1. 결정 트리(Decision Tree)
==> 관측값과 목표값을 연결시켜주는 예측 모델로서 나무 모양으로 데이터를 분류
==> 수많은 트리 기반 모델의 기본 모델
==> 선형 모델은 각 변수에 대한 기울기값들을 최적화하여 모델을 만들어 나감.
==> 트리모델에서는 각 변수의 특정 지점을 기준으로 데이터를 분류해가면서 예측모델 만든다.
예측력 : 모델 학습을 통해 얼마나 좋은 예측치를 보여주는가를 의미
설명력 : 학습된 모델을 얼마나 쉽게 해석할 수 있는지를 뜻한다.
==> 알고리즘의 복잡도가 증가할 수록 예측도는 증가 , 설명력은 감소
ex) 의학 데이터에 대한 질병 발병률에 대한 예측 모델 ==> 설명력이 좋은 알고리즘이 적합
장점 :
㉠ 데이터에 대한 가정이 없는 모델이다. 선형 모델은 정규분포에 대한 가정이나 독립변수와 종속변수의 선형 관계 등을 가정으로 하는 모델이지만, 결정 트리는 데이터에 대한 가정이 없어서 자유롭게 적용할 수 있다.
㉡ 아웃라이어에 영향을 거의 받지 않는다.
㉢ 트리 그래프를 통해서 직관적으로 이해하고 설명할 수 있다.
단점 :
㉠ 트리 기반 모델들에 비하면 예측력이 떨어진다.
2. 데이터 확인
file_url = "https://media.githubusercontent.com/media/musthave-ML10/data_source/main/salary.csv"
data = pd.read_csv(file_url , skipinitialspace= True) #빈칸 모두 제거
data.head()==> skipinitialspace =True ==> 앞에 있는 빈칸 제거하여 갖고오기
data.describe(include= 'all') #object형이 포함된 통계정보 출력==> object형이 포함된 통게정보 출력

==> unique, top , freq 행이 추가되었다. ==> 오직 object형의 변수들만을 위한 것이다. 기존의 숫자형 변수들은 NaN으로 처리되어 있다.
unique : 고윳값
top : 각 변수별로 가장 많이 등장하는 value
freq : top에 나와있는 value가 해당 변수에서 총 몇 건인지
3. 전처리 : 범주형 데이터
data['class'] = data['class'].map({'<=50K' : 0 , '>50K' : 1}) # 숫자로 변환obj_list = []
for i in data.columns : #순회
if data[i].dtype == 'object' : #데이터타입이 object이면
obj_list.append(i) #리스트에 변수 이름을 추가
obj_list==> data type이 object 인거 obj_list에 추가
['workclass',
'education',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'native-country']
for i in obj_list:
if data[i].nunique() >= 10: #변수의 고윳값이 10보다 크거나 같으면
print(i , data[i].nunique()) #컬럼명과 고윳값 개수 출력education 16
occupation 14
native-country 41
np.sort(data['education-num'].unique()) #고윳값을 오름차순으로 확인data[data['education-num'] == 1] # 값이 1인 (True)행만 필터링
data[data['education-num'] == 1]['education'].unique()
#education-num이 1인 데이터들의 education 고윳값 확인
array([ 'Preschool'] , dtype = object)
for i in np.sort(data['education-num'].unique()):
print(i, data[data['education-num'] ==i]['education'].unique() )==> education-num이 고윳값별 education의 고윳값 확인
1 [' Preschool']
2 [' 1st-4th']
3 [' 5th-6th']
4 [' 7th-8th']
5 [' 9th']
6 [' 10th']
7 [' 11th']
8 [' 12th']
9 [' HS-grad']
10 [' Some-college']
11 [' Assoc-voc']
12 [' Assoc-acdm']
13 [' Bachelors']
14 [' Masters']
15 [' Prof-school']
16 [' Doctorate']
data.groupby('native-country').mean().sort_values('class')==> 그룹별 평균 계산 후 class 기준으로 오름차순 정렬
※ 더미 변수를 설명할 때, 범주형 데이터를 무작정 숫자로 치환하여 모델링하는 방법은 좋지 않다.
but. 트리 기반의 모델을 사용 할 때 연속된 숫자들도 연속적으로 받아들이기 보다는 일정 구간을 나누어 받아들인다.
==> 트리가 충분히 깊어지면 범주형 변수를 숫자로 바꾼다고 해도 문제가 없다.
country_group = data.groupby('native-country').mean()['class']
country_group= country_group.reset_index() #인덱스를 변수로 불러냄
country_group
4. 결측치 처리 및 더미 변수 변환
data.isna().mean() #결측치 비율 확인
data['native-country'] = data['native-country'].fillna(-99)
# native-country의 경우 각 국가별 class의 평균값으로 대체한 상황
# 트리 기반 모델에서는 결측치를 임의의 숫자로 채워도 괜찮다.native-country의 경우 각 국가별 class의 평균값으로 대체한 상황 ==> 트리 기반 모델에서는 결측치를 임의의 숫자로 채워도 괜찮다.
data['workclass'] = data['workclass'].fillna('Private')
# 결측치를 Private(특정 값이 대부분을 차지하는 경우라면 해당 값으로 결측치를 채워주는 방법으로 대체)==> 결측치를 Private(특정 값이 대부분을 차지하는 경우라면 해당 값으로 결측치를 채워주는 방법으로 대체)
data['occupation'] = data['occupation'].fillna('Unknown')
# 어떤 특정값이 압도적으로 많다고 하기가 어렵다. 이런 경우에는 별도의 텍스트 'Unknown'으로 채운다.==> 어떤 특정값이 압도적으로 많다고 하기가 어렵다. 이런 경우에는 별도의 텍스트 'Unknown'으로 채운다.
data = pd.get_dummies(data , drop_first=True) #더미 변수로 변환
datadrop_first = True ==> 더미 변수의 갯수를 줄여준다.
5. 모델링 및 평가하기
from sklearn.model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split(data.drop('class',axis =1 ) , data['class'] , test_size= 0.4 , random_state= 100)==> 독립변수('class' 열 제외한 모든 열) , 종속변수 ('class') 열
==> X_train : 학습 시킬 독립변수
==> y_train : 학습 시킬 종속변수
==> X_test : 예측 대상
==> y_test : 실제 정보
==> pred : 예측 값
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier() # 모델 객체 생성
model.fit(X_train , y_train) # 학습
pred = model.predict(X_test) # 예측
from sklearn.metrics import accuracy_score
accuracy_score(y_test , pred) # 정확도 계산
==> 0.8134309259354047
6. 분류 결정 트리
==> 분류와 회귀는 각기 다른 로직의 적용
분류 : DecisionTreeClassifier는 각 노드의 순도가 가장 높은 방향으로 분류한다.
순도 : 한 노드 안에 여러 종류가 아닌 한 종류의 목푯값만 있는 상태에 대한 지표이다.
ex) 노드 안에 사과 3개와 복숭아 3개가 있으면 두 과일이 반씩 있기 때문에 순도가 낮다. 한 노드 안에 사과 3개와 복숭아 0개가 있다면 순도가 높다고 볼 수 있다.
==> 순도를 평가하는 지표로는 지니 인덱스와 교차 엔트로피가 있다.
1> 지니 인덱스

==> 지니 인덱스는 각 노드에 대해서 계산되며, p는 노드 안에 특정 아이템의 비율이다.
EX-01 ) 사과 2, 복숭아 2 일때 계산
==> 각각 50% 이므로 , 1- (0.5**2 + 0.5**2) = 0.5
EX-02 ) 사과 1, 복숭아 3 일때 계산
==> 각각 25% , 75% 이므로 , 1- (0.25**2 + 0.75**2) = 1- 0.625 = 0.375
EX-03 ) 사과 0, 복숭아 4 일때 계산
==> 각각 0% , 100%이므로, 1 - (0**2 + 1**2) = 0
==> 순도가 높을수록 지니 인덱스는 낮은 값을 보인다.
==> 결정 트리에서는 지니 인덱스가 가장 낮은 값이 나오는 특정 변수의 특정 값을 기준으로 노드를 분류해 간다.
2> 교차 엔트로피

EX-01 ) 사과 2, 복숭아 2 일때 계산
==> 각각 50% 이므로 , - ( 0.5*Log_2(0.5) + 0.5*Log_2(0.5)) = - ( -0.5 - 0.5) = 1
EX-02 ) 사과 1, 복숭아 3 일때 계산
==> 각각 25% , 75% 이므로 , - (0.25*Log_2(0.25) + 0.75*Log_2(0.75)) = 0.81127
- (0.25*np.log2(0.25) + 0.75*np.log2(0.75))
EX-03 ) 사과 0, 복숭아 4 일때 계산
==> 각각 0% , 100%이므로, -(0*log_2(0) + 1* log_2(1) ) = 0
==> 순도가 높을수록 교차 엔트로피는 낮은 값을 보인다. ==> 최대값은 1까지 나올 수 있다.
==> 사이킷런의 결정 트리에서는 기본값으로 지니 인덱스를 사용한다.
7. 매개변수 튜닝
오버피팅 : 예측 모델이 훈련 셋을 지나치게 잘 예측한다면 새로운 데이터를 예측 할 때 큰 오차를 유발 할 수 있다.
언더피팅 : 모델이 충분히 학습되지 않아 훈련셋에 대해서도 좋은 예측력을 내지 못하는 상황이다.
==> 결정 트리에서는 트리 깊이가 깊어질 수록, 수없이 많은 노드를 분류하여 모델을 만들수록 오버피팅 발생 가능성이 높다.
==> 이 문제를 해결하기 위해 결정 트리에서는 트리의 깊이를 제한하는 매개변수를 제공한다.
model = DecisionTreeClassifier()
model.fit(X_train , y_train)
train_pred = model.predict(X_train) #훈련셋 예측
test_pred = model.predict(X_test) #시험셋 예측
print('Train score : ' , accuracy_score(y_train , train_pred) , 'Test score : ' , accuracy_score(y_test , test_pred)) # 훈련셋 , 시험셋의 정확도 평가Train score : 0.9780242279474493 Test score : 0.8147617341454676
==> 훈련셋에서는 정확도가 매우 높지만, 시험셋에서는 상대적으로 낮다. 이 정도의 격차가 발생하면 오버피팅이 발생했다고 할 수 있다.
=> 격차를 줄이기 위해 시험셋에서 정확도를 올리는 방향으로 매개변수를 설정한다.
model = DecisionTreeClassifier(max_depth= 5) #모델 객체 생성
model.fit(X_train , y_train) #학습
train_pred = model.predict(X_train) #훈련 셋 예측
test_pred = model.predict(X_test) # 시험 셋 예측
print('Train score : ' , accuracy_score(y_train , train_pred) , 'Test score : ' , accuracy_score(y_test , test_pred)) # 훈련셋 , 시험셋의 정확도 평가Train score : 0.8540180856509129 Test score : 0.8499769667809797
==> 이전보다 Train score 값이 낮 아졌다. ==> 둘 사이의 차이는 매우 낮아졌다.
model = DecisionTreeClassifier(max_depth= 7) #모델 객체 생성
model.fit(X_train , y_train) #학습
train_pred = model.predict(X_train) #훈련 셋 예측
test_pred = model.predict(X_test) # 시험 셋 예측
print('Train score : ' , accuracy_score(y_train , train_pred) , 'Test score : ' , accuracy_score(y_test , test_pred)) # 훈련셋 , 시험셋의 정확도 평가Train score : 0.8598532673605187 Test score : 0.8541741311357937
==> 이상적인 트리의 깊이를 지정하여 오버피팅을 낮추는 노력을 해야한다.
8. 트리 그래프
from sklearn.tree import plot_tree
fig = plt.figure(figsize = (15,8)) # 그래프 크기 설정
ax = plot_tree(model) # 트리 그래프 출력
plt.show()
==> 이 모델은 마지막에 훈련시킨 max_depth 7의 결과물이다.
from sklearn.tree import plot_tree
fig = plt.figure(figsize = (30,15)) # 그래프 크기 설정
ax = plot_tree(model , max_depth= 3 , fontsize = 15) # 트리 그래프 출력
plt.show()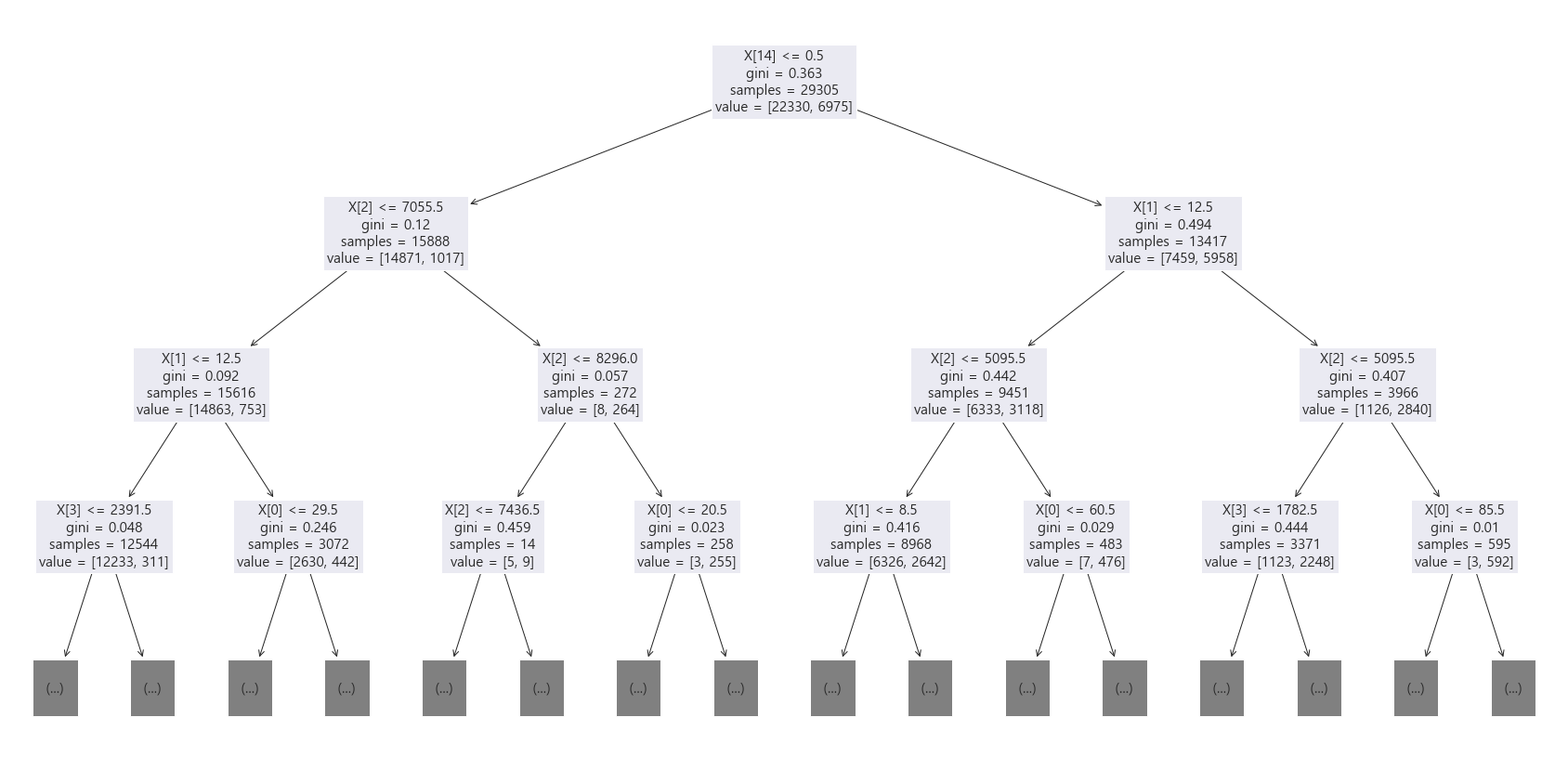
from sklearn.tree import plot_tree
fig = plt.figure(figsize = (30,15)) # 그래프 크기 설정
ax = plot_tree(model , max_depth= 3 , fontsize = 15 , feature_names= X_train.columns) # 트리 그래프 출력
plt.show()
==> 첫 번째 노드에는 분류 기준, 지니 인덱스(gini) , 총 데이터 수(samples), value는 목표값 0과 1이 각각 몇 개씩인지를 표현
==> Married-civ-spouse <= 0.5 기준으로 나누었다. ==> 조건에 맞으면 왼쪽 , 아니면 오른쪽 분류
==> 두 번째 노드의 gini 인덱스는 0.12로 나누어졌다.(순도가 높아졌다.) ==> value값(종속변수, class)을 보면 0인 경우가 훨씬 많도록 분류 되었다.
출처 : 데싸노트의 실전에서 통하는 머신러닝
(Golden Rabbit , 저자 : 권시현)
※혼자 공부용
'머신러닝 > 머신러닝_이론' 카테고리의 다른 글
| [머신러닝 이론 01-01] 머신러닝과 통계학 (0) | 2023.03.22 |
|---|---|
| [PYTHON - 머신러닝_주성분 분석_PCA]★비지도학습★차원 축소★반영 비율 확인 (0) | 2023.01.30 |
| [PYTHON - 머신러닝_나이브베이즈]★string.punctuation 특수문자★join함수★nltk.download('stopword')★불용어★ MultinomialNB★오차행렬 (0) | 2023.01.25 |
| [PYTHON - 머신러닝_KNN알고리즘]★value_counts()★고윳값 판단★결측치★스케일링 (0) | 2023.01.24 |
| [PYTHON - 머신러닝_로지스틱선형회귀]★로지스틱 선형회귀★상관관계★원-핫 인코딩★정확도★ (1) | 2023.01.23 |