[PYTHON - 머신러닝_캐글_실습]자전거 대요 수요 예측★datetime★weekday()★calendar★map 변환★로그변환★subplots★히트맵★회귀선_regplot()★pointplot★
1. 미션
날짜, 계절 ,근무일 여부 , 날씨 , 온도, 체감 온도, 풍속 데이터를 활용하여 자전거 대여 수요 예측
2. 피처와 타깃값
피처(feature) : 원하는 값을 예측하기 위해 활요하는 데이터 ==> 열(column) 의미
타깃값(target value) : 예측해야 할 값 ==> 목표값 , 목표변수, 타깃변수
3. 날짜 변환
from datetime import datetime
import calendar
print(train['date'][100]) # 날짜
print(datetime.strptime(train['date'][100] , '%Y-%m-%d')) # datetime 타입으로 변경
# 정수로 요일 변환
print(datetime.strptime(train['date'][100] , '%Y-%m-%d').weekday())
# 문자열로 요일 변환
print(calendar.day_name[datetime.strptime(train['date'][100] , '%Y-%m-%d').weekday()])==> datetime.strptime() ==> datetime 타입으로 변경

4. map 활용하여 DataFrame 값들 변환
train['season'] = train['season'].map({1 : 'Spring' , 2: 'Summer' , 3:'Fall' , 4:'Winter'})
train['weather'] = train['weather'].map({1 : 'Clear' , 2 : 'Mist , Few clouds' , 3: 'Light Snow , Rain , Thunderstorm' , 4 : 'Heavy Rain , Thunderstorm , Snow , Fog'})
train[['season' , 'weather']]
5. 로그 변환
mpl.rc('font' , size = 15) # 폰트 크기를 15로 설정
sns.displot(train['count'])
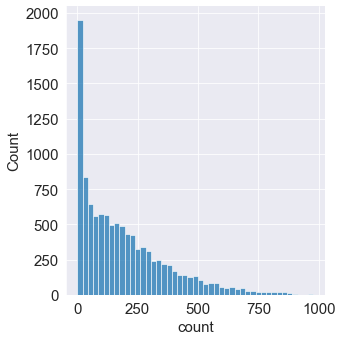
==> x축은 타깃값인 count를 나타내고, y축은 총 개수를 나타낸다. 분포도를 보면 타깃값인 count가 0 근처에 몰려 있다.
==> 분포가 왼쪽으로 많이 편향되어 있어 회귀 모델이 좋은 성능을 내려면 데이터가 정규분포를 따라야만 한다.
==> 이를 그대로 사용하여 모델링한다면 좋은 성능을 기대하기 어렵다.
==> 데이터 분포를 정규분포에 가깝게 만들기 위해 가장 많이 사용되는 방법은 로그변환이다. 로그 변환은 count 분포와 같이 데이터가 왼쪽으로 편향되어 있을 때 사용한다.
sns.displot(np.log(train['count'])) # 변환 전보다 정규분포에 가까워졌다. 타깃값 분포가 정규분포에 가까울 수록 회귀 모델 성능이 좋다.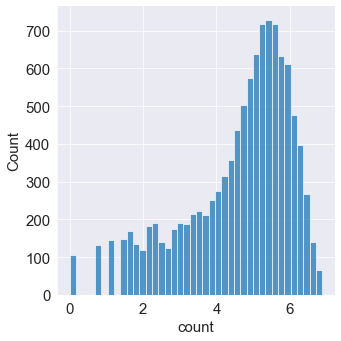
==> 마지막에는 지수변환하여 count로 복원해야만 한다!!!
6. subplots 여러개 그래프 그리기!!!
mpl.rc('font' , size = 14) # 폰트 크기 설정
mpl.rc('axes' , titlesize = 15) # 각 축의 제목 크기 설정
figure , axes = plt.subplots(nrows = 3 , ncols= 2) # 3행 2열 Figure 생성
plt.tight_layout() # 그래프 사이에 여백 확보
figure.set_size_inches(10 , 9) # 전체 Figure 크기를 10x9 인치로 설정https://knowallworld.tistory.com/244
★Seaborn에서의 Subplots★이항확률의 근사 확률★푸아송분포★기초통계학-[Chapter05 - 이산확률분포
1. 이항확률의 근사 확률 ==> 시행 횟수 n이 30보다 큰 경우의 이항확률을 구하기 위한 푸아송 분포 이용한 근사 확률 구할 수 있다. ==> 충분히 큰 n에 대햐여 np =뮤 가 일종하면 B(n ,p ) ~~ P(뮤)이므
knowallworld.tistory.com
==> 여러개 그래프 그리기

==> 객체 6개가 3행 2열로 구성된 배열이 출력되었다.
plt.tight_layout() # 그래프 사이에 여백 확보==> 그래프 사이에 여백 확보
axes[1,0].tick_params(axis= 'x' , labelrotation = 90)
axes[1,1].tick_params(axis='x' , labelrotation = 90)==> x축 라벨 회전
7. 막대그래프 , barplot
mpl.rc('font' , size = 14) # 폰트 크기 설정
mpl.rc('axes' , titlesize = 15) # 각 축의 제목 크기 설정
figure , axes = plt.subplots(nrows = 3 , ncols= 2) # 3행 2열 Figure 생성
plt.tight_layout() # 그래프 사이에 여백 확보
figure.set_size_inches(10 , 9) # 전체 Figure 크기를 10x9 인치로 설정
sns.barplot(x='year' , y ='count' , data = train , ax = axes[0,0])
sns.barplot(x='month' , y ='count' , data = train , ax = axes[0,1])
sns.barplot(x='day' , y ='count' , data = train , ax = axes[1,0])
sns.barplot(x='hour' , y ='count' , data = train , ax = axes[1,1])
sns.barplot(x='minute' , y ='count' , data = train , ax = axes[2,0])
sns.barplot(x='second' , y ='count' , data = train , ax = axes[2,1])
axes[0,0].set(title ='Rental amounts by year')
axes[0,1].set(title='Rental amounts by month')
axes[1,0].set(title='Rental amounts by day')
axes[1,1].set(title='Rental amounts by hour')
axes[2,1].set(title='Rental amounts by minute')
axes[2,1].set(title='Rental amounts by second')
axes[1,0].tick_params(axis= 'x' , labelrotation = 90)
axes[1,1].tick_params(axis='x' , labelrotation = 90)
plt.show()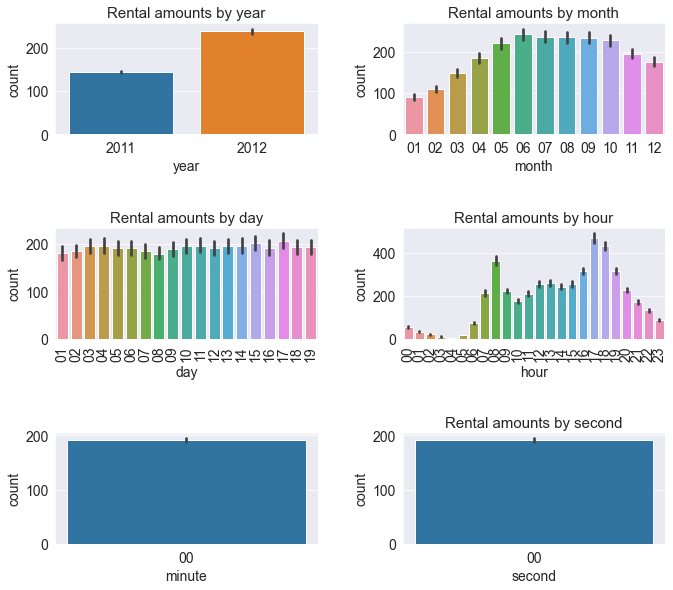
8. 박스 플롯 , boxplot
==> 박스플롯은 범주형 데이터에 따른 수치형 데이터 정보를 나타내는 그래프이다. 막대 그래프보다 더 많은 정보를 제공하는 특징이 있다.
==> 계절, 날씨 , 공휴일 , 근무일(범주형 데이터)별 대여 수량(수치형 데이터)을 박스플롯으로 그리기.
mpl.rc('font' , size = 14) # 폰트 크기 설정
mpl.rc('axes' , titlesize = 15) # 각 축의 제목 크기 설정
figure , axes = plt.subplots(nrows = 2 , ncols= 2) # 3행 2열 Figure 생성
plt.tight_layout() # 그래프 사이에 여백 확보
figure.set_size_inches(10 , 9) # 전체 Figure 크기를 10x9 인치로 설정
sns.boxplot(x='season' , y ='count' , data = train , ax = axes[0,0])
sns.boxplot(x='weather' , y ='count' , data = train , ax = axes[0,1])
sns.boxplot(x='holiday' , y ='count' , data = train , ax = axes[1,0])
sns.boxplot(x='workingday' , y ='count' , data = train , ax = axes[1,1])
axes[0,0].set(title ='Box Plot On Count Across Season')
axes[0,1].set(title='Box Plot On Count Across Weather')
axes[1,0].set(title='Box Plot On Count Across Holiday')
axes[1,1].set(title='Box Plot On Count Across Workingday')
#
axes[0,1].tick_params(axis= 'x' , labelrotation = 10)
plt.show()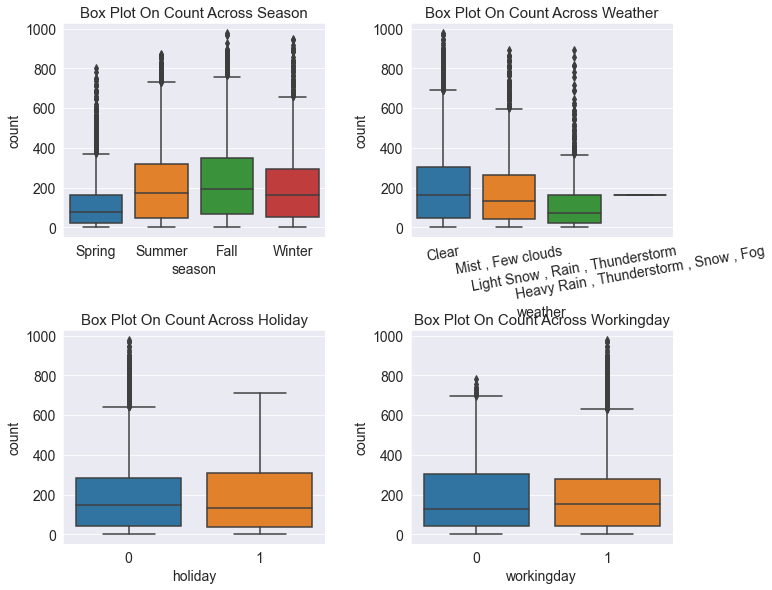
https://knowallworld.tistory.com/220
annotate★IQR★boxplot★z-점수와 분위수★기초통계학-[Chapter03 - 09]
1. z-점수(표준점수_ Standardized score) 산포도 : 자료 중심위치를 나타내는 척도와 밀집 정도 또는 흩어진 정도를 나타낸다. ==> 수능을 치르게 되면 상대적인 위치 관계 이용 ==> ex) 원점수, 표준점수
knowallworld.tistory.com
==> 자전거 대여 수량은 봄에 가장 적고, 가을에 가장 많다.
==> 날씨로는 화창할때 가장 많다.
==> 공휴일이 아닐때(0) 보다 공휴일(1) 일때 갯수가 조금 많다. 공휴일 아닐때 이상치값이 많다.
==> 근무일 일때 이상치값이 많다.
9. 포인트 플롯 , pointplot
mpl.rc('font' , size = 11)
figure , axes = plt.subplots(nrows=5) # 5행 1열
figure.set_size_inches(12,18)
# STEP 2 : 서브플롯 할당
# 근무일 , 공휴일 , 요일 ,계절 , 날씨에 따른 시간대별 평균 대여 수량 포인트플롯
sns.pointplot(x='hour' , y='count' , data = train , hue='workingday' , ax= axes[0]) # hue로 비교하고 싶은 피처 전달
sns.pointplot(x='hour' , y='count' , data = train , hue='holiday' , ax= axes[1])
sns.pointplot(x='hour' , y='count' , data = train , hue='weekday' , ax= axes[2])
sns.pointplot(x='hour' , y='count' , data = train , hue='season' , ax= axes[3])
sns.pointplot(x='hour' , y='count' , data = train , hue='weather' , ax= axes[4])
==> hue로 비교하고 싶은 피처 전달

==> 출퇴근 시간에 대여 수량이 많고, 쉬는 날에는 오후 12~2시에 가장 많다.
==> 공휴일, 요일에 따른 포인트 플롯도 근무일 여부에 다른 포인트플롯과 비슷하다.
==> 계절로는 가을에 가장 많고, 봄에 가장 적다.
==> 맑을때가 가장 많고, 폭우 폭설이 내릴때 18시에 대여 건수가 존재한다. ==> 이상치 데이터로써 제거하는 편이 좋다.
10. 회귀선을 포함한 산점도 그래프
==> 수치형 데이터인 온도, 체감 온도 , 풍속 , 습도별 대여 수량을 '회귀선을 포함한 산점도 그래프' 로 그리기.
mpl.rc('font' , size = 15)
figure, axes = plt.subplots(nrows = 2 , ncols =2) # 2행 2열
plt.tight_layout()
figure.set_size_inches(7,6)
#STEP 2 : 서브플롯 할당
# 온도, 체감온도 , 풍속, 습도 별 대여 수량 산점도 그래프
sns.regplot(x = 'temp' , y='count' , data= train, ax= axes[0,0] , scatter_kws= {'alpha' : 0.2} , line_kws={'color' : 'blue'})
# scatter_kws는 산점도 그래프의 점의 투명도를 조절한다.
sns.regplot(x = 'atemp' , y='count' , data= train, ax= axes[0,1] , scatter_kws= {'alpha' : 0.2} , line_kws={'color' : 'blue'})
sns.regplot(x = 'windspeed' , y='count' , data= train, ax= axes[1,0] , scatter_kws= {'alpha' : 0.2} , line_kws={'color' : 'blue'})
sns.regplot(x = 'humidity' , y='count' , data= train, ax= axes[1,1] , scatter_kws= {'alpha' : 0.2} , line_kws={'color' : 'blue'})
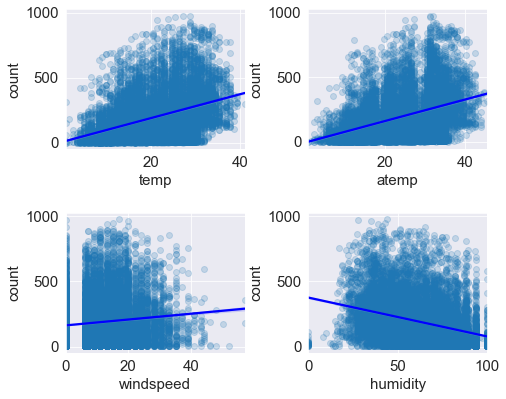
==> 온도가 높을 수록 대여 수량이 많다.
==> 습도는 낮을수록 대여를 많이 한다.
==> 풍속이 셀수록 대여 수량이 많다(?) ==> windspeed에 결측값이 많아 풍속이 0인 데이터가 많은 것 ==> 전처리 필요
11. 히트맵
==> 수치형 데이터(temp, atemp , humidity, windspeed , count) 의 상관관계 파악
train[['temp' , 'atemp' , 'humidity' , 'windspeed' , 'count']].corr()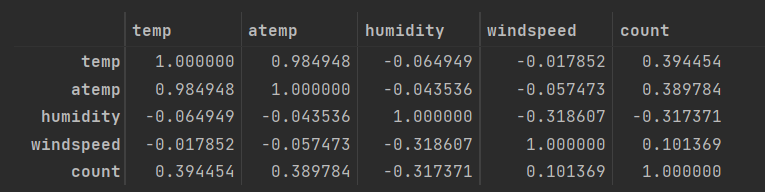
corrMat = train[['temp' , 'atemp' , 'humidity' , 'windspeed' , 'count']].corr()
fig , ax = plt.subplots()
fig.set_size_inches(10,10)
sns.heatmap(corrMat , annot = True)
ax.set(title = 'Heatmap of Numerical Data')==> annot = True 로 상관계수 값 안에 집어 넣는다.
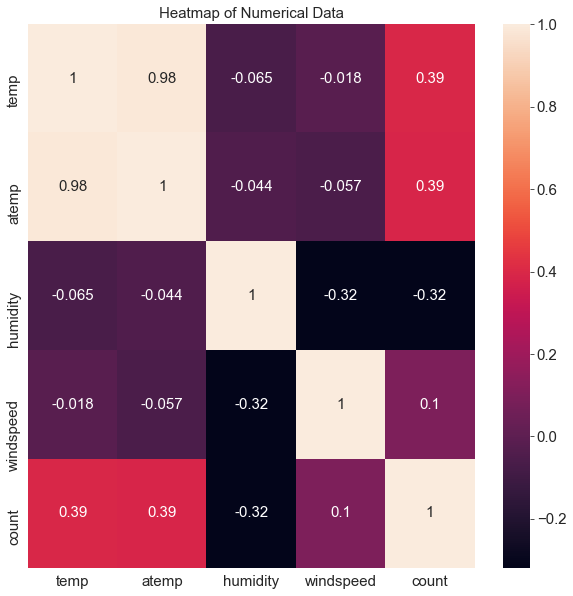
==> 온도가 높을 수록 대여 수량이 많다.
==> 습도와 대여 수량은 음수이니 습도가 '낮을 수록' 대여 수량이 많다.
출처 : 머신러닝·딥러닝 문제해결 전략
(Golden Rabbit , 저자 : 신백균)
※혼자 공부용