★모평균을 알때는 카이제곱★중심극한정리(표본평균의 표준정규분포)★이항분포의 평균,분산★기초통계학-[연습문제02 -17]
14. 어느 주식의 가격이 매일 1단위 오를 확률은 0.52이고, 1단위 내릴 확률은 0.48이다. 첫째날 200을 투자하여 100일후의 가격은 X = 200 + for i in range(1, 101) : X_i += X_i-1
1> 주식의 등락금액 X_i , i= 1,2, ·····100의 확률함수를 구하라.
p(x) =
0.52 , x= 1
0.48 , x = -1
https://knowallworld.tistory.com/241
이항분포식★이항실험★이항분포의 평균,분산★베르누이시행★기초통계학-[Chapter05 - 이산확률
1. 이항분포 ==> 많이 사용하는 확률 모형 : 이항분포, 푸아송분포 , 초기하분포 1. 이항실험(Bionomial Experiment) ==> 실험은 N번의 시행 ==> 실험 결과는 성공(S) , 실패(F) ==> 성공 확률 : p , 실패 확률 : q
knowallworld.tistory.com
2> X_i의 평균과 분산
https://knowallworld.tistory.com/246
★푸아송분포★기하분포★초기하분포★베르누이★이산확률변수★기초통계학-[Chapter05 - 연습문
1. 이산확률변수 x의 확률분포 X = np.arange(-2,3) p_x = [0.15 , 0.25 , '-' , 0.25 , 0.3] A = pd.DataFrame([p_x] , columns = X) A.index = ['P(X = x)'] A.columns.names = ['X'] A B = (1- A.iloc[ [0], [0,1,3,4]].sum(axis=1)) B A.loc['P(X = x)' , 0] =
knowallworld.tistory.com
==> 이산확률변수의 평균과 분산 구하기
평균 : 0.52 * 1 + (-1) * 0.48 = 0.04
분산 : 1**2(0.52) + (-1)**2 *0.48 - 0.04**2 = 0.9984
3>중심극한정리에 의하여 100일 후의 가격이 210 이상일 확률
https://knowallworld.tistory.com/303
★lineplot★중심극한정리★기초통계학-[모집단 분포와 표본분포 -04]
1. 중심극한정리 ==> 정규분포가 아닌 모집단 분포로부터 복원추출로 표본 선정시 ==> 표본의 크기에 따라 표본평균의 표본분포가 변한다. ==> 모평균 뮤 , 모분산(o**2) 의 임의의 모집단으로부터
knowallworld.tistory.com
시그마_|X ~ N(0.04 * 100 , 0.9984 * 100) = N(4 , 99.84) = N(4 , 9.99**2)
X ~ N(4 + 200 , 9.99**2)
P(X>=210) = 1- P(Z<= 210 - 204 / 9.99 ) = P(0.6<=Z) = 0.2743
x = np.arange(-5,5 , .001)
fig = plt.figure(figsize=(15,8))
ax = sns.lineplot(x , stats.norm.pdf(x, loc=0 , scale =1)) #정의역 범위 , 평균 = 0 , 표준편차 =1 인 정규분포 플롯
z_1 = round((210 - 204) / 9.99 ,2)
# z_2 = round((196.82- 198) / 3.45 ,2)
ax.fill_between(x, stats.norm.pdf(x, loc=0 , scale =1) , 0 , where = (x>=z_1) , facecolor = 'skyblue') # x값 , y값 , 0 , x<=0 인곳 , 색깔
area = 1- (stats.norm.cdf((z_1)))
ax.text(1.71 , .17, f'P({z_1}<=Z) : {round(area,4)}',fontsize=15)
plt.annotate('' , xy=(0.7, .17), xytext=(1.7 , .17) , arrowprops = dict(facecolor = 'black'))
# ax.vlines(x= z_2, ymin= 0 , ymax= stats.norm.pdf(z_2, loc=0 , scale =1) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
ax.vlines(x= z_1, ymin= 0 , ymax= stats.norm.pdf(z_1, loc=0 , scale =1) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))15. 음주운전 단속에서 100일간 면허 정지 처분을 받은 사람들의 혈중 알코올 농도를 측정한 결과, 평균 0.075이고, 표준편차가 0.009라고 한다. 64명이 면허 정지 처분을 받았다고 하자.
==> 표본평균의 표준정규분포
1> 면허 정지 처분을 받은 사람들의 알코올 농도의 평균에 관한 표본분포를 구하라.
n = 64
n = 64
X ~ N(0.075 , 0.009**2)
|X ~ N(0.075 , 0.009**2/ 64)
2> 평균 혈중 알코올 농도가 0.077이상일 확률
P(|X>= 0.077) = P(Z>= 0.077 - 0.075 / 루트(0.009/64) ) = 1 - P(Z<= 0.077 - 0.075 / 루트(0.009/64) ) = P(Z>0.17) = 0.4325
x = np.arange(-5,5 , .001)
fig = plt.figure(figsize=(15,8))
ax = sns.lineplot(x , stats.norm.pdf(x, loc=0 , scale =1)) #정의역 범위 , 평균 = 0 , 표준편차 =1 인 정규분포 플롯
z_1 = round((0.077 - 0.075) / math.sqrt(0.009**2/64) ,2)
# z_2 = round((196.82- 198) / 3.45 ,2)
ax.fill_between(x, stats.norm.pdf(x, loc=0 , scale =1) , 0 , where = (x>=z_1) , facecolor = 'skyblue') # x값 , y값 , 0 , x<=0 인곳 , 색깔
area = 1- (stats.norm.cdf((z_1)))
ax.text(1.71 , .17, f'P({z_1}<=Z) : {round(area,4)}',fontsize=15)
plt.annotate('' , xy=(2.1, .017), xytext=(2.1 , .14) , arrowprops = dict(facecolor = 'black'))
# ax.vlines(x= z_2, ymin= 0 , ymax= stats.norm.pdf(z_2, loc=0 , scale =1) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
ax.vlines(x= z_1, ymin= 0 , ymax= stats.norm.pdf(z_1, loc=0 , scale =1) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
16. 주택을 소유한 모든 사람들의 화재로 인한 연간 평균 손실이 25만원이고, 표준편차는 100만원, 손실 금액은 거의 대부분이 0원이고 단지 몇몇 손실이 매우 크게 나타나는 양의 비대칭분포, 1000명 대상으로 조사
1>표본평균의 표본분포
n = 1000
뮤 = 25
모분산 = 100**2
|X ~ N(25 , 100/1000)
2>표본평균이 28만원을 초과하지 않을 확률
x = np.arange(-5,5 , .001)
fig = plt.figure(figsize=(15,8))
ax = sns.lineplot(x , stats.norm.pdf(x, loc=0 , scale =1)) #정의역 범위 , 평균 = 0 , 표준편차 =1 인 정규분포 플롯
z_1 = round((28-25) / math.sqrt(100**2/1000) ,2)
# z_2 = round((196.82- 198) / 3.45 ,2)
ax.fill_between(x, stats.norm.pdf(x, loc=0 , scale =1) , 0 , where = (x<=z_1) , facecolor = 'skyblue') # x값 , y값 , 0 , x<=0 인곳 , 색깔
area = (stats.norm.cdf((z_1)))
ax.text(-3.71 , .16, f'P(Z<={z_1}) : {round(area,4)}',fontsize=15)
plt.annotate('' , xy=(-1.1, .14), xytext=(-2.1 , .14) , arrowprops = dict(facecolor = 'black'))
# ax.vlines(x= z_2, ymin= 0 , ymax= stats.norm.pdf(z_2, loc=0 , scale =1) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
ax.vlines(x= z_1, ymin= 0 , ymax= stats.norm.pdf(z_1, loc=0 , scale =1) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
P(|X<28) = P(Z< 28-25 / 루트(100/1000) ) = P(Z<= 0.95) = 0.8289
17. 이종격투기 선수들의 평균 악력은 90kg , 표준편차 9kg
1> 36명의 선수를 선정시 , 평균 악력이 87kg과 93kg 사이일 근사확률
n = 36
뮤 = 90
s = 9
|X ~ N(90 , 9**2 / 36)
P(87<= |X <= 93) = [ P(93-90 / 루트(9**2/36) <= Z) - P(Z<=0) ] * 2 = P(-2<=Z<=2) = 0.9545
x = np.arange(-5,5 , .001)
fig = plt.figure(figsize=(15,8))
ax = sns.lineplot(x , stats.norm.pdf(x, loc=0 , scale =1)) #정의역 범위 , 평균 = 0 , 표준편차 =1 인 정규분포 플롯
z_1 = round((93-90) / math.sqrt(9**2 / 36 ) ,2)
# z_2 = round((34.5 - 35) / math.sqrt(5.5**2 / 25) , 2)
ax.fill_between(x, stats.norm.pdf(x, loc=0 , scale =1) , 0 , where = (x<=z_1) & (x>=-z_1) , facecolor = 'skyblue') # x값 , y값 , 0 , x<=0 인곳 , 색깔
area = (stats.norm.cdf((z_1)) - stats.norm.cdf(0)) * 2
ax.text(1.71 , .17, f'P({-z_1}<=Z<={z_1}) : {round(area,4)}',fontsize=15)
plt.annotate('' , xy=(0, .17), xytext=(1.7 , .17) , arrowprops = dict(facecolor = 'black'))
ax.vlines(x= -z_1, ymin= 0 , ymax= stats.norm.pdf(z_1, loc=0 , scale =1) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
ax.vlines(x= z_1, ymin= 0 , ymax= stats.norm.pdf(z_1, loc=0 , scale =1) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))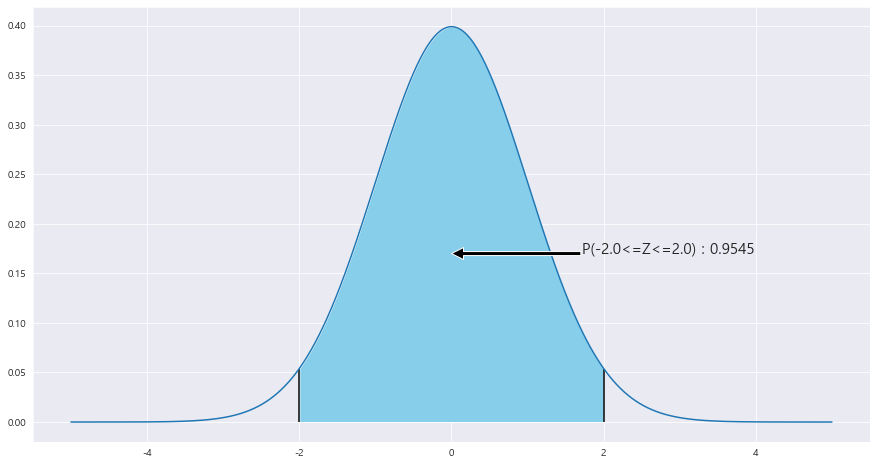
2> 64명의 선수를 선정시 , 평균 악력이 87kg과 93kg 사이일 근사확률

P(-2.67<=Z<=2.67) = 0.9924
18. 모분산이 0.35인 정규모집단으로부터 크기 8인 표본을 추출한다.
https://knowallworld.tistory.com/305
★표본분산 S**2 , 관찰 표본분산 s_0**2★카이제곱분포표★모분산의 표본분포★기초통계학-[모집
1. 모분산의 표본분포 정규모집단 N(뮤 , 모분산) 으로부터 크기 n인 표본을 선정할 때 표본분산 ==> 표본분산 S**2에 대한 표본분포는 X**2-통계량 V에 대하여 자유도가 n-1인 카이제곱분포이다. https:
knowallworld.tistory.com
==> 카이제곱분포

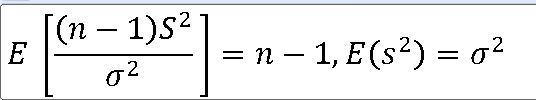
1> 표본분산과 관련된 통계량 V = (n-1)**2 * S**2 / 모분산 의 분포를 구하라.
모분산 = 0.35
크기 = 8
V = (8-1)*S**2 / 0.35 ~ X**2(7)
2> 표본조사한 결과가 다음과 같을 때 관찰된 표본분산의 값 s_0**2을 구하라.
2.5 , 2.1 , 3.4 , 1.7 , 2.0 , 3.2 , 2.8 , 2.4
a = [2.5 , 2.1 , 3.4 , 1.7 , 2.0 , 3.2 , 2.8 , 2.4]
print(np.var(a , ddof =1 ))표본분산 = 0.3498
3> P(S**2 < s_1) = 0.05를 만족하는 s_1을 구하라.
P(X < 7*s_1 / 0.35) = 0.05
7*s_1**2 /0.35 = 14.07
s_1 = 0.1083
x = np.arange(0,30 , .001)
dof = 7
a = [2.5 , 2.1 , 3.4 , 1.7 , 2.0 , 3.2 , 2.8 , 2.4]
print(np.var(a , ddof =1 ))
fig = plt.figure(figsize=(15,8))
ax = sns.lineplot(x , scipy.stats.chi2(dof).pdf(x)) #정의역 범위 , 평균 = 0 , 표준편차 =1 인 정규분포 플롯
X_r = scipy.stats.chi2(dof).ppf(0.05)
print(X_r)
ax.fill_between(x, scipy.stats.chi2(dof).pdf(x) , where = (x<=X_r) , facecolor = 'skyblue') # x값 , y값 , 0 , x조건 인곳 , 색깔
area = scipy.stats.chi2(dof).cdf(X_r) #넓이 구하기!!!!!
print(area)
ax.text(-2 , .017, 'P(X <' + r'$\chi^2_{0.95})$' + f"= {round(area,4)}" ,fontsize=12)
plt.annotate('' , xy=(1, .002), xytext=(0 , .014) , arrowprops = dict(facecolor = 'black'))
ax.vlines(x= X_r, ymin= 0 , ymax= scipy.stats.chi2(dof).pdf(X_r) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
ax.text(X_r+1 , .048, r'$\chi^2_R= {}$'.format(round(X_r,2)) ,fontsize=15)
plt.annotate('' , xy=(2.2, .025), xytext=(5 , .044) , arrowprops = dict(facecolor = 'black'))
b = [r'$\chi^2(\eta$ = {})'.format(dof)]
plt.legend(b , fontsize = 15)
s = Symbol('s')
print(solve( (7*(s))/0.35 - X_r))
4> P(S**2 > s_2) = 0.05를 만족하는 s_2을 구하라.
x = np.arange(0,30 , .001)
dof = 7
a = [2.5 , 2.1 , 3.4 , 1.7 , 2.0 , 3.2 , 2.8 , 2.4]
print(np.var(a , ddof =1 ))
fig = plt.figure(figsize=(15,8))
ax = sns.lineplot(x , scipy.stats.chi2(dof).pdf(x)) #정의역 범위 , 평균 = 0 , 표준편차 =1 인 정규분포 플롯
X_r = scipy.stats.chi2(dof).ppf(0.95)
print(X_r)
ax.fill_between(x, scipy.stats.chi2(dof).pdf(x) , where = (x>=X_r) , facecolor = 'skyblue') # x값 , y값 , 0 , x조건 인곳 , 색깔
area = 1- scipy.stats.chi2(dof).cdf(X_r) #넓이 구하기!!!!!
print(area)
ax.text(20 , .015, 'P(X >' + r'$\chi^2_{0.05})$' + f"= {round(area,4)}",fontsize=15)
plt.annotate('' , xy=(17, .002), xytext=(20 , .014) , arrowprops = dict(facecolor = 'black'))
ax.vlines(x= X_r, ymin= 0 , ymax= scipy.stats.chi2(dof).pdf(X_r) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
ax.text(X_r - 8, .01, r'$\chi^2_R= {}$'.format(round(X_r,2)) ,fontsize=15)
plt.annotate('' , xy=(14, .01), xytext=(10 , .01) , arrowprops = dict(facecolor = 'black'))
b = [r'$\chi^2(\eta$ = {})'.format(dof)]
print(b)
plt.legend(b , fontsize = 15)
s = Symbol('s')
print(solve( (7*(s))/0.35 - X_r))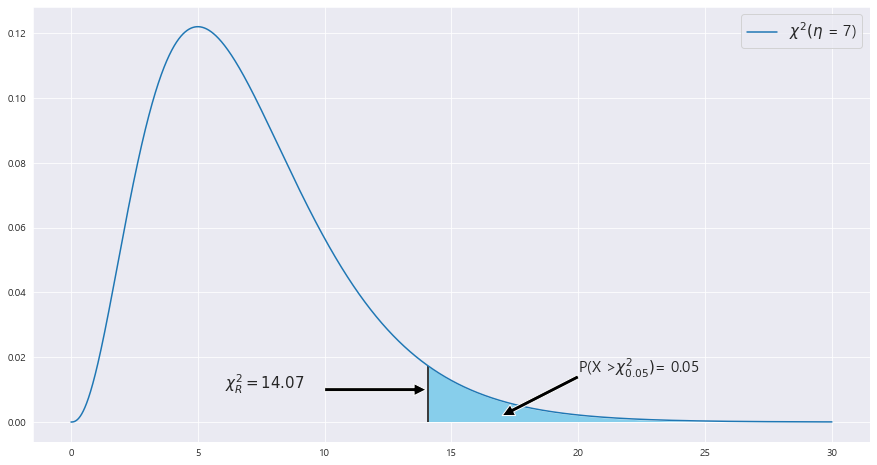
s = Symbol('s')
print(solve( (7*(s))/0.35 - X_r))s = 0.7033
19. 건강한 성인이 하루에 소비하는 물의 양은 평균 1.5L , 분산 0.04761인 정규분포 따른다. 10명의 성인을 무작위로 선정하여 하루 동안 소비하는 물의 양 측정
1> 표본분산과 관련된 통계량 V = (n-1)*S**2 / 모분산 의 분포를 구하라.
n = 10
모분산 = 0.04761
V = (10-1)*S**2 / 0.04761 ~ X**2(9)
2> 표본조사한 결과가 [1.5 , 1.6 , 1.2 , 1.7 , 1.4 , 1.3 , 1.6 , 1.3 , 1.4 , 1.7] , 관찰된 표본분산의 값 s_0**2 를 구하라.
a = [1.5 , 1.6 , 1.2 , 1.7 , 1.4 , 1.3 , 1.6 , 1.3 , 1.4 , 1.7]
print(np.var(a, ddof =1 ))
s_0**2 = 0.0312
3> 이 표본을 이용하여 통계량의 관찰값 카이제곱값을 구하라.
X_0**2 = 9* 0.0312 / 0.04761 = 5.9021
4> 표본분산 S**2이 s_0**2보다 클 확률
자유도 = 9
P(S**2 >= s_0**2) = P(9*S**2 / 0.04761 >= 9*s_0**2 / 0.04761) = P(V>= 9*s_0**2 / 0.04761) = P(V>= 5.9021) = 0.7497
fig = plt.figure(figsize=(15,8))
ax = sns.lineplot(x , scipy.stats.chi2(dof).pdf(x)) #정의역 범위 , 평균 = 0 , 표준편차 =1 인 정규분포 플롯
X_r = scipy.stats.chi2(dof).ppf(0.95)
print(X_r)
X_r = 5.9021
ax.fill_between(x, scipy.stats.chi2(dof).pdf(x) , where = (x>=X_r) , facecolor = 'skyblue') # x값 , y값 , 0 , x조건 인곳 , 색깔
area = 1- scipy.stats.chi2(dof).cdf(X_r) #넓이 구하기!!!!!
print(area)
ax.text(20 , .015, 'P(X >' + r'$\chi^2_{0.05})$' + f"= {round(area,4)}",fontsize=15)
plt.annotate('' , xy=(17, .002), xytext=(20 , .014) , arrowprops = dict(facecolor = 'black'))
ax.vlines(x= X_r, ymin= 0 , ymax= scipy.stats.chi2(dof).pdf(X_r) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
ax.text(X_r - 3.5, .015, r'$\chi^2_R= {}$'.format(round(X_r,2)) ,fontsize=15)
plt.annotate('' , xy=(5.9, .01), xytext=(2 , .01) , arrowprops = dict(facecolor = 'black'))
b = [r'$\chi^2(\eta$ = {})'.format(dof)]
print(b)
plt.legend(b , fontsize = 15)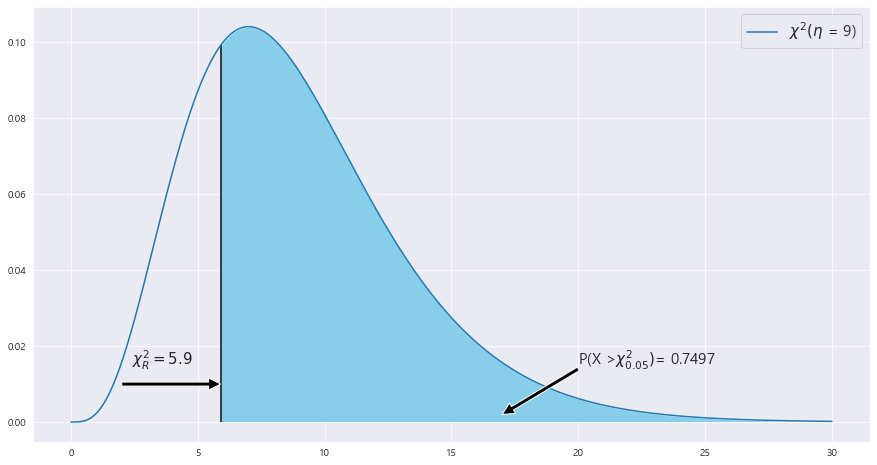
5> P(S**2 > s_1**2) = 0.025인 s_1**2을 구하라.
P(V > 9*s_1**2 / 0.04761) = 0.025
9*s_1**2 / 0.04761 = 19.02
s_1**2 = 0.1006
x = np.arange(0,30 , .001)
dof = 9
a = [1.5 , 1.6 , 1.2 , 1.7 , 1.4 , 1.3 , 1.6 , 1.3 , 1.4 , 1.7]
print(np.var(a , ddof =1 ))
fig = plt.figure(figsize=(15,8))
ax = sns.lineplot(x , scipy.stats.chi2(dof).pdf(x)) #정의역 범위 , 평균 = 0 , 표준편차 =1 인 정규분포 플롯
X_r = scipy.stats.chi2(dof).ppf(1- 0.025)
print(X_r)
# X_r = 5.9021
ax.fill_between(x, scipy.stats.chi2(dof).pdf(x) , where = (x>=X_r) , facecolor = 'skyblue') # x값 , y값 , 0 , x조건 인곳 , 색깔
area = 1- scipy.stats.chi2(dof).cdf(X_r) #넓이 구하기!!!!!
print(area)
ax.text(25 , .015, 'P(X >' + r'$\chi^2_{0.025})$' + f"= {round(area,4)}",fontsize=15)
plt.annotate('' , xy=(22, .002), xytext=(25 , .014) , arrowprops = dict(facecolor = 'black'))
ax.vlines(x= X_r, ymin= 0 , ymax= scipy.stats.chi2(dof).pdf(X_r) , color = 'black' , linestyle ='solid' , label ='{}'.format(2))
ax.text(X_r - 3.5, .008, r'$\chi^2_R= {}$'.format(round(X_r,2)) ,fontsize=15)
plt.annotate('' , xy=(19, .005), xytext=(15 , .005) , arrowprops = dict(facecolor = 'black'))
b = [r'$\chi^2(\eta$ = {})'.format(dof)]
print(b)
plt.legend(b , fontsize = 15)
s = Symbol('s')
print(solve( (dof*(s))/0.04761 - X_r))
https://knowallworld.tistory.com/305
★표본분산 S**2 , 관찰 표본분산 s_0**2★카이제곱분포표★모분산의 표본분포★기초통계학-[모집
1. 모분산의 표본분포 정규모집단 N(뮤 , 모분산) 으로부터 크기 n인 표본을 선정할 때 표본분산 ==> 표본분산 S**2에 대한 표본분포는 X**2-통계량 V에 대하여 자유도가 n-1인 카이제곱분포이다. https:
knowallworld.tistory.com
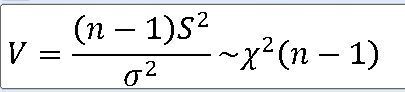

==>카이제곱분포는 정규모집단의 모분산에 대한 통계적 추론에 사용
출처 : [쉽게 배우는 생활속의 통계학] [북스힐 , 이재원]
※혼자 공부 정리용
'기초통계 > 표본분포' 카테고리의 다른 글
| ★표본평균의 차에 대한 절대값 처리★두 표본평균의 차에 따른 표준정규분포★기초통계학-[연습문제02 -19] (0) | 2023.01.11 |
|---|---|
| ★표본비율의 표본분포에 대한 정규분포 근사★표본비율★N(모평균 , 모평균*(1-모평균) / 전체표본개수★기초통계학-[연습문제02 -18] (1) | 2023.01.11 |
| ★모분산을 모를때는 t-분포★기초통계학-[연습문제02 -16] (0) | 2023.01.09 |
| ★Solve()이후 float로의 변환★크기를 알때/모를때의 표본평균의 표준분포★기초통계학-[연습문제02 -15] (0) | 2023.01.09 |
| ★표본평균의 정규분포(표본평균 = 모평균 , 표본분산 = 모분산/크기)★모분산 모를때 정규표본 추출★기초통계학-[연습문제02 -14] (0) | 2023.01.09 |