★어려운거 다시보기★푸아송분포★이항분포★기초통계학-[Chapter05 - 연습문제-09]
14. 좌석이 30석 , NO-SHOW일 확률 0.1, 32장 판매 , 나타난 승객이 가용할 수 있는 좌석보다 더 많을 확률
N = 32
p = 0.1
q = 0.9
m = 32 * 0.1
==> N이 30이상이므로 푸아송 분포
==> f(x) = (m ** x * e**(-m) ) / fact(x)
F_X , F_X_2 = 0, 0
m = 32 * 0.1
for x in range(0,2):
F_X += (m ** x) * math.exp(-m) / fact(x)
print(F_X)P(0<=X<=1) =P(X<=1) = 0.1712 ==> 푸아송분포
F_X = 0
for x in range(0,2):
F_X += len(list(itertools.combinations(np.arange(32) , x))) * (0.1 ** x) * (0.9 ** (32-x))
print(F_X)==> f(x) = 32Cx * (0.1 ** x) * (0.9 ** (n-x))
이항분포 ==> 0.1564
15. 우성 d , 열성 r , (d,d) 순수우성 , (r,r) 순수열성 , (d,r) , (r,d)를 혼성
1> 혼성 유전인자(d,r) , (r,d)의 두 부모의 자녀가 순수열성(r,r)일 확률
1/4
2> 혼성 유전인자(d,r) , (r,d)의 두 부모의 자녀가 5명일때 5명중 1명만 순수열성(r,r)일 확률
n = 5
p = 0.25
p(X) = 5Cx * (0.25 ** x) * (0.75 ** (5-x))
p(X=1) = 0.3955
3>평균 순수열성인 자녀수
5 * 0.25 = 1.25
16. 55% 음주운전사고, 5건의 치명적인 사고, 사고가 발생한 횟수 X
1> 5번 모두 사고가 날 확률
N = X
r = 5
p = 0.55
X~ B(5 , 0.55)
x = 5
p_x = len(list(itertools.combinations(np.arange(5) , x))) * (0.55 ** x) * (0.45 ** (5-x))
print(p_x)P(X) = 5Cx * (0.55 ** x) * (0.45 ** 5-x)
P(X=5) = 0.0503
2> 꼭 3번 사고가 날 확률
x = 3
p_x = len(list(itertools.combinations(np.arange(5) , x))) * (0.55 ** x) * (0.45 ** (5-x))
print(p_x)P(X=3) = 0.3369
3> 적어도 1번 이상 사고가 날 확률
P(X>=1) = 1 - P(X=0) = 0.9815
17. 평균 0.3의 비율로 보험금 신청, 신청건수는 푸아송분포 따른다.
E(X) = 0.3
1> 보험 가입자들이 1년에 적어도 2건 이상 보험금 청구할 확률
f(x) = m**(x) * e**(-m) / fact(m)
P(X>=2) = 1 - P(X<=1) = 0.03693
2> 신청금액이 일률적으로 1000만원 , 연간 피보험자에게 지불해야 할 평균 보험금
0.3 * 1000 = 300만원
3> 보험소지한 사람 500명, 연평균 보험금을 신청할 보험 가입자 수 구하기
N = 500
500 * 0.3 = 150명
18. 접수되는 지급 요구 건수는 푸아송분포. 월요일에는 2건 , 다른 요일에는 1건, 월~금 적어도 2건의 지급요구가 접수될 확률
확률변수 X : 접수되는 지급 요구건수
E(X='월요일') = 2
E(X='화~금') = 1
F_X = 0
m = 6
for x in range(0,2):
a = (m ** x) * math.exp(-m) / fact(x)
print(a)
F_X += a
print(1 - F_X )==> E(X) = 2 + 1 + 1 +1 +1 = 6
P(X) = m** x * (e ** (-m)) * fact(x)
P(X>=2) = 1- P(X<=1) = 0.9826
19. 개막전 연기될때 매일(최대 2일) 1000달러 지급 계약, 1일부터 연속적으로 비가 오는 수가 평균 0.6인 푸아송분포 따른다. 보험금의 표준편차
m = 0.6
p(x) = m **x * (e **(-m) ) / fact(x)
P(X = 0 ) = 0.5488
P(X=1) = 0.329
P(X>=2) = 1- P(X<=1) = 1 - 0.5488 - 0.329 = 0.1222
q = 1 - 0.428 = 0.5719
xx = np.arange(0,3).tolist()
m = 0.6
p_x = []
for x in range(3):
a = (m ** x) * math.exp(-m) / fact(x)
if x ==2:
p_x.append(1- 0.5488 - 0.329)
else:
# print(1- 0.5488 - 0.329)
p_x.append(a)
A = pd.DataFrame([p_x] , columns = xx)
A.index = ['P(X = x)']
A.columns.names= ['X']
for i in range(1,3):
A.iloc[0, i] = A.iloc[0 , i]
print(A.iloc[0,1] + A.iloc[0,2])
# print(A[:].sum(axis=1) - A.iloc[0,0])
A

x_1 = A.iloc[0 , :].tolist()
x_1
P_x = [0 , 1000 , 2000]
B =pd.DataFrame([x_1] , columns = P_x)
B.index = ['P(X = x)']
B.columns.names = ['X']
B
vars = 0
means = 0
print(P_x)
for i in range(len(x_1)):
means += (x_1[i] * P_x[i])
vars += (x_1[i] * math.pow(P_x[i],2))
print(vars)
print(means)
vars = math.sqrt(vars - math.pow(means, 2) )
vars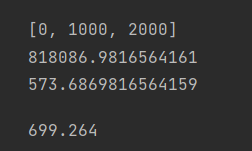
==> VAR = E(X**2) - (E(X) ** 2)
20. 건강한사람 1mm**3당 평균 6000개의 백혈구 , 입원한 환자의 백혈구 결핍 알아보기위해 0.001 mm**3 채취, 백혈구의 수는 푸아송 분포를 따른다.
1> 건강한 사람의 평균 백혈구 수
m = 6000
n = 1 p= 6000 E(X) = 6000
n_2 = 0.001 p = 6000 ==> 6
n_2 = 10 p = 0.6
E(X) = np = 6000
2> P(X<=2)
X ~ P(6) = 6**x * (e **(-6) ) / x!
P(X<=2) = P(X=0) + P(X=1) + P(X=2) = 0.0619
출처 : [쉽게 배우는 생활속의 통계학] [북스힐 , 이재원]
※혼자 공부 정리용
'기초통계 > 이산확률변수' 카테고리의 다른 글
| ★초기하분포★기초통계학-[Chapter05 - 연습문제-11] (0) | 2022.12.18 |
|---|---|
| ★푸아송분포★이항분포★기초통계학-[Chapter05 - 연습문제-10] (0) | 2022.12.17 |
| ★푸아송분포★이항분포의 평균 분산★베르누이★이산확률변수★기초통계학-[Chapter05 - 연습문제-08] (0) | 2022.12.16 |
| ★푸아송분포★기하분포★초기하분포★베르누이★이산확률변수★기초통계학-[Chapter05 - 연습문제-07] (0) | 2022.12.15 |
| ★초기하분포★기하분포★이산균등분포★기초통계학-[Chapter05 - 이산확률분포-06] (0) | 2022.12.15 |