전체 글
-
[백준 파이썬 11003번]최솟값 찾기★VER2.0★시간초과 고려2022.12.29
-
[백준 파이썬 1253번]좋다★투 포인터 사용!! 값 비교하여★2022.12.29
-
[백준 파이썬 1950번]주몽★정렬★인덱스값 구하기2022.12.28
-
[은행 필기대비 프로그래밍언어-01]2022.12.28
-
[은행 필기대비 자료구조-06] 검색 알고리즘★순차★이진★해싱★2022.12.28
[백준 파이썬 11003번]최솟값 찾기★VER2.0★시간초과 고려
https://www.acmicpc.net/problem/11003
11003번: 최솟값 찾기
N개의 수 A1, A2, ..., AN과 L이 주어진다. Di = Ai-L+1 ~ Ai 중의 최솟값이라고 할 때, D에 저장된 수를 출력하는 프로그램을 작성하시오. 이때, i ≤ 0 인 Ai는 무시하고 D를 구해야 한다.
www.acmicpc.net

VERSION 2.0
import sys
import collections
from collections import deque
N, L = map(int , sys.stdin.readline().rstrip().split(' '))
D_i = list(map(int , sys.stdin.readline().split(' ')))
# minimum = min(D_i)
# D_0 = A_0-3+1 ~ A_0
# D_2 = A_2-3+1 ~ A_2 ==> A_0 ~ A_2
# D_3 = A_3-3+1 ~ A_3 ==> A_1 ~ A_3
# D_4 = A_4-3+1 ~ A_4 ==> A_2 ~ A_4
# 123 234 345 456 ==> S = 6 P =3 ==> S-P+1 = 4 ==> 4번 구한다.
res = deque()
# N = 5 L = 3
# D_i = 1 2 3 4 5
# D_0 = 1 ==> i-L+1 < 0
# D_1 = 1 ==> 1-3+1 = -1 A_0 ~ A_1
for i in range(N):
while True:
if len(res)==0 or res[-1][0] <= D_i[i]:
break
else:
res.pop()
res.append((D_i[i] , i))
if res[0][1] <= i-L:
res.popleft()
print(res[0][0] , end = ' ')
#%%
시간초과
VERSION 1.0
import sys
import collections
from collections import deque
N, L = map(int , sys.stdin.readline().rstrip().split(' '))
D_i = list(map(int , sys.stdin.readline().split(' ')))
#minimum = min(D_i)
#D_0 = A_0-3+1 ~ A_0
#D_2 = A_2-3+1 ~ A_2 ==> A_0 ~ A_2
#D_3 = A_3-3+1 ~ A_3 ==> A_1 ~ A_3
#D_4 = A_4-3+1 ~ A_4 ==> A_2 ~ A_4
#123 234 345 456 ==> S = 6 P =3 ==> S-P+1 = 4 ==> 4번 구한다.
#N = 5 L = 3
#D_i = 1 2 3 4 5
#D_0 = 1 ==> i-L+1 < 0
#D_1 = 1 ==> 1-3+1 = -1 A_0 ~ A_1
end_idx = 0
for i in range(N):
idx = end_idx-L+1
if end_idx == 0 or idx<=0:
print(min(D_i[0:end_idx+1]) , end = ' ')
end_idx+=1
else:
print(min(D_i[idx: end_idx+1]) , end = ' ')
end_idx+=1
#%%
'Python(백준) > 배열' 카테고리의 다른 글
| ★VER2.0★max()안쓰고 구하기★[백준 파이썬 2562번 최대] (0) | 2023.03.27 |
|---|---|
| ★VER 2.0★min,max★1차원 배열 최소 최대숫자 알아보기 [백준 Python 10818번] (0) | 2023.03.27 |
| [백준 파이썬 12891번]좋다★DNA 비밀번호★WINDOWS SLIDING★VER2.0★시간초과 고려 (0) | 2022.12.29 |
| [Python] 백준 8958번 ox퀴즈 (0) | 2022.09.14 |
| [Python] 백준 2562번 최대값 (0) | 2022.09.14 |
[백준 파이썬 12891번]좋다★DNA 비밀번호★WINDOWS SLIDING★VER2.0★시간초과 고려
https://www.acmicpc.net/problem/12891
12891번: DNA 비밀번호
평소에 문자열을 가지고 노는 것을 좋아하는 민호는 DNA 문자열을 알게 되었다. DNA 문자열은 모든 문자열에 등장하는 문자가 {‘A’, ‘C’, ‘G’, ‘T’} 인 문자열을 말한다. 예를 들어 “ACKA”
www.acmicpc.net

VERSION 2.0
import sys
from collections import Counter
S, P = map(int , sys.stdin.readline().split(' '))
DNA = list(map(str, sys.stdin.readline().rstrip()))
find = dict(zip(['A' , 'C' ,'G' , 'T'] ,list(map(int, sys.stdin.readline().split(' ')))))
res = 0
start_idx , end_idx = 0 ,0
base = {'A' : 0 , 'C' : 0 , 'G' : 0 , 'T' : 0}
for start_idx in range(S-P+1): #3번 , 9 8 이라면 , 9-8+1 = 2번 ,
flag = True
if start_idx == 0:
for idx in range(P):
base[DNA[idx]]+=1 #start_idx가 0 , 시작 지점일때 , 잘리는 곳 까지 +1 시킨다.
else:
base[DNA[start_idx + P - 1]] +=1 #start_idx가 1~ 일경우 DNA 리스트의 있는 맨끝자리만 +=1 시켜줘야한다.
base[DNA[start_idx-1]] -=1 #start_idx 의 0부분 과 같이 이전 부분은 자른다.
for t in list(find.keys()):
if base[t] < find[t]:
flag = False
break
if flag:
res+=1
print(res)
#%%
==> WINDOWS SLIDING의 경우 고정된 리스트에서 맨 앞꺼 하나씩 자르고, 뒤에꺼 추가하는 방식이다!!!
시간초과
VERSION 1.0
import sys
from collections import Counter
S, P = map(int , sys.stdin.readline().split(' '))
DNA = list(map(str, sys.stdin.readline().rstrip()))
find = dict(zip(['A' , 'C' ,'G' , 'T'] ,list(map(int, sys.stdin.readline().split(' ')))))
res = 0
i = 0
while True:
j = P+i
if j <= S :
DNA_cut = DNA[i:j]
d = dict(Counter(DNA_cut))
res+=1
i+=1
for k,v in d.items():
# print(d[k])
if d[k] < find[k]:
res-=1
break
else:
break
print(res)
#%%==> dict(zip(리스트1 , 입력받는 리스트) )
==> 리스트 split ==> [시작 인덱스 : 끝 인덱스+ 1]
'Python(백준) > 배열' 카테고리의 다른 글
| ★VER 2.0★min,max★1차원 배열 최소 최대숫자 알아보기 [백준 Python 10818번] (0) | 2023.03.27 |
|---|---|
| [백준 파이썬 11003번]최솟값 찾기★VER2.0★시간초과 고려 (0) | 2022.12.29 |
| [Python] 백준 8958번 ox퀴즈 (0) | 2022.09.14 |
| [Python] 백준 2562번 최대값 (0) | 2022.09.14 |
| [백준 파이썬 4344번]1차원 배열, 평균은 넘겠지 ★객체LIST저장방법★but아직 미구현 (0) | 2021.07.31 |
[백준 파이썬 1253번]좋다★투 포인터 사용!! 값 비교하여★
https://www.acmicpc.net/problem/1253
1253번: 좋다
첫째 줄에는 수의 개수 N(1 ≤ N ≤ 2,000), 두 번째 줄에는 i번째 수를 나타내는 Ai가 N개 주어진다. (|Ai| ≤ 1,000,000,000, Ai는 정수)
www.acmicpc.net

import sys
N = int(sys.stdin.readline())
A = sorted(list(map(int , sys.stdin.readline().split(' '))))
Res = 0
for k in range(N):
find = A[k]
i_index = 0
j_index = N -1
# if A[i] != A[j]:
while True:
if A[i_index] + A[j_index] == find :
if i_index != k and j_index != k: #자기 자신을 포함하지 않는?
Res +=1
break
elif j_index==k:
j_index -= 1
elif i_index==k:
i_index += 1
elif A[i_index]+ A[j_index] < find: #find 값보다 작을 경우 작은 값의 인덱스 증가 시킨다.
i_index += 1
elif A[i_index] + A[j_index] > find: #find 값 보다 클 경우 큰 값의 인덱스 감소 시킨다.
j_index -= 1
if i_index>= j_index:
break
print(Res)==>
EX) 5
0 0 2 2 2
==> 0(i 인덱스 : 0) +2( j 인덱스:3) = 2(k 인덱스 : 2)
==> 0(i 인덱스 : 0) +2(j 인덱스 : 4) = 2(k 인덱스: 3)
==> 0(i 인덱스 :0) + 2(j 인덱스 : 3) = 2(k 인덱스 : 4)
==> 3개 이다.
==> 0(i인덱스 : 0) + 2(j 인덱스 : 4) = 2(k 인덱스 : 4) 의 경우 자기자신을 포함시키면 안되므로 안된다!
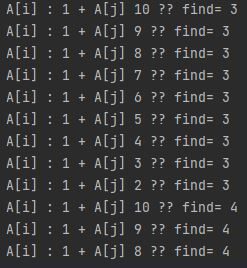
==> 투 포인터 사용법 기억하자!!!!!! ==> i는 start , j는 end , k는 찾을 값
==> 작은 값 , 큰 값 비교하자!
'Python(백준) > 누적합' 카테고리의 다른 글
| [백준 파이썬 1950번]주몽★정렬★인덱스값 구하기 (0) | 2022.12.28 |
|---|---|
| [백준 파이썬 11660번]구간 합 구하기5★2차원 누적 합(prefix sum) 알고리즘★ (0) | 2022.12.27 |
| [백준 파이썬 11659번]구간 합 구하기4★누적 합(prefix sum) 알고리즘★더한것에 특정 열 빼기! (0) | 2022.12.26 |
[Python] Input 함수에 범위를 지정해보자!(While 문 활용) 백준 14681번 사분면 문제★VER2.0
https://www.acmicpc.net/problem/14681
14681번: 사분면 고르기
점 (x, y)의 사분면 번호(1, 2, 3, 4 중 하나)를 출력한다.
www.acmicpc.net

VERSION 2.0
import sys
X = int(sys.stdin.readline())
Y = int(sys.stdin.readline())
if X>0 and Y>0:
print(1)
elif X<0 and Y>0:
print(2)
elif X<0 and Y<0:
print(3)
else:
print(4)
VERSION 1.0
format 함수를 활용하여 input함수의 문자열에 받아왔다.
if문을 통해 x축의 범위를 먼저 체크
else문을 통해 x축의 범위가 주어진 문제의 범위안에 들경우 다음 y값 받기
n = 1000
s = -1000
x = None
y = None
while True:
x = int(input(f"x축 값의 범위는 ({s} to {n}): "))
if (x<-1000 or x>1000):
print('x축 값의 범위를 다 시 입력하세요')
else :
while True:
y = int(input(f"y축 값의 범위는 ({s} to {n}): " ))
if (y<-1000 or y>1000):
print('y축 값의 범위를 다 시 입력하세요')
else:
break
break
if x>0 and y>0 :
print("1")
elif x<0 and y>0 :
print("2")
elif x<0 and y<0 :
print("3")
else :
print("4")
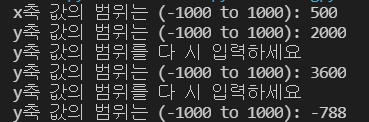
while문 안에 또 다른 while 문을 부여함으로써 이 범위를 구하는 문제를 구하게 되었다.
'Python(백준) > if' 카테고리의 다른 글
| [Python] set로 활용해보기(set활용) 백준 2480번 주사위세게 문제 (0) | 2022.09.13 |
|---|---|
| Python(백준)/if[Python] 백준 2525번 오븐 시계 (0) | 2022.06.24 |
| [Python] Input 함수에 범위를 지정해보자!_02번(While 문 활용) 백준 2884번 알람 문제 (0) | 2021.07.24 |
[외교부 인턴 일지- d+115 2022.12.26]데이터 분석 청년인재 양성 사업
할일
알코 자료구조까지
상식 1개
'인턴일지 > 외교부_일지' 카테고리의 다른 글
| [외교부 인턴 일지- d+139 2022.01.19]데이터 분석 청년인재 양성 사업 (0) | 2023.01.19 |
|---|---|
| [외교부 인턴 일지- d+128 2022.01.08]데이터 분석 청년인재 양성 사업 (0) | 2023.01.08 |
| [외교부 인턴 일지- d+109 2022.12.23]데이터 분석 청년인재 양성 사업 (1) | 2022.12.23 |
| [외교부 인턴 일지- d+100 2022.12.14]데이터 분석 청년인재 양성 사업 (0) | 2022.12.14 |
| [외교부 인턴 일지- d+86 2022.11.30]데이터 분석 청년인재 양성 사업 (0) | 2022.12.01 |
[백준 파이썬 1950번]주몽★정렬★인덱스값 구하기
https://www.acmicpc.net/problem/1940
1940번: 주몽
첫째 줄에는 재료의 개수 N(1 ≤ N ≤ 15,000)이 주어진다. 그리고 두 번째 줄에는 갑옷을 만드는데 필요한 수 M(1 ≤ M ≤ 10,000,000) 주어진다. 그리고 마지막으로 셋째 줄에는 N개의 재료들이 가진 고
www.acmicpc.net

import sys
N = int(sys.stdin.readline())
M = int(sys.stdin.readline())
gap = list(map(int , sys.stdin.readline().split(' ')))
gap = sorted(gap , reverse= False)
prefix = [0 for i in range(N+1)]
i = 0
j = N-1
count = 0
while True:
if gap[i] + gap[j] < M: #작으면 작은숫자의 인덱스 값 증가
i+=1
elif gap[i] + gap[j] > M: #크면 큰 숫자의 인덱스값 감소
j -= 1
elif gap[i]+ gap[j] == M:
count+=1
i+=1
j-=1
print(i , j)
print(gap[i] , gap[j])
if i >= j:
break
print(count)'Python(백준) > 누적합' 카테고리의 다른 글
| [백준 파이썬 1253번]좋다★투 포인터 사용!! 값 비교하여★ (0) | 2022.12.29 |
|---|---|
| [백준 파이썬 11660번]구간 합 구하기5★2차원 누적 합(prefix sum) 알고리즘★ (0) | 2022.12.27 |
| [백준 파이썬 11659번]구간 합 구하기4★누적 합(prefix sum) 알고리즘★더한것에 특정 열 빼기! (0) | 2022.12.26 |
[은행 필기대비 프로그래밍언어-01]
1.FORTRAN
==> 복잡한 수식 계산을 위해 시작된 과학 기술용 컴퓨터 프로그래밍 언어
2. Loader(로더)
==> 목적 프로그램을 주기억장치에 적재하여 실행 가능하도록 해준다.
목적프로그램 : 언어 번역기를 통해 소스 프로그램을 기계어로 번역
[은행 필기대비 자료구조-06] 검색 알고리즘★순차★이진★해싱★
1. 순차 검색(Linear Search)
==> 대상 데이터를 순서대로 하나씩 비교하면서 원하는 데이터를 찾는 검색 방식
==> 자료의 범위를 모르거나 자료가 정렬되어 있지 않아도 검색이 가능하다.
==> (n+1) /2
2. 제어 검색(Controlled Search)
1) 이진 검색(Binary Search)
==> 오름차순으로 정렬된 리스트에서 특정한 값의 위치를 찾는 알고리즘
==> 중간 값을 임의의 값으로 정하고, 그 값과 찾고자 하는 값의 대소비교를 하는 방식
==> 정렬된 리스트에서만 사용, 검색을 반복 할때마다 목표 값을 찾을 확률이 2배가 되므로 속도가 빠르고 효율이 좋다.
EX) 17, 28, 43, 67, 88, 92, 100 ==> 오름차순 ==> 43 찾기
1. 임의의 중간값 67 선정
2. 67 > 43 ==> 43이 왼쪽에 위치
3. (17 , 28 , 43) ==> 중간값 28 선정
4. 28< 43 ==> 43이 오른쪽에 위치
5. (43) ==> 중간값 43 선정
6. 43 == 43 완료
추후 PYTHON CODE 첨부 예정
장점 :
1. 탐색 효율이 좋고, 탐색 기간이 적게 소요
2. 비교 횟수를 거듭할 때마다 검색 대상이 되는 데이터의 수가 절반으로 줄어든다.
3. 해싱(Hashing Search)
==> 레코드의 참조 없이 키 변환에 의해 원하는 레코드에 직접 접근할 수 있도록 구성, 키 변환 값이 같은 경우 오버플로우가 발생
==> 찾는 레코드의 키 값을 주소 변환하여 해당 위치에서 검색 ==> 조사 횟수가 적다.
1> 해싱 관련 용어
Bucket : 해싱(Hashing) 함수에 의해 계산되는 홈 주소(Home Address)에 의해 만들어지는 해시 테이블 내의 공간 의미
DAM(Direct Access Mehtod): 는 레코드에서 임의의 키 필드를 정해서 해싱 함수에 의해 주소로 변환 , 해당 위치에 레코드 저장
2> 해싱 함수
==> 키 값을 이용해서 레코드를 저장할 주소를 산출해 내는 수학식
폴딩 방법(중첩법) :
숫자를 키로 사용할 때 자릿수를 기준으로 몇 부분으로 나눈 다음 각 부분을 겹쳐서 더해서 해시 주소 얻음
==> 배타적 논리합(XOR) 사용!
제산법 : 레코드의 키 값을 임의의 소수(배열의 크기)로 나누어 그 나머지 값을 해시 값
기수 변환법 :레코드의 키 값을 임의의 다른 기수 값으로 변환하여 그 값을 홈 주소로 사용
무작위법 :난수 생성 프로그램을 이용하여 각 키의 홈 주소 얻는 방법
중간 제곱법 : 값을 제곱하여 결과값 중 중간 자릿수를 선택하여 그 값을 홈 주소로 사용
숫자 분석법 : 주어진 모든 키 값들에서 그 키를 구성하는 자릿수들의 분포를 조사하여 비교적 고른 분포를 보이는 자릿수들을 필요한 만큼 선택
3> 오버플로(OverFlow) 처리 방식
개방 주소(Open Addressing) 방식 : 충돌이 일어난 자리에서 그 다음 버킷을 차례로 검색하여 처음 나오는 빈 버킷에 데이터를 넣는 방식
재해싱(Rehashing) 방식 : 여러 개의 해싱 함수를 준비한 후 충돌이 발생하면 새로운 해싱 함수 이용하여 새로운 홈 주소 구하기
폐쇄 주소: 해시 테이블에서 서로 다른 키 값의 데이터가 해시 함수에 의해 같은 버킷에 배치되어 충돌 ==> 포인터와 같은 해시 함수 값을 갖는 레코드를 연결 리스트로 연결
'은행대비_IT > 자료구조' 카테고리의 다른 글
| [은행 필기대비 자료구조-05] 정렬 알고리즘_3 (0) | 2022.12.28 |
|---|---|
| [은행 필기대비 자료구조-04] 정렬 알고리즘_2 (0) | 2022.12.28 |
| [은행 필기대비 자료구조-03] 정렬 알고리즘 (0) | 2022.12.28 |
| [은행 필기대비 자료구조-02] 이진 트리 순회 경로 (1) | 2022.12.27 |
| [은행 필기대비 자료구조-01] 선형구조 (0) | 2022.12.15 |