AS C1,
REGEXP_SUBSTR('ABC' , 'A.+?') AS C2
FROM DUAL
마침표(.) 는 모든 문자
더하기(+)는 1회 또는 그 이상의 횟수
물음표(?)는 끝내기
SELECT REGEXP_SUBSTR('ABD' , 'AB|CD') AS C1,
REGEXP_SUBSTR('ABD' , 'A(B|C)D') AS C2
FROM DUAL
AB or CD
A(B or C) D
2> 문자 리스트
SELECT REGEXP_SUBSTR('HTTP://WWW.ABC.COM/EFG' , '[^:/]+',1,2) AS C1 FROM DUAL[char] : 문자 리스트 중 한 문자와 일치
[^char] : 문자 리스트에 포함되지 않은 한 문자와 일치
[^:/]+ : ':' 와 '/' 를 포함하지 않은 2 번째 문자 값을 반환한다.
SELECT REGEXP_REPLACE('1A2B3C4D' , '\D') AS C1 FROM DUAL
'\D' ==> 숫자가 아닌 패턴 ==> 숫자만 출력한다
'SQL > SQLD' 카테고리의 다른 글
[SQLD 2-02] ★SELECT 1 FROM T2★DISTINCT(중복제거)★MINUS★집계함수 ROLLUP , CUBE,GROUPING SETS★
1. SELECT 1 FROM T2
SELECT * FROM T2;
SELECT 1 FROM T2 X;
2. DISTINCT(중복제거) , MINUS
SELECT * FROM T1;
SELECT DISTINCT A.C1 FROM T1 A
SELECT C1 FROM T1 MINUS SELECT C1 FROM T2;==> MINUS 의 경우 중복제거
3. 테이블 데이터 변경하기

UPDATE T1
SET C1 = CASE
WHEN C1 = 1 AND ROWNUM = 1 THEN 1
WHEN C1 = 1 AND ROWNUM = 2 THEN 2
ELSE 2
END;==> ROWNUM을 활용하여 T1 테이블 값 변경하기
SELECT ROWNUM, T1.*
FROM T1;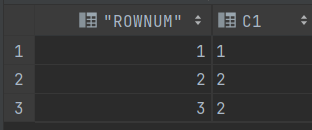
4. ROLLUP , CUBE , GROUPING SETS
CREATE TABLE T1 (
C1 VARCHAR2(1),
C2 DATE,
C3 NUMBER(1)
);
INSERT INTO T1 (C1, C2, C3) VALUES ('A', TO_DATE('2050-01-01', 'YYYY-MM-DD'), 1);
INSERT INTO T1 (C1, C2, C3) VALUES ('A', TO_DATE('2050-01-02', 'YYYY-MM-DD'), 1);
INSERT INTO T1 (C1, C2, C3) VALUES ('B', TO_DATE('2050-01-01', 'YYYY-MM-DD'), 1);
INSERT INTO T1 (C1, C2, C3) VALUES ('B', TO_DATE('2050-01-02', 'YYYY-MM-DD'), 1);
INSERT INTO T1 (C1, C2, C3) VALUES ('C', TO_DATE('2050-01-01', 'YYYY-MM-DD'), 1);
INSERT INTO T1 (C1, C2, C3) VALUES ('C', TO_DATE('2050-01-02', 'YYYY-MM-DD'), 1);
SELECT C1 , C2 , SUM(C3) AS C3 FROM T1 GROUP BY ROLLUP(C2, C1);
ROLLUP 소계 ==> (C2 , C1) , C2 , () 로 집계
SELECT C1 , C2 , SUM(C3) AS C3 FROM T1 GROUP BY ROLLUP( (C1, C2));
ROLLUP 소계 ==> (C1 , C2) , () 로 집계
==> 괄호로 묶기
SELECT C1 , C2 , SUM(C3) AS C3 FROM T1 GROUP BY CUBE(C1, C2);
CUBE 소계 ==> (C1 , C1) , C1 , C2 , () 로 집계
SELECT C1 , C2 , SUM(C3) AS C3 FROM T1 GROUP BY GROUPING SETS ( (C1, C2) , C1
GROUPING SETS 소계 ==> (C1 , C2) ,C1 ==> 순서대로

5. RANK , DENSE_RANK
RANK() ==> 동일순위 허용 0 ==> 1 2 2 4
DENSE_RANK() ==> 동일순위 허용 0 ==> 1 2 2 3
https://knowallworld.tistory.com/410
[SQLD 2-01] ★LEFT OUTER JOIN★RANK()★DENSE_RANK()★GROUPBY★LPAD()★UPDATE★UNION★UNION ALL★MINUS★INTERSECT★기
1. LEFT OUTER JOIN CREATE TABLE 고객 ( 고객번호 INT, 고객명 VARCHAR2(50) ); CREATE TABLE 주문 ( 주문번호 INT, 고객번호 INT, 주문금액 INT ); INSERT INTO 고객 (고객번호, 고객명) VALUES (1, '김대원'); INSERT INTO 고객 (고
knowallworld.tistory.com
'SQL > SQLD' 카테고리의 다른 글
[SQLD 2-01] ★LEFT OUTER JOIN★RANK()★DENSE_RANK()★GROUPBY★LPAD()★UPDATE★UNION★UNION ALL★MINUS★INTERSECT★기존 데이터 변경, 데이터타입 변경★CASE WHEN THEN
1. LEFT OUTER JOIN
CREATE TABLE 고객 (
고객번호 INT,
고객명 VARCHAR2(50)
);
CREATE TABLE 주문 (
주문번호 INT,
고객번호 INT,
주문금액 INT
);
INSERT INTO 고객 (고객번호, 고객명) VALUES (1, '김대원');
INSERT INTO 고객 (고객번호, 고객명) VALUES (2, '노영미');
INSERT INTO 고객 (고객번호, 고객명) VALUES (3, '김경진');
INSERT INTO 고객 (고객번호, 고객명) VALUES (4, '박하연');
INSERT INTO 주문 (주문번호, 고객번호 , 주문금액) VALUES (2001,1,40000);
INSERT INTO 주문 (주문번호, 고객번호 , 주문금액) VALUES (2002,2,15000);
INSERT INTO 주문 (주문번호, 고객번호 , 주문금액) VALUES (2003,2,7000);
INSERT INTO 주문 (주문번호, 고객번호 , 주문금액) VALUES (2004,2,8000);
INSERT INTO 주문 (주문번호, 고객번호 , 주문금액) VALUES (2005,2,20000);
INSERT INTO 주문 (주문번호, 고객번호 , 주문금액) VALUES (2006,3,5000);
INSERT INTO 주문 (주문번호, 고객번호 , 주문금액) VALUES (2007,3,9000);

SELECT A.고객번호 , (SELECT SUM(X.주문금액)
FROM 주문 X
WHERE X.고객번호 = A.고객번호) AS 주문합계금액
FROM 고객 A
WHERE A.고객번호 IN(3,4);
SELECT A.고객번호, SUM(B.주문금액) AS 주문합계금액
FROM 고객 A
LEFT OUTER JOIN
주문 B ON B.고객번호 = A.고객번호
WHERE A.고객번호 IN (3,4)
GROUP BY A.고객번호
;==> LEFT OUTER JOIN ==> 왼쪽으로 OUTER JOIN
2. RANK() , ROW_NUMBER()

SELECT * FROM EMP
WHERE SAL > (SELECT SAL FROM (SELECT SAL, ROW_NUMBER() OVER (ORDER BY SAL DESC) AS RK FROM EMP WHERE SAL < 1300) WHERE RK = 1);
==> RANK() ==> 동일순위 허용 ==> 서브쿼리에서 다중 행 반환 ==> 오류 발생 ==> 1 2 2 4
==> DENSE_RANK() ==> 동일순위 허용 ==> 1 2 2 3
==> 1300 이하인 SAL 중에서 제일 큰거를 RK 열의 1번째(제일 큰거) 의 SAL 반환
3. GROUP BY
SELECT EMPNO, ENAME , SAL , DEPTNO FROM EMP
WHERE (DEPTNO , SAL) IN (SELECT DEPTNO, MAX(SAL) FROM EMP
GROUP BY DEPTNO);==> DEPTNO , SAL 열이 (DEPTNO 로 GROUP 화 하였을 때 , SAL 중에 제일 큰

4. LPAD
SELECT SAL , LPAD(SAL, 4 , '0') FROM EMP;
==> 왼쪽부터 0을채우고 4개로 채우기
SELECT MAX(LPAD(SAL, 4 , '0') || ENAME) FROM EMP WHERE LPAD(SAL, 4 , '0')=1250;
5. UPDATE
UPDATE T2
SET C1 = 4
WHERE C1 = 2;6. UNION , UNION ALL , MINUS , INTERSECT
CREATE TABLE T1 (
C1 INT
);
CREATE TABLE T2 (
C1 INT
);
CREATE TABLE T3 (
C1 INT
);
INSERT INTO T1 (C1) VALUES (1);
INSERT INTO T1 (C1) VALUES (2);
INSERT INTO T1 (C1) VALUES (3);
INSERT INTO T2 (C1) VALUES (1);
INSERT INTO T2 (C1) VALUES (2);
INSERT INTO T3 (C1) VALUES (2);
INSERT INTO T3 (C1) VALUES (3);1> UNION ALL
SELECT C1 FROM T1 UNION ALL SELECT C1 FROM T2
==> 모조리 합하기!
2> UNION
SELECT C1 FROM T1 UNION SELECT C1 FROM T2
==> 중복된거 하나로 만든 합집합(PYTHON의 SET과 비슷)
3> MINUS
SELECT C1 FROM T1 MINUS SELECT C1 FROM T2
==> 차집합
4> INTERSECT
SELECT C1 FROM T1 INTERSECT SELECT C1 FROM T2
==> 교집합
7. 데이터 타입 변경 , 기존 DATA 변경
ALTER TABLE T1 MODIFY C1 VARCHAR2(10);==> T1 테이블의 C1 열의 데이터타입을 변경
UPDATE T1 SET C1 = CASE WHEN C1 = 1 THEN 'A'
WHEN C1 = 2 THEN 'A'
WHEN C1 = 3 THEN 'B'
END;==> C1 열의 값 변경
ALTER TABLE T1 ADD C2 NUMBER(10);==> C2 열 생성 및 데이터 타입 설정
UPDATE T1 SET C2 = 1;==> C2 열의 모든 값 1로 변경

ALTER TABLE T1 ADD C2 NUMBER(10);
UPDATE T1 SET C2 = 1;
UPDATE T2 SET C1 = CASE WHEN C1 = 1 THEN 'B'
WHEN C1 = 4 THEN 'C'
END;
INSERT INTO T2 (C1) VALUES ('C');
ALTER TABLE T2 ADD C2 NUMBER(10);
UPDATE T2 SET C2 = 1;
SELECT * FROM T2;
SELECT C1 , SUM(C2) AS C2 , SUM(C3) AS C3
FROM (SELECT C1 , C2 , NULL AS C3 FROM T1
UNION ALL
SELECT C1 , NULL AS C2 ,C3 FROM T2)
GROUP BY C1 ORDER BY C1;
==> UNION ALL에서 NULL값 끼리는 GROUP BY 안된다.
'SQL > SQLD' 카테고리의 다른 글
| [SQLD 2-03] ★COUNT OVER★PRECEDING, FOLLOWING★TOP★ROW LIMITING★START WITH★CONNECT BY★정규표현 (0) | 2023.03.18 |
|---|---|
| [SQLD 2-02] ★SELECT 1 FROM T2★DISTINCT(중복제거)★MINUS★집계함수 ROLLUP , CUBE,GROUPING SETS★ (0) | 2023.03.18 |
| [SQLD -03] ★DECODE★CROSS JOIN★ (1) | 2023.03.12 |
| [SQLD -02] ★NATURAL JOIN★JOIN 총정리★ (0) | 2023.03.11 |
| [SQLD-01] ★OUTER JOIN★내부조인(INNER JOIN)★카티션★ (0) | 2023.03.11 |