전체 글
-
heapify★heappush★힙★더 맵게★[프로그래머스]2023.01.03
-
★VER2.0★베스트엘범[프로그래머스]2023.01.02
-
[백준 파이썬 2023번]신기한 소수★DFS이용한 재귀2023.01.02
VER2.0★범위지정시 BETWEEN★FROM절 서브쿼리★조건에 맞는 회원수 구하기[프로그래머스 ORACLE SQL]
https://school.programmers.co.kr/learn/courses/30/lessons/131535
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr

VERSION 2.0
SELECT COUNT(*) AS USERS FROM USER_INFO
WHERE (AGE BETWEEN 20 AND 29) AND TO_CHAR(JOINED ,'YYYY') = 2021==> BETWEEN 함수 활용!
VERSION 1.0
SELECT COUNT(USER_ID) AS USERS FROM
(SELECT USER_ID FROM USER_INFO WHERE AGE<=29 AND AGE>=20 AND TO_CHAR(JOINED , 'YYYY') = '2021')
TO_CHAR( 열이름, '형식' )
형식 : YYYY-MM-DD
'SQL > SELECT' 카테고리의 다른 글
| [프로그래머스 ORACLE SQL]가격이 제일 비싼 식품★WHERE절 서브쿼리 (0) | 2023.06.21 |
|---|---|
| [프로그래머스 ORACLE SQL]조건에 맞는 회원수 구하기★TO_CHAR()쓰임새★VER3.0 (0) | 2023.06.21 |
| ★VER2.0★[프로그래머스 ORACLE SQL]오프라인/온라인 판매 데이터 통합하기 (0) | 2023.01.04 |
| ★GROUP BY 2개 열 사용★[프로그래머스 ORACLE SQL]재구매가 일어난 상품과 회원 리스트 구하기 (0) | 2023.01.04 |
| ★TO_CHAR('열이름' , 'YYYY-MM-DD')★SELECT★흉부외과 또는 일반외과 의사 목록 출력하기[프로그래머스 ORACLE SQL] (0) | 2022.12.23 |
★VER2.0★[프로그래머스 ORACLE SQL]오프라인/온라인 판매 데이터 통합하기
https://school.programmers.co.kr/learn/courses/30/lessons/131537
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr

VERSION 2.0
SELECT TO_CHAR(SALES_DATE , 'YYYY-MM-DD') AS SALES_DATE , PRODUCT_ID , USER_ID , SALES_AMOUNT FROM
(SELECT SALES_DATE , PRODUCT_ID , USER_ID , SALES_AMOUNT FROM ONLINE_SALE
union
SELECT SALES_DATE, PRODUCT_ID , null USER_ID, SALES_AMOUNT FROM OFFLINE_SALE) --NULL 생성하는 열 함수
WHERE TO_CHAR(SALES_DATE , 'YYYY-MM') ='2022-03'
ORDER BY SALES_DATE ASC , PRODUCT_ID ASC , USER_ID ASC==> 열에 NULL 값 부여위해서는 앞에 NULL 값을 붙인다!!
VERSION 1.0
SELECT to_char(SALES_DATE, 'yyyy-mm-dd'),PRODUCT_ID, user_id, SALES_AMOUNT
from(
SELECT SALES_DATE,PRODUCT_ID, USER_ID, SALES_AMOUNT
from ONLINE_SALE
union
SELECT SALES_DATE, PRODUCT_ID, null USER_ID, SALES_AMOUNT
from OFFLINE_SALE)
where to_char(SALES_DATE, 'yyyymm') = 202203
order by SALES_DATE, PRODUCT_ID, USER_ID'SQL > SELECT' 카테고리의 다른 글
| [프로그래머스 ORACLE SQL]조건에 맞는 회원수 구하기★TO_CHAR()쓰임새★VER3.0 (0) | 2023.06.21 |
|---|---|
| VER2.0★범위지정시 BETWEEN★FROM절 서브쿼리★조건에 맞는 회원수 구하기[프로그래머스 ORACLE SQL] (0) | 2023.01.04 |
| ★GROUP BY 2개 열 사용★[프로그래머스 ORACLE SQL]재구매가 일어난 상품과 회원 리스트 구하기 (0) | 2023.01.04 |
| ★TO_CHAR('열이름' , 'YYYY-MM-DD')★SELECT★흉부외과 또는 일반외과 의사 목록 출력하기[프로그래머스 ORACLE SQL] (0) | 2022.12.23 |
| [프로그래머스 ORACLE SQL]인기있는 아이스크림★정렬★ (0) | 2022.10.27 |
★GROUP BY 2개 열 사용★[프로그래머스 ORACLE SQL]재구매가 일어난 상품과 회원 리스트 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/131536
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
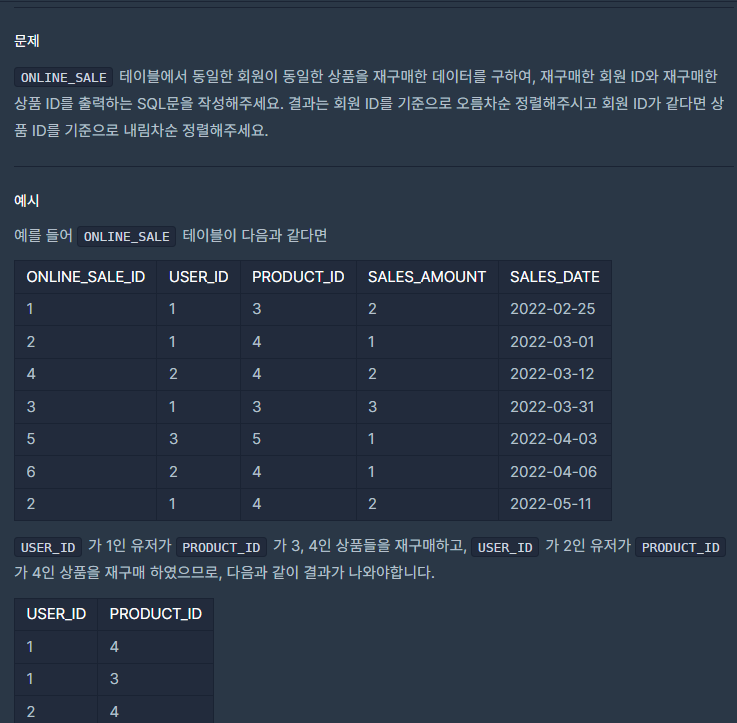
VERSION 2.0
SELECT USER_ID , PRODUCT_ID
FROM (SELECT USER_ID , PRODUCT_ID FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(USER_ID)>=2)
ORDER BY USER_ID ASC , PRODUCT_ID DESC==> FROM 절 서브쿼리! , GROUP BY로 우선 묶고 HAVING 절로 조건 부여!
VERSION 1.0
SELECT USER_ID , PRODUCT_ID FROM
(SELECT USER_ID , PRODUCT_ID, COUNT(*) FROM ONLINE_SALE
GROUP BY USER_ID , PRODUCT_ID
HAVING COUNT(*) >= 2)
ORDER BY USER_ID ASC , PRODUCT_ID DESCFROM 절의 서브 쿼리 ==> GROUP BY USER_ID , PRODUCT_ID 로 처리하여 동일한거의 개수가 2개이상 인것들의 테이블 갖고 온다.
'SQL > SELECT' 카테고리의 다른 글
| [프로그래머스 ORACLE SQL]조건에 맞는 회원수 구하기★TO_CHAR()쓰임새★VER3.0 (0) | 2023.06.21 |
|---|---|
| VER2.0★범위지정시 BETWEEN★FROM절 서브쿼리★조건에 맞는 회원수 구하기[프로그래머스 ORACLE SQL] (0) | 2023.01.04 |
| ★VER2.0★[프로그래머스 ORACLE SQL]오프라인/온라인 판매 데이터 통합하기 (0) | 2023.01.04 |
| ★TO_CHAR('열이름' , 'YYYY-MM-DD')★SELECT★흉부외과 또는 일반외과 의사 목록 출력하기[프로그래머스 ORACLE SQL] (0) | 2022.12.23 |
| [프로그래머스 ORACLE SQL]인기있는 아이스크림★정렬★ (0) | 2022.10.27 |
heapify★heappush★힙★더 맵게★[프로그래머스]
https://school.programmers.co.kr/learn/courses/30/lessons/42626?language=python3
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
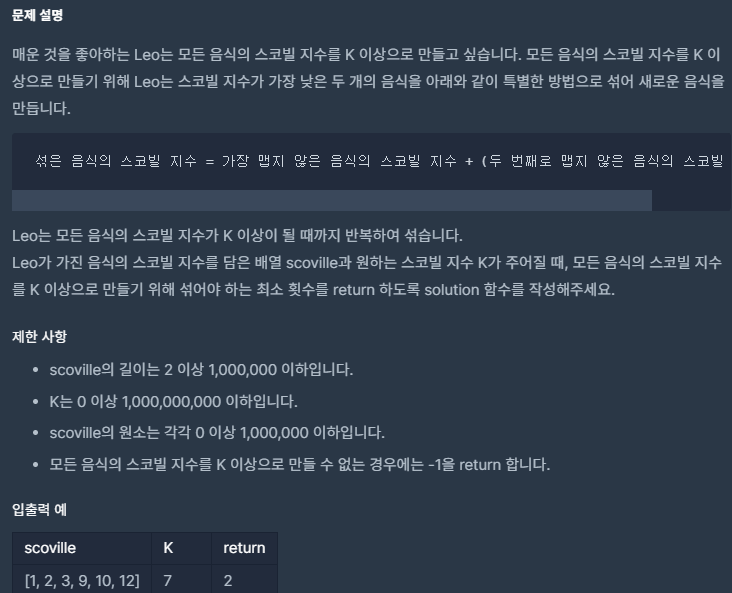
VERSION 1.0
import heapq
from collections import deque
from heapq import *
def solution(scoville, K):
count = 0
heapify(scoville)
print(f'heapify(scoville) : {scoville}')
while scoville[0] < K and len(scoville) > 1:
num1 = heappop(scoville)
num2 = heappop(scoville)
heappush(scoville, num1 + num2 * 2)
print(scoville)
count += 1
return count if scoville[0] >= K else -1==> heapify ==> 오름차순 정렬!!
==> from heapq import * ==> heapq의 모든 내장함수 가져온다.
==> heappush 주목!
★VER3.0★Deque★문자열슬라이싱★같은 숫자는 싫어[프로그래머스]
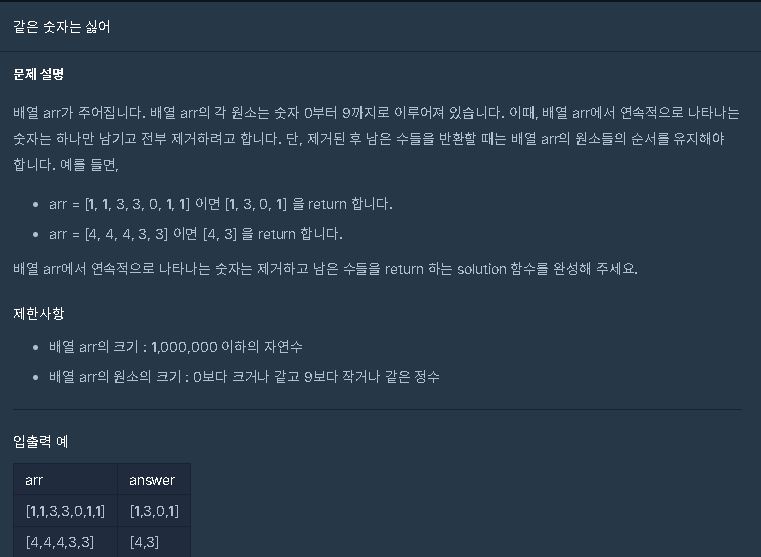
https://school.programmers.co.kr/learn/courses/30/lessons/12906
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
VER 3.0
from collections import deque
def solution(arr):
arr = deque(arr)
# print(arr)
answer = [arr[0]]
while len(arr)>=1:
if arr[0] == answer[-1]:
arr.popleft()
continue
else:
answer.append(arr[0])
arr.popleft()
return answer==> reutrn 으로 deque()은 Json 오류가 난다.
==> arr[0] == answer[-1] 이 POINT!
VER 2.0
def no_continuous(s):
a = []
for i in s:
if a[-1:] == [i]: #뒤에서부터 검증
continue
a.append(i)
return a
# 아래는 테스트로 출력해 보기 위한 코드입니다.
print( no_continuous( "133303" ))문자열 슬라이싱 잘 기억하자!!!!!!!!!!!
VER 1.0
from collections import deque
def solution(arr):
answer = []
queue = deque(arr)
queue2 = []
# for i in range(3):
# print(queue[i])
for i in range(len(arr)):
#print(i)
if len(queue)>1:
print("len(queue) : {}".format(len(queue)))
if queue[0] == queue[1]:
queue.popleft()
print("queue : {}".format(queue))
else:
queue2.append(queue.popleft())
else:
queue2.append(queue.popleft())
#queue[0] == queue[1] ==> queue.popleft() ==> [1,3,3,0,1,1]
#queue[0] != queue[1] ==> queue.append(queue.popleft()) ==> [3,3,0,1,1,1]
#queue[0] == queue[1] ==> queue.popleft() ==> [3,0,1,1,1]
#queue[0] != queue[1] ==> queue.append(queue.popleft()) ==> [0,1,1,1,3]
#queue[0] != queue[1] ==> queue.append(queue.popleft()) ==> [1,1,1,3,0]
#queue[0] == queue[1] ==> queue.popleft() ==> [3,0,1,1,1]
#print(queue)
# for i in arr:
# if i not in queue:
# queue.append(i)
# [실행] 버튼을 누르면 출력 값을 볼 수 있습니다.
#print('Hello Python')
return queue2
solution([1,1,3,3,0,1,1])덱과 리스트 한번씩 더써서 그런지 효율성에서 떨어졌다.
'Python(프로그래머스) > 스택,큐' 카테고리의 다른 글
| ★리스트★스택★같은 숫자는 싫어[프로그래머스] (1) | 2023.06.18 |
|---|---|
| ★DEQUE★split()★괄호 회전하기[프로그래머스] (0) | 2023.04.26 |
| ★DEQUE★다리를 지나는 트럭[프로그래머스] (0) | 2022.11.29 |
| ★DEQUE★enumerate★프린터[프로그래머스] (0) | 2022.11.19 |
| VER2.0★DEL★DEQUE★기능개발[프로그래머스] (0) | 2022.11.19 |
★VER2.0★베스트엘범[프로그래머스]
https://school.programmers.co.kr/learn/courses/30/lessons/42579
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr

VERSION 1.0
from functools import reduce
from collections import Counter
def solution(genres, plays):
answer = []
dic1 = {}
dic2 = {}
#print(list(zip(genres, plays)))
for i, (g, p) in enumerate(zip(genres, plays)):
#i = 0 g= 'classic' p = 500
#i= 1 g= 'pop' p =600
#i=2 g= 'classic' p =150
#i=3 g= 'classic' p =800
#i= 4 g= 'pop' p =2500
if g not in dic1: #'classic' in dic1 , 'pop' in dic1
dic1[g] = [(i, p)]
#dic1['classic'] = [(0,500)]
#dic1['pop'] = [(1,600)]
else:
dic1[g].append((i, p))
#dic1['classic'].append((2,150)) ==> dic1 {'classic' : [(0,500), (1,600)] ,'pop' : [(1,600)]}
#dic1['classic'].append((3,800)) ==> dic1 {'classic' : [(0,500), (1,600), (3,800)] ,'pop' : [(1,600)]}
#dic1['pop'].append((4,2500)) ==> dic1 {'classic' : [(0,500), (1,600), (3,800)] ,'pop' : [(1,600) , (4,2500)]}
#print(dic1)
if g not in dic2: #classic in dic2
dic2[g] = p
#dic2['classic'] = 500
#dic2['pop'] = 600
else:
dic2[g] += p
#dic2['classic'] += 600 ==> {'classic' : 500+600 , 'pop' : 600}
#dic2['classic'] += 800 ==> {'classic' : 500+600+800 , 'pop' : 600}
#dic2['pop'] += 600 ==> {'classic' : 500+600+800 , 'pop' : 600+2500}
#print(dic2)
for (k, v) in sorted(dic2.items(), key=lambda x:x[1], reverse=True):
#sorted(dic2.items()) ==> {'classic' : 2100 , 'pop' : 3100}
#key = lambda x:x[1] ==> 숫자들로 정렬 하겠다.
#k = 'pop' , 'classic'
#v = 3100 , 2100
#print("dic1 : {}".format(dic1[k]))
for (i, p) in sorted(dic1[k], key=lambda x:x[1], reverse=True)[:2]: #장르 별로 가장 많이 재생된 노래를 최대 두개까지 모아 베스트엘범 출시 하므로
# print("dic1_i : {}".format(i))
# print("dic1_p : {}".format(p))
#sorted(dic1['pop']) = [(1,600) , (4,2500)]
#sorted(dic1['pop'], key=lambda x:x[1], reverse=True)[:2] = [(4,2500) , (1,600)]
answer.append(i)
return answer'Python(프로그래머스) > 해시' 카테고리의 다른 글
| ★VER5.0★해시★Collections.Counter★완주하지 못한 선수[프로그래머스] (0) | 2023.06.18 |
|---|---|
| ★VER5.0★해시★Collections.Counter★폰켓몬[프로그래머스] (0) | 2023.06.18 |
| VER3.0★문자열 리스트(정수형) 정렬할땐 맨앞에꺼 숫자에 따라 정렬된다.★리스트 시작★zip★startswith★전화번호목록[프로그래머스] (0) | 2023.05.29 |
| list(map(lambda x : x[1] , 리스트)) ==> 2중 리스트 뒤에값★VER2.0★zip★reduce★위장[프로그래머스] (0) | 2023.01.02 |
| ★zip★items★directory append★베스트엘범[프로그래머스] (0) | 2022.11.17 |
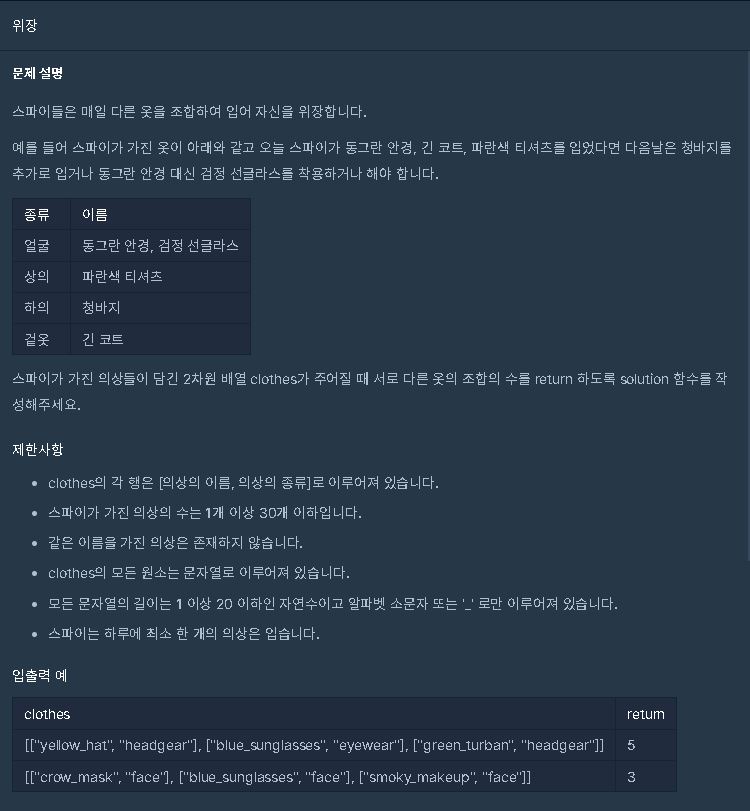
https://school.programmers.co.kr/learn/courses/30/lessons/42578
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
VERSION 2.0
import collections
import itertools
def solution(clothes):
b = collections.Counter(list(map(lambda x : x[1] , clothes)))
answer = 1
for i in list(b.values()):
answer *= i+1
return answer -1==> eyewear : 2 , headgear : 1
==> answer*= (2+1) -> answer *= (1+1)
VERSION 1.0

from collections import Counter
from functools import reduce
def solution(clothes):
# 1. 의상 종류별 Counter를 만든다.
counter = Counter([type for clothe, type in clothes])
print(counter)
# 2. zip 함수를 통하여 counter 값 구할수도 있다.
print("애스터리스크 : {}".format(*clothes))
print("애스터리스크 with zip: {}".format(list(zip(*clothes))))
counter_2 = Counter(list(zip(*clothes))[1])
print(counter_2)
# 3. 모든 종류의 count + 1을 누적하여 곱해준다
answer = reduce(lambda acc, cur: acc*(cur+1), counter_2.values() , 1) - 1
#acc 매개변수에는 counter_2의 value 값들 , cur 매개변수에는 1을
#reduce 함수는 반복 가능한 객체 내 각 요소를 연산한 뒤 이전 연산 결과들과 누적해서 반환해 주는 함수이다.
#counter_2.values()에는 ==> 2, 1 ==> 2*(1+1) + 1*(1+1) - 1 = 5
#ex) target = [i for i in range(1,22)]
# answer = reduce(lambda x, y : x+y , target) ==> 1+2 +3 + 4 + 5 +..... ==> 누적값 반환
return answer1. *clothes ==> 애스터리스크로 list안의 list들 빼온다.
2. zip()함수를 통해 ==> list안의 값들 요소에 맞게 정리
3.reduce 함수는 누적해서 곱하는 함수
4. 누적함수를 쓰는 이유는
계산한 count를 통해서 (count+1)를 곱해주고 마지막에 1을 빼줌
- 1을 빼주는 이유는 모두 안입은 경우를 제거
'Python(프로그래머스) > 해시' 카테고리의 다른 글
| ★VER5.0★해시★Collections.Counter★완주하지 못한 선수[프로그래머스] (0) | 2023.06.18 |
|---|---|
| ★VER5.0★해시★Collections.Counter★폰켓몬[프로그래머스] (0) | 2023.06.18 |
| VER3.0★문자열 리스트(정수형) 정렬할땐 맨앞에꺼 숫자에 따라 정렬된다.★리스트 시작★zip★startswith★전화번호목록[프로그래머스] (0) | 2023.05.29 |
| ★VER2.0★베스트엘범[프로그래머스] (0) | 2023.01.02 |
| ★zip★items★directory append★베스트엘범[프로그래머스] (0) | 2022.11.17 |
[백준 파이썬 2023번]신기한 소수★DFS이용한 재귀
https://www.acmicpc.net/problem/2023
2023번: 신기한 소수
수빈이가 세상에서 가장 좋아하는 것은 소수이고, 취미는 소수를 가지고 노는 것이다. 요즘 수빈이가 가장 관심있어 하는 소수는 7331이다. 7331은 소수인데, 신기하게도 733도 소수이고, 73도 소수
www.acmicpc.net

import sys
import math
sys.setrecursionlimit(10000)
N = int(sys.stdin.readline())
def is_prime(num):
for i in range(2, int(math.sqrt(num) + 1)):
if num % i == 0:
return False
return True
def DFS(number):
if len(str(number))==N:
print(number)
else:
for i in range(1, 10):
if i % 2 == 0:
continue
if is_prime(number * 10 + i):
DFS(number * 10 + i)
#N = 2
DFS(2)
# DFS(2) ==> number = 2 ==> len(str(number))=1 != N(2)
# is_prime(2 *10 +1) ==> False
# is_prime(2 *10 +3) == True ==> DFS(2*10 + 3) = DFS(23) ==> len(str(23)) =2 == N ==> print(23)
# is_pime(2 * 10 + 5) == False
# is_pime(2 * 10 + 7) == False
# is_pime(2 * 10 + 9) == True ==> DFS(2*10 + 9) = DFS(29) ==> len(str(29)) =2 == N ==> print(29)
DFS(3)
DFS(5)
DFS(7)==> 재귀에 대한 이해
==> DFS(2) , DFS(3) , DFS(5), DFS(7) ==> 소수에 대한 재귀를 시작하면 된다.
'Python(백준) > DFS_깊이 우선탐색' 카테고리의 다른 글
| [백준 파이썬 11724번]연결 요소의 개수 구하기★DFS★edge 리스트★VER3.0 (0) | 2023.01.02 |
|---|