[PYTHON - 머신러닝_주성분 분석_PCA]★비지도학습★차원 축소★반영 비율 확인
1. PCA(Principal Component Analysis)
==> 비지도 학습 ==> 종속변수는 존재 X ==> 어떤 것을 예측하지도 분류하지도 않는다.
==> 데이터의 차원 축소 : 변수 2개 ==> 2차원 그래프 , 변수 3개 ==> 3차원 그래프 ==> 변수의 개수
==> 변수의 수를 줄여 데이터의 차원을 축소한다. ==> 기존 변수중 일부를 그대로 선택이 아닌, 기존 변수들의 정보를 모두 반영하는 새로운 변수들을 생성
장점 :
㉠ 다차원을 2차원에 적합하도록 차원 축소하여 시각화에 유용하다.
㉡ 변수 간의 높은 상관관계 문제를 해결해준다.
단점 :
㉠ 기존 변수가 아닌 새로운 변수를 사용하여 해석하는 데 어려움이 있다.
㉡ 차원이 축소됨에 따라 정보손실이 일어난다.
2. PCA 실습
from sklearn.decomposition import PCApca = PCA(n_components= 2) # 주성분 개수 지정==> 주성분 개수 지정
pca.fit(customer_X) # 학습
customer_pca = pca.transform(customer_X) # 변환==> 학습 및 변환

==> 독립변수 여러개가 2차원 으로 축소 되었다.
==> 종속변수(label)
sns.scatterplot(x= 'PC1' , y='PC2' , data = customer_pca , hue = 'label' , palette= 'rainbow') # 산점도 그리기
==> 보라색과 빨간색 클러스터는 가깝게 붙어 있어 경계가 모호
==> but. 클러스터들이 얼마나 잘 나뉘었는지를 대략 확인하는 것일 뿐이다.
df_comp = pd.DataFrame(pca.components_, columns = customer_X.columns)
df_comp==> 주성분과 변수의 관계 확인

==> 인덱스 0과 1은 주성분 PC1 과 PC2 의미.
==> 위의 행들은 기존 데이터의 독립변수들
==> 특정 주성분과 특정 변수와의 상관관계
==> ex) PC1 과 amt의 상관관계는 0.35 ==> PC1과 amt는 양의 상관관계
PC2 와 category_gas_transport 의 상관관계는 -0.544==> 음의 상관관계
sns.heatmap(df_comp , cmap='coolwarm')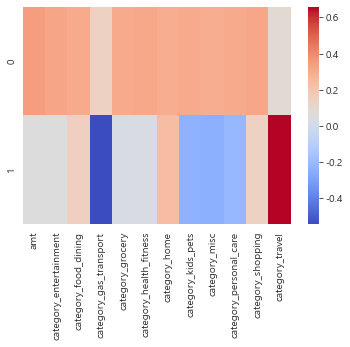
3. PCA 실습-02
from sklearn.model_selection import train_test_split
X_train, X_test , y_train, y_test = train_test_split(data.drop('class' , axis =1) , data['class'] , test_size= 0.2 , random_state= 100)
#학습 셋, 시험 셋 분리from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() # 스케일러 객체 생성
scaler.fit(X_train) # 학습
X_train_scaled = scaler.transform(X_train) # 변환
X_test_scaled = scaler.transform(X_test) # 변환from sklearn.ensemble import RandomForestClassifier
model_1 = RandomForestClassifier(random_state= 100)==> RandomForestClassifier은 ensemble 패키지 안에 있다.
==> 랜덤 포레스트는 매번 다른 방식으로 나무들을 생성한다.
https://knowallworld.tistory.com/376
[PYTHON - 머신러닝_랜덤 포레스트]★str.split(expand= True)★K-폴드 교차검증★하이퍼파라미터 튜닝
1. 랜덤 포레스트 ==> 결정 트리의 단점인 오버피팅 문제를 완화시켜주는 발전된 형태의 트리 모델이다. https://knowallworld.tistory.com/375 [PYTHON - 머신러닝_결정트리]★예측력, 설명력★빈칸 제거_skipin
knowallworld.tistory.com
import time
start_time = time.time() # 시작시간 설정
model_1.fit(X_train_scaled , y_train) # 학습
print(time.time() - start_time) # 소요시간 출력==> 83초
from sklearn.metrics import accuracy_score, roc_auc_score
pred_1 = model_1.predict(X_test_scaled)
accuracy_score(y_test , pred_1)==> 0.958
proba_1 = model_1.predict_proba(X_test_scaled) # 예측 , 소수점 형태로 된 예측값을 사용하기 때문에, predict()가 아닌 predict_proba()를 사용해야 한다.
roc_auc_score(y_test , proba_1[: , 1])https://knowallworld.tistory.com/378
[PYTHON - 머신러닝_LightGBM]★geopy.distance이용한 거리계산★groupby★agg활용한 통계계산★time 라이브
1. LightGBM ==> XGBoost 이후 나온 최신 부스팅 모델. ==> 리프 중심 트리 분할 방식 사용 장점 : ㉠ XGBoost보다 빠르고 높은 정확도를 보여준다. ㉡ 예측에 영향을 미친 변수의 중요도를 확인할 수 있다.
knowallworld.tistory.com
1> pca시 얼마만큼의 데이터 손실이 있는지 파악
pca.explained_variance_ratio_ # 데이터 반영 비율 확인 ==> 기존 데이터의 0.08 정도의 정보만 반영한다.
# ==> 정보의 손실이 크다.0.033314 0.049924 ==> 0.08 정도의 정보만 반영
2> 엘보우기법과 비슷한 주성분 개수 지정
var_ratio = [] # 빈 리스트 생성
for i in range(100, 550 , 50): # 순회
pca = PCA(n_components= i) # 주성분 개수 지정
pca.fit_transform(X_train_scaled)
ratio = pca.explained_variance_ratio_.sum() # 데이터 반영 비율 합
var_ratio.append(ratio)
pca = PCA(n_components= 400 , random_state= 100) # 주성분 개수 지정
pca.fit(X_train_scaled) # 학습
X_train_scaled_pca= pca.transform(X_train_scaled) # 변환
X_test_scaled_pca = pca.transform(X_test_scaled) # 변환
model_2 = RandomForestClassifier(random_state= 100)
start_time = time.time()
model_2.fit(X_train_scaled_pca , y_train)
print(time.time() - start_time)==> 시간이 줄어들었다.
pred_2 = model_2.predict(X_test_scaled_pca) # 예측
accuracy_score(y_test , pred_2) # 정확도 확인==> 정확도도 높아졌다
proba_2 = model_2.predict_proba(X_test_scaled_pca) # 예측
roc_auc_score(y_test , proba_2[:,1])==> AUC도 높아졌다.
출처 : 데싸노트의 실전에서 통하는 머신러닝
(Golden Rabbit , 저자 : 권시현)
※혼자 공부용
'머신러닝 > 머신러닝_이론' 카테고리의 다른 글
| [LogisticRegression()활용] 하이퍼파라미터 값 알아보기★ROC-AUC★L1,L2규제 (0) | 2023.05.27 |
|---|---|
| [머신러닝 이론 01-01] 머신러닝과 통계학 (0) | 2023.03.22 |
| [PYTHON - 머신러닝_결정트리]★예측력, 설명력★빈칸 제거_skipinitialspace★지니 인덱스★오버피팅,언더피팅★트리의 깊이★ (0) | 2023.01.25 |
| [PYTHON - 머신러닝_나이브베이즈]★string.punctuation 특수문자★join함수★nltk.download('stopword')★불용어★ MultinomialNB★오차행렬 (0) | 2023.01.25 |
| [PYTHON - 머신러닝_KNN알고리즘]★value_counts()★고윳값 판단★결측치★스케일링 (0) | 2023.01.24 |