전체 글
-
★merge★[PYTHON] 외교부_데이터분석_프로세스-032022.11.24
-
★액셀_시트명 뽑아내기[PYTHON] 외교부_데이터분석_프로세스-012022.11.23
-
★DEQUE★enumerate★프린터[프로그래머스]2022.11.19
-
VER2.0★DEL★DEQUE★기능개발[프로그래머스]2022.11.19
-
★STACK★올바른 괄호[프로그래머스]2022.11.18
-
★zip★items★directory append★베스트엘범[프로그래머스]2022.11.17
-
★FROM절 서브쿼리★[프로그래머스 ORACLE SQL]가장 비싼 상품 구하기2022.11.05
★merge★[PYTHON] 외교부_데이터분석_프로세스-03
1. Merge 합치기(병합)
merge_outer_1 = pd.merge(merge_outer_1, a[k] , how='outer' , on=('공관코드' ,'재외공관'))how = 'outer' or 'inner' or 'left' or 'right'
on = ('공관코드' , '재외공관')
'데이터분석 > 외교부_데이터분석' 카테고리의 다른 글
| [외교부 데이터 분석_지도 시각화]Python Mapboxgl 활용하기 (0) | 2023.02.23 |
|---|---|
| ★concat★insert★transpose()★[PYTHON] 외교부_데이터분석_프로세스-05 (0) | 2022.11.24 |
| ★정규식(re)★apply★lambda★[PYTHON] 외교부_데이터분석_프로세스-04 (0) | 2022.11.24 |
| ★iloc★loc★rename★fillna★[PYTHON] 외교부_데이터분석_프로세스-02 (0) | 2022.11.23 |
| ★액셀_시트명 뽑아내기[PYTHON] 외교부_데이터분석_프로세스-01 (0) | 2022.11.23 |
★iloc★loc★rename★fillna★[PYTHON] 외교부_데이터분석_프로세스-02
1. iloc
df.iloc[: , [0,1,2]] ==> iloc는 번호로 해당 DATA 출력 해당 예시는 전체 행 , 0,1,2 열 출력
df_0912 = df.iloc[: , [0,1 , 10, 11 ,12, 13]]2. loc
df.iloc[: , ['공관코드']] ==> loc는 이름으로 로 해당 DATA 출력 해당 예시는 전체 행 ,
'공관코드' 열 출력 ==> 열은 이름으로 해야만 한다!
3. rename
df.rename(columns = {'대사관명' : '재외공관'} , inplace = True)==> DataFrame의 열 이름 변경(대사관명 ==> 재외공관) ==> inplace = True 는 변수 또 선언할 필요없이 한번에 그냥 처리
4. fillna(0)
df = df.fillna(0)==> DataFrame 내 요소들중 NaN ==> 0으로 다 변환시킨다.
'데이터분석 > 외교부_데이터분석' 카테고리의 다른 글
| [외교부 데이터 분석_지도 시각화]Python Mapboxgl 활용하기 (0) | 2023.02.23 |
|---|---|
| ★concat★insert★transpose()★[PYTHON] 외교부_데이터분석_프로세스-05 (0) | 2022.11.24 |
| ★정규식(re)★apply★lambda★[PYTHON] 외교부_데이터분석_프로세스-04 (0) | 2022.11.24 |
| ★merge★[PYTHON] 외교부_데이터분석_프로세스-03 (0) | 2022.11.24 |
| ★액셀_시트명 뽑아내기[PYTHON] 외교부_데이터분석_프로세스-01 (0) | 2022.11.23 |
★액셀_시트명 뽑아내기[PYTHON] 외교부_데이터분석_프로세스-01
1. 액셀 SHEET 명 뽑아내기
import openpyxl # 파이썬으로 엑셀을 불러와 시트이름 출력
name = '1~5월.xlsx'
wb = openpyxl.load_workbook(r'{}'.format(name)) #액셀에 있는 모든 Sheet를 wb변수에 저장
ws = wb.active #활성화 된 Sheet를 ws라는 변수에 담는다.
ws_names = wb.sheetnames #모든 sheet 이름 불러오기
idx = ws_names[2] #sheet page
df = pd.read_excel(name, sheet_name = idx) #sheet의 2번째 pange 읽어서 DATAFRAME 화
2. pandas 로 액셀 or csv 불러오기
pd.read_excel(name, sheet_name = idx)
==> sheet_name = 페이지
'데이터분석 > 외교부_데이터분석' 카테고리의 다른 글
| [외교부 데이터 분석_지도 시각화]Python Mapboxgl 활용하기 (0) | 2023.02.23 |
|---|---|
| ★concat★insert★transpose()★[PYTHON] 외교부_데이터분석_프로세스-05 (0) | 2022.11.24 |
| ★정규식(re)★apply★lambda★[PYTHON] 외교부_데이터분석_프로세스-04 (0) | 2022.11.24 |
| ★merge★[PYTHON] 외교부_데이터분석_프로세스-03 (0) | 2022.11.24 |
| ★iloc★loc★rename★fillna★[PYTHON] 외교부_데이터분석_프로세스-02 (0) | 2022.11.23 |
★DEQUE★enumerate★프린터[프로그래머스]

https://school.programmers.co.kr/learn/courses/30/lessons/42587
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
from collections import deque
import sys
def solution(priorities, location):
answer = 0
queue = deque()
for i,v in enumerate(priorities):
queue.append((v,i)) #queue 키,value값 거꾸로 하기
print(queue)
maxe = max(queue)[0]
print(maxe) #queue값의 첫 요소들중 제일 큰값
res = []
while True:
if len(queue)==0:
break
else:
maxe = max(queue)[0]
if queue[0][0] == maxe: #첫번째 순서의 요소값이 제일 큰 값일때
res.append(queue.popleft()) #없애고 res 리스트에 추가시킨다.
else:
queue.append(queue.popleft())
res2=[]
for i,k in res:
res2.append(k)
answer = res2.index(location)+1
return answer'Python(프로그래머스) > 스택,큐' 카테고리의 다른 글
| ★DEQUE★split()★괄호 회전하기[프로그래머스] (0) | 2023.04.26 |
|---|---|
| ★VER3.0★Deque★문자열슬라이싱★같은 숫자는 싫어[프로그래머스] (1) | 2023.01.03 |
| ★DEQUE★다리를 지나는 트럭[프로그래머스] (0) | 2022.11.29 |
| VER2.0★DEL★DEQUE★기능개발[프로그래머스] (0) | 2022.11.19 |
| ★STACK★올바른 괄호[프로그래머스] (0) | 2022.11.18 |
VER2.0★DEL★DEQUE★기능개발[프로그래머스]

https://school.programmers.co.kr/learn/courses/30/lessons/42586#
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
VERSION 2.0
from collections import deque
import math
import copy
def solution(progresses, speeds):
answer = []
b = deque()
for p,s in zip(progresses, speeds):
b.append(math.ceil((100-p)/s))
print(b)
a = 1
while True:
if len(b) == 1:
answer.append(a)
break
if b[1]<=b[0]:
a+=1
del b[1]
else:
c = b.popleft()
answer.append(a)
a=1
return answerVERSION 1.0
from collections import deque
import math
def solution(progresses, speeds):
answer = []
res = []
for i in range(len(progresses)):
a = int(math.ceil((100-progresses[i]) / speeds[i])) #MATH 모듈의 CEIL 올림함수 이용하여 걸리는 시간 계산
res.append(a) #res 리스트에 저장
print(res)
queue = (deque(res)) #res리스트를 deque화
a = list(queue)
cnt = 1 #갯수 첨 부터 1개이므로 1로 초기화
while True:
if len(queue) == 1: #while 문 벗어날때 마지막 queue값이 1개만 남았을 경우 break
answer.append(cnt)
break
else:
if queue[0]<queue[1]: #맨앞꺼가 뒤에꺼보다 작을경우 일을 더 못하는거므로
queue.popleft() #맨앞꺼 없애고
answer.append(cnt) #answer 리스트에 현재 cnt값 저장하고
cnt=1 #cnt값 초기화 시켜준다.
else:
cnt+=1
del queue[1] #del queue[1] 이거 기억하자
idx+=1
return answerDEL() 기억하자!!!!!!!!!!!!!!!!!!
MATH.CEIL() 올림함수도 기억하자!!!!!!!!!!!!!!!!!!!!!!!!!!
'Python(프로그래머스) > 스택,큐' 카테고리의 다른 글
| ★DEQUE★split()★괄호 회전하기[프로그래머스] (0) | 2023.04.26 |
|---|---|
| ★VER3.0★Deque★문자열슬라이싱★같은 숫자는 싫어[프로그래머스] (1) | 2023.01.03 |
| ★DEQUE★다리를 지나는 트럭[프로그래머스] (0) | 2022.11.29 |
| ★DEQUE★enumerate★프린터[프로그래머스] (0) | 2022.11.19 |
| ★STACK★올바른 괄호[프로그래머스] (0) | 2022.11.18 |
★STACK★올바른 괄호[프로그래머스]

https://school.programmers.co.kr/learn/courses/30/lessons/12909
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(s):
stack = []
for i in s:
if i == '(': # '('는 stack에 추가 #"()()"
stack.append(i)
#stack['(']
else: # i == ')'인 경우
if stack == []: # 괄호 짝이 ')'로 시작하면 False 반환
return False
else:
stack.pop() # '('가 ')'와 짝을 이루면 stack에서 '(' 하나 제거
#stack['']
return stack==[]
solution("()()")
'Python(프로그래머스) > 스택,큐' 카테고리의 다른 글
| ★DEQUE★split()★괄호 회전하기[프로그래머스] (0) | 2023.04.26 |
|---|---|
| ★VER3.0★Deque★문자열슬라이싱★같은 숫자는 싫어[프로그래머스] (1) | 2023.01.03 |
| ★DEQUE★다리를 지나는 트럭[프로그래머스] (0) | 2022.11.29 |
| ★DEQUE★enumerate★프린터[프로그래머스] (0) | 2022.11.19 |
| VER2.0★DEL★DEQUE★기능개발[프로그래머스] (0) | 2022.11.19 |
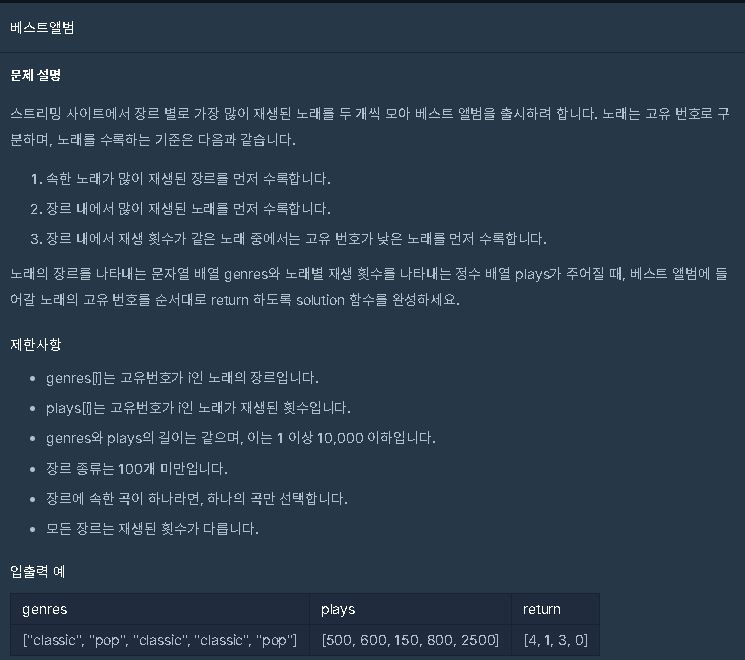
★zip★items★directory append★베스트엘범[프로그래머스]
https://school.programmers.co.kr/learn/courses/30/lessons/42579
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(genres, plays):
answer = []
dic1 = {}
dic2 = {}
print("list(zip(genres, plays)) : {}".format(list(zip(genres, plays))))
for i, (g, p) in enumerate(zip(genres, plays)):
#i = 0 g= 'classic' p = 500
#i= 1 g= 'pop' p =600
#i=2 g= 'classic' p =150
#i=3 g= 'classic' p =800
#i= 4 g= 'pop' p =2500
if g not in dic1: #'classic' in dic1 , 'pop' in dic1
dic1[g] = [(i, p)]
#dic1['classic'] = [(0,500)]
#dic1['pop'] = [(1,600)]
else:
dic1[g].append((i, p))
#dic1['classic'].append((2,150)) ==> dic1 {'classic' : [(0,500), (1,600)] ,'pop' : [(1,600)]}
#dic1['classic'].append((3,800)) ==> dic1 {'classic' : [(0,500), (1,600), (3,800)] ,'pop' : [(1,600)]}
#dic1['pop'].append((4,2500)) ==> dic1 {'classic' : [(0,500), (1,600), (3,800)] ,'pop' : [(1,600) , (4,2500)]}
print("dic1 : {}".format(dic1))
if g not in dic2: #classic in dic2
dic2[g] = p
#dic2['classic'] = 500
#dic2['pop'] = 600
else:
dic2[g] += p
#dic2['classic'] += 600 ==> {'classic' : 500+600 , 'pop' : 600}
#dic2['classic'] += 800 ==> {'classic' : 500+600+800 , 'pop' : 600}
#dic2['pop'] += 600 ==> {'classic' : 500+600+800 , 'pop' : 600+2500}
print("dic2 : {}".format(dic2))
for (k, v) in sorted(dic2.items(), key=lambda x:x[1], reverse=True):
#sorted(dic2.items()) ==> {'classic' : 2100 , 'pop' : 3100}
#key = lambda x:x[1] ==> 숫자들로 정렬 하겠다.
#k = 'pop' , 'classic'
#v = 3100 , 2100
print("dic1 : {}".format(dic1[k]))
for (i, p) in sorted(dic1[k], key=lambda x:x[1], reverse=True)[:2]:
#장르 별로 가장 많이 재생된 노래를 최대 2개까지 모아 베스트엘범 출시 하므로
print("dic1_i : {}".format(i))
print("dic1_p : {}".format(p))
#sorted(dic1['pop']) = [(1,600) , (4,2500)]
#sorted(dic1['pop'], key=lambda x:x[1], reverse=True)[:2] = [(4,2500) , (1,600)]
answer.append(i)
return answer
print(solution(["classic", "pop", "classic", "classic", "pop"] , [500, 600, 150, 800, 2500]))
주석 하나하나 읽어보자
'Python(프로그래머스) > 해시' 카테고리의 다른 글
| ★VER5.0★해시★Collections.Counter★완주하지 못한 선수[프로그래머스] (0) | 2023.06.18 |
|---|---|
| ★VER5.0★해시★Collections.Counter★폰켓몬[프로그래머스] (0) | 2023.06.18 |
| VER3.0★문자열 리스트(정수형) 정렬할땐 맨앞에꺼 숫자에 따라 정렬된다.★리스트 시작★zip★startswith★전화번호목록[프로그래머스] (0) | 2023.05.29 |
| ★VER2.0★베스트엘범[프로그래머스] (0) | 2023.01.02 |
| list(map(lambda x : x[1] , 리스트)) ==> 2중 리스트 뒤에값★VER2.0★zip★reduce★위장[프로그래머스] (0) | 2023.01.02 |
★FROM절 서브쿼리★[프로그래머스 ORACLE SQL]가장 비싼 상품 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/131697
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
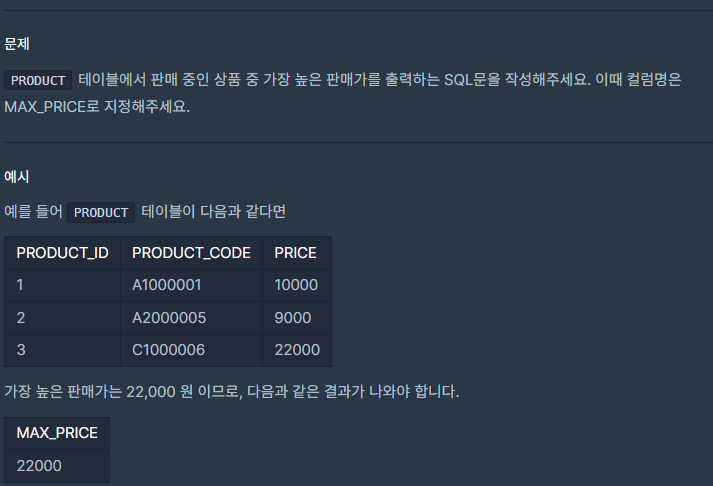
SELECT * FROM (SELECT MAX(PRICE) AS MAX_PRICE FROM PRODUCT )열이름에 MAX(PRICE) 하면 MAX 함수 실행가능하다.
'SQL > SUM,MAX,MIN' 카테고리의 다른 글
| ★WHERE절 서브쿼리★[프로그래머스 ORACLE SQL]가격이 제일 비싼 식품의 정보 출력하기 (0) | 2023.06.21 |
|---|---|
| ★DISTINCT★[프로그래머스 ORACLE SQL]중복값 제거 (0) | 2023.01.04 |
| 시간에 MAX 활용 ★FROM절 서브쿼리★VER2.0 ★[프로그래머스 ORACLE SQL]최댓값 구하기 (0) | 2023.01.04 |