[PYTHON - 머신러닝_캐글_실습-01]안전 운전자 예측★결측값 셀땐 missingno★서브플롯 편하게 하고싶으면gridspec★연속형 데이터 나누는데 사용하는 pd.cut()★
1. 주제
https://www.kaggle.com/competitions/porto-seguro-safe-driver-prediction/data
Porto Seguro’s Safe Driver Prediction | Kaggle
www.kaggle.com
==> 자동차 보험과 관련해서 운전자가 보험금을 청구할 확률을 정확히 예측하는 모델 생성
2. 탐색적 데이터 분석(EDA)

train.info()
#ps
#ind,reg , car ,calc ==> 분류
#01, 02 ,03 ==> 분류별 일련번호
# _bin , _cat ==> 이진피처 , 명목형 피처 , 생략시 순서형 피처 또는 연속형 피처
==> 요약표에 non-null 이라 되어있지만 , -1로 표시되어 있으므로, -1을 np.NaN으로 변환한 다음 개수를 세야한다.
1. 결측값 파악
import numpy as np
import missingno as msno
# 훈련데이터 복사본에서 -1을 np.NaN으로 변환
train_copy = train.copy().replace(-1 , np.NaN)
# 결측값 시각화(처음 28개만)
msno.bar(df=train_copy.iloc[: , 1:29] , figsize=(13,6))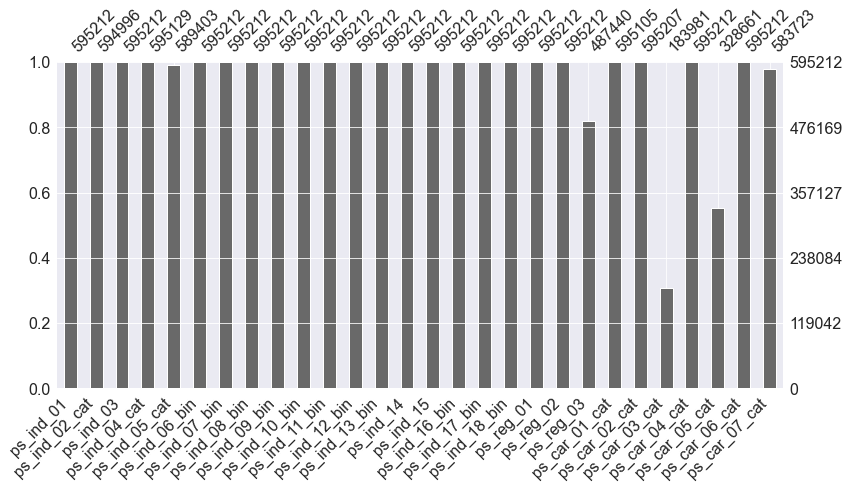
==> ps_reg_03 , ps_car_03_cat , ps_car_05_cat 에 결측값이 존재한다.

msno.matrix(df=train_copy.iloc[:, 1:29] , figsize=(13,6))
==> 결측값 매트릭스 형태로 시각화(22개의 결측값 없는 열수 , 전체 28개 열)
2. 피처 요약표
def resumetable(df):
print(f'데이터셋 형상 : {df.shape}')
summary = pd.DataFrame(df.dtypes , columns = ['데이터 타입'])
summary['결측값 개수'] = (df == -1).sum().values # 피처별 -1 개수
summary['고윳값 개수'] = df.nunique().values
summary['데이터 종류'] = None
for col in df.columns:
if 'bin' in col or col == 'target':
summary.loc[col , '데이터 종류'] = '이진형'
elif 'cat' in col:
summary.loc[col , '데이터 종류'] = '명목형'
elif df[col].dtype == 'float64':
summary.loc[col , '데이터 종류'] = '연속형'
elif df[col].dtype == 'int64':
summary.loc[col, '데이터 종류'] = '순서형'
return summarysummary = resumetable(train)
summary==> (df == -1).sum().values ==> 피처의 값이 -1인 값들은 더한 값
==> df.nunique().values ==> 피처의 고윳값 개수들에 대한 값
==> bin(이진피처) , 피처이름이 target 일때 , 데이터 종류 열을 이진형으로 변경

3. 데이터 시각화
https://knowallworld.tistory.com/203
Plt, Fig, Seaborn 이해[Python]★기초통계학-[Chapter02 - 연습문제_02]
p46 2번문제 어느 대학에서 교내 음주의 찬성 여부를 재학생 100명 대상으로 조사 a = '찬성 찬성 찬성 무응답 찬성 무응답 찬성 반대 무응답 찬성 반대 무응답 찬성 반대 찬성 반대 찬성 찬성 무응
knowallworld.tistory.com
==> 막대 그래프 조정하기
def write_percent(ax , total_size):
# 도형 객체를 순회하며 막대 그래프 상단에 타깃값 비율 표시
for patch in ax.patches:
height = patch.get_height() # 도형 높이(데이터 개수)
width = patch.get_width() # 도형 너비
left_coord = patch.get_x() # 도형 왼쪽 테두리의 x축 위치
percent = height/total_size*100 # 타깃값 비율
# (x, y) 좌표에 텍스트 입력
ax.text(left_coord + width/2.0, # x축 위치
height + total_size*0.001, # y축 위치
'{:1.1f}%'.format(percent), # 입력 텍스트
ha = 'center' ) # 가운데 정렬
mpl.rc('font' , size = 15)
plt.figure(figsize=(7,6))
ax = sns.countplot(x='target', data = train)
write_percent(ax , len(train)) # 비율 표시
ax.set_title('Target Distribution')
==> 전체 운전자 중 3.6%만 보험금을 청구했다는 뜻이다. ==> 타깃값이 불균형하다.
==> 타깃값이 불균형하므로 비율이 작은 타깃값 1을 잘 예측하는 것이 중요하다.
1> 이진 피처
import matplotlib.gridspec as gridspec
def plot_target_ratio_by_features(df, features , num_rows , num_cols , size=(12,18)):
# features 는 데이터 종류
mpl.rc('font' , size= 9)
plt.figure(figsize = size) # 전체 Figure 크기 설정
grid = gridspec.GridSpec(num_rows , num_cols) # 서브플롯 배치
plt.subplots_adjust(wspace=0.3 , hspace=0.3) # 서브플롯 좌우/상하 여백 설정
for idx, feature in enumerate(features):
ax = plt.subplot(grid[idx])
# ax 축에 고윳값별 타깃값 1 비율을 막대 그래프로 그리기
sns.barplot(x=feature , y='target' , data = df , palette='Set2' , ax =ax)==> gridspec.GridSpec(num_rows , num_cols) ==> 서브플롯 배치
==>plt.subplots_adjust(wspace=0.3 , hspace=0.3) ==> 서브플롯 좌우/상하 여백 설정
bin_features = summary[summary['데이터 종류'] == '이진형'].index # 이진 피처
# 이진 피처 고윳값별 타깃값 1 비율을 막대 그래프로 그리기
plot_target_ratio_by_features(train , bin_features , 6 , 3) # 6행 3열로 배치==> plot_target_ratio_by_features( 데이터프레임 , x축 값 , 6행 , 3열)

==> ps_calc_06_bin 의 고윳값 0의 경우 타깃값 1 비율이 0.04 , 고윳값 1의 경우 타깃값 1 비율이 0.03 정도 된다.
==> 고윳값 별로 타깃값 비율이 다르므로, 타깃값을 추정하는 예측력이 있다.
==> 고윳값 별로 타깃값 비율의 차이가 없는 피처들과 신뢰구간이 넓은 피처들은 예측력이 없으므로 삭제한다.
2> 명목형 피처
nom_features = summary[summary['데이터 종류'] == '명목형'].index # 명목형 피처
plot_target_ratio_by_features(train , nom_features , 7 , 2) # 7행 2열
1) ps_ind_02_cat : 결측값 -1이 다른 고윳값들 보다 타깃값 1 비율이 크다.
==> 결측값을 다른 값으로 대체하면 모델 성능이 더 나빠질 수 있다. 결측값 자체가 타깃값에 대한 예측력이 있기 때문이다.
2) ps_car_02_cat : 고윳값 -1일때 타깃값 1 비율은 0%이다. 피처 값이 -1 이면 타깃값이 0이라고 판단해도 된다.
ord_features = summary[summary['데이터 종류'] == '순서형'].index # 순서형 피처
plot_target_ratio_by_features(train , ord_features , 8,2 ,(12,20)) # 8행 2열
==> ps_ind_14 의 경우 신뢰구간이 상당히 넓어 통계적 유효성이 떨어진다.
==> ps_calc_04 부터 ps_calc_14 까지는 모두 고윳값별 타깃값 비율이 거의 비슷하여 통계적 유효성이 떨어진다.
3> 연속형 피처
==> 연속형 피처는 연속된 값이므로 고윳값이 굉장히 많다. 고윳값별 타깃값 1 비율을 구하기 힘들다.
==> 값을 몇 개의 구간으로 나누어서 구간별 타깃값 1 비율을 알아본다.
==> 연속형 데이터를 구간으로 나누려면 판다스의 cut() 함수 활용
pd.cut([1.0 , 1.5 , 2.1 , 2.7 , 3.5 , 4.0], 3) # cut()함수를 활용해 여러 개의 값을 3개 구간으로 나누었다.
==> 연속형 데이터를 범주형 데이터로 바꾸는 효과가 있다.

cont_features = summary[summary['데이터 종류'] == '연속형'].index # 연속형 피처
plt.figure(figsize= (12,16))
grid = gridspec.GridSpec(5,2)
plt.subplots_adjust(wspace= 0.2 , hspace = 0.4) # 서브플롯 간 여백 설정
for idx , cont_feature in enumerate(cont_features):
#값을 5개 구간으로 나누기
train[cont_feature] = pd.cut(train[cont_feature] , 5)
ax = plt.subplot(grid[idx]) # 분포도를 그릴 서브플롯 설정
sns.barplot(x = cont_feature , y= 'target' , data = train , palette= 'Set2' , ax = ax)
ax.tick_params(axis ='x' , labelrotation =10 ) # x축 라벨 회전
==> 고윳값별로 타깃값 비율이 서로 다른 것들만 남기고, 비슷한것들은 삭제 한다!
train_copy = train_copy.dropna() # np.NaN 값 삭제plt.figure(figsize =(10 , 8))
cont_corr = train_copy[cont_features].corr() # 연속형 피처 간 상관관계
sns.heatmap(cont_corr, annot = True , cmap = 'OrRd') # 히트맵 그리기
==> 상관관계가 높은 피처가 있으면 삭제하는 것이 좋다. ==> 상관관계가 강하면 타깃값 예측력도 비슷하다.
출처 : 머신러닝·딥러닝 문제해결 전략
(Golden Rabbit , 저자 : 신백균)
※혼자 공부용