전체 글
-
[Python] 백준 8958번 ox퀴즈2022.09.14
-
[Python] 백준 2562번 최대값2022.09.14
-
[Python] set로 활용해보기(set활용) 백준 2480번 주사위세게 문제2022.09.13
-
[GITHUB] Branch 활용하기2022.09.10
-
데이터정제_데이터실수화2022.07.24
-
ORACLE_SQL 설치부터 SQL_DEVELOPER 까지(오류 해결)2022.07.08
[Python] 백준 8958번 ox퀴즈

import sys
T = int(sys.stdin.readline())
res = []
for k in range(T):
point = 0
sum = 0
A = list(map(str, sys.stdin.readline().rstrip()))
for i in range(len(A)):
if A.pop() == 'O':
point+=1
sum+=point
else:
point =0
res.append(sum)
for p in res:
print(p)'Python(백준) > 배열' 카테고리의 다른 글
| [백준 파이썬 11003번]최솟값 찾기★VER2.0★시간초과 고려 (0) | 2022.12.29 |
|---|---|
| [백준 파이썬 12891번]좋다★DNA 비밀번호★WINDOWS SLIDING★VER2.0★시간초과 고려 (0) | 2022.12.29 |
| [Python] 백준 2562번 최대값 (0) | 2022.09.14 |
| [백준 파이썬 4344번]1차원 배열, 평균은 넘겠지 ★객체LIST저장방법★but아직 미구현 (0) | 2021.07.31 |
| [백준 파이썬 8958번]1차원 배열, OX 퀴즈 ★객체LIST저장방법★ (0) | 2021.07.30 |
[Python] 백준 2562번 최대값

import sys
res = []
for i in range(9):
A= int(sys.stdin.readline())
res.append(A)
b = max(res)
for i in range(9):
if res[i] == b:
res2= i+1
break
print(b)
print(res2)'Python(백준) > 배열' 카테고리의 다른 글
| [백준 파이썬 12891번]좋다★DNA 비밀번호★WINDOWS SLIDING★VER2.0★시간초과 고려 (0) | 2022.12.29 |
|---|---|
| [Python] 백준 8958번 ox퀴즈 (0) | 2022.09.14 |
| [백준 파이썬 4344번]1차원 배열, 평균은 넘겠지 ★객체LIST저장방법★but아직 미구현 (0) | 2021.07.31 |
| [백준 파이썬 8958번]1차원 배열, OX 퀴즈 ★객체LIST저장방법★ (0) | 2021.07.30 |
| [백준 파이썬 3052번]1차원 배열, 평균구하기 ★객체저장방법(map)★ (0) | 2021.07.29 |
[Python] set로 활용해보기(set활용) 백준 2480번 주사위세게 문제
import sys
while True :
a = list(map(int, sys.stdin.readline().split()))
#print(set(a))
if len(a) ==3:
break
else:
print("주사위는 3번만 굴려!")
# if a & b & c == True
a.sort(reverse=True)
#print(a)
b = list(set(a))
b.sort(reverse=True)
# # print(b)
cnt = 0
res = 0
if len(b) == 3:
print(max(b) *100)
elif len(b)==2:
for i in range(len(b)):
for j in range(len(a)):
if b[i] == a[j]:
cnt+=1
if cnt ==2 :
res = b[i]
else:
cnt=0
print(a)
print(b)
print(1000 + res*100)
else:
print(10000+a[0]*1000)'Python(백준) > if' 카테고리의 다른 글
| [Python] Input 함수에 범위를 지정해보자!(While 문 활용) 백준 14681번 사분면 문제★VER2.0 (2) | 2022.12.29 |
|---|---|
| Python(백준)/if[Python] 백준 2525번 오븐 시계 (0) | 2022.06.24 |
| [Python] Input 함수에 범위를 지정해보자!_02번(While 문 활용) 백준 2884번 알람 문제 (0) | 2021.07.24 |
Could not fetch URL https://pypi.org/simple/missingno/
pip install --trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pypi.org --upgrade pip
python 먼저 최신파일 설치
하면 해결 완료
'IT에대해 알아보자 > 쥬피터(ANACONDA)' 카테고리의 다른 글
| JETBRAINS(INTELLIJ , DATASPELL 등) 한국어 설치하는 방법 (0) | 2023.01.08 |
|---|---|
| ★TensorFlow 설치★Keras 설치★ in Anaconda Prompt (0) | 2022.11.28 |
| anaconda 파이썬 업데이트시 생기는 오류 해결 (0) | 2022.10.19 |
| 쥬피터(아나콘다) 가상화 사용하기(anaconda Virtual environment) (0) | 2022.07.25 |
| 데이터정제_데이터실수화 (0) | 2022.07.24 |
[GITHUB] Branch 활용하기
'IT에대해 알아보자 > 깃허브사용법' 카테고리의 다른 글
| GIT HUB 와 DATA SPELL 연동하기(COMMIT & PULL & UPDATE) (1) | 2022.11.29 |
|---|---|
| GIT HUB LFS(100mb넘는 대용량 파일 커밋) 사용하기 (0) | 2022.09.16 |
| 왕초보도 따라할수 있는 GITHUB 설치 및 로그인[GITHUB 다뤄보기-1] (0) | 2021.07.09 |
| 왕초보도 따라할수 있는 GITHUB 레파라토지(Repositories) 생성[GITHUB 다뤄보기-2] (0) | 2021.06.28 |
| 왕초보도 따라할수 있는 깃허브 레파라토지(Repositories)에 업로드하는법 [Git Bash, Git HUB 다뤄보기 -3] (0) | 2021.06.28 |
쥬피터(아나콘다) 가상화 사용하기(anaconda Virtual environment)

1. (BASE) C:\Users\user> ===> BASE 환경에서 작동하는 것으로서 내꺼에는 PYTHON 3.9버전이 설치되어있다.
2. conda env list ===> 내 컴퓨터의 anaconda 환경들의 상태를 볼 수 있다.
3. conda create test_env python=3.8 ===> python 3.8 버전의 test_env 이름으로된 anaconda 가상화환경 설치하겠다.
4. conda activate test_env ===> test_env 의 가상화 환경이 작동한다.

4. test_env의 환경에 들어와서 jupyter notebook 실행한다.
'IT에대해 알아보자 > 쥬피터(ANACONDA)' 카테고리의 다른 글
| JETBRAINS(INTELLIJ , DATASPELL 등) 한국어 설치하는 방법 (0) | 2023.01.08 |
|---|---|
| ★TensorFlow 설치★Keras 설치★ in Anaconda Prompt (0) | 2022.11.28 |
| anaconda 파이썬 업데이트시 생기는 오류 해결 (0) | 2022.10.19 |
| Could not fetch URL https://pypi.org/simple/missingno/ (0) | 2022.09.13 |
| 데이터정제_데이터실수화 (0) | 2022.07.24 |
데이터정제_데이터실수화
import pandas as pd #pandas package 임포트
from sklearn.preprocessing import LabelEncoder #범주형 데이터의 실수화 함수 임포트
#from 모듈 import 이름
#sklearn 모듈
from sklearn.preprocessing import OneHotEncoder #더미변수 생성, 가변환 함수 임포트
x_train = pd.DataFrame(["남성" , "여성" , "남성" , "여성" , "남성" , "여성"], columns=["성별"])
#열이 성별인 DataFrame 생성
#남성 여성 남성 여성 남성 여성인 행 생성
x_train.head(3)
#x_train dataframe의 대표 3행 출력
| 성별 | |
|---|---|
| 0 | 남성 |
| 1 | 여성 |
| 2 | 남성 |
x_train.info() #x_train의 정보 출력
#데이터 프레임의 정보 확인 : object 타입 '성별' 변수
<class 'pandas.core.frame.DataFrame'> RangeIndex: 6 entries, 0 to 5 Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 성별 6 non-null object dtypes: object(1) memory usage: 176.0+ bytes
x_train['성별'].value_counts() #범주형 데이터의 개수 확인
남성 3 여성 3 Name: 성별, dtype: int64
#레이블 인코더 생성
encoing = LabelEncoder()
#sklearn.preprocessing 모듈에서 받은 LabelEncoder 라이브러리 함수를 encoing 변수로 받아들인다.
#X_train 데이터를 이용하여 피팅하고 레이블 숫자로 변환
encoing.fit(x_train["성별"]) #성별 열의 데이터를 범주형 데이터로 fit
LabelEncoder()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LabelEncoder()
x_train["성별_인코딩"] = encoing.transform(x_train["성별"])
#x_train dataframe 의 성별_인코딩 열 추가하여
#레이블 인코더로 변환할 x_train의 성별열의 행들 범주형 데이터로 변환한다.
x_train
| 성별 | 성별_인코딩 | |
|---|---|---|
| 0 | 남성 | 0 |
| 1 | 여성 | 1 |
| 2 | 남성 | 0 |
| 3 | 여성 | 1 |
| 4 | 남성 | 0 |
| 5 | 여성 | 1 |
print(list(encoing.classes_)) #클래스 확인
print(list(encoing.inverse_transform([1,0]))) #인코딩 값으로 문자값 확인
['남성', '여성'] ['여성', '남성']
#One-Hot Encoding : 더미변수 생성 , 가변환
x_train.head(2) #데이터 확인(실수화한 데이터 사용)
| 성별 | 성별_인코딩 | |
|---|---|---|
| 0 | 남성 | 0 |
| 1 | 여성 | 1 |
#2) One-Hot Encoding
#원핫인코더 생성
#sparse를 True로 할 경우 "(행,열) 1"의 좌표리스트의 형식, False로 할 경우 넘파이 배열로 변환
one_encoding = OneHotEncoder(sparse= False) #넘파이 배열
#X_train 데이터를 이용하여 피팅
one_encoding.fit(x_train[["성별"]]) #피팅이란 학습 시키는 것
#가변환값 변환
one_encoding.transform(x_train[["성별"]])
#x_train 데이터프레임의 성별
#one_encoding.fit_transform(x_train[["성별"]])
array([[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.]])
#가변화된 피쳐 확인
print(one_encoding.get_feature_names())
['x0_남성' 'x0_여성']
C:\Users\user\anaconda3\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead. warnings.warn(msg, category=FutureWarning)
#가변화된 값을 x_train_one 데이터 프레임으로 저장
x_train_one = pd.DataFrame(one_encoding.transform(x_train[['성별']]),
columns= ['성별0','성별1'])
#x_train 데이터와 x_train_one의 가변화된 속성 합침
x_train = pd.concat([x_train, x_train_one], axis = 1)
#결과확인
x_train.head(3)
| 성별 | 성별_인코딩 | 성별0 | 성별1 | |
|---|---|---|---|---|
| 0 | 남성 | 0 | 1.0 | 0.0 |
| 1 | 여성 | 1 | 0.0 | 1.0 |
| 2 | 남성 | 0 | 1.0 | 0.0 |
from sklearn.feature_extraction.text import CountVectorizer
#문서 집합에서 단어 토큰을 생성하고 각 단어의 수를 세어 Bag Of Words 로 인코딩하는 함수
corpus = [
'청년 인재 개발 양성 과정',
'인공지능 청년 양성',
'미래 인공지능 데이터 대한민국',
'데이터 원유 기술사 청년 개발'
]
corpus
['청년 인재 개발 양성 과정', '인공지능 청년 양성', '미래 인공지능 데이터 대한민국', '데이터 원유 기술사 청년 개발']
type(corpus)
list
#카운트 벡터라이저 생성
count_vect = CountVectorizer()
#단어 카운트
count_vect.fit(corpus)
#단어 확인
count_vect.vocabulary_
{'청년': 10,
'인재': 9,
'개발': 0,
'양성': 6,
'과정': 1,
'인공지능': 8,
'미래': 5,
'데이터': 4,
'대한민국': 3,
'원유': 7,
'기술사': 2}
#단어 벡터화한 값을 array로 변환하여 확인
count_vect.transform(corpus).toarray()
array([[1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1],
[0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0],
[1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1]], dtype=int64)
#단어 벡터화
features = count_vect.transform(corpus)
features
<4x11 sparse matrix of type '<class 'numpy.int64'>' with 17 stored elements in Compressed Sparse Row format>
#4) 문서 단어 행렬로 변환
#속성 이름만 반환
vocab = count_vect.get_feature_names()
vocab
C:\Users\user\anaconda3\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead. warnings.warn(msg, category=FutureWarning)
['개발', '과정', '기술사', '대한민국', '데이터', '미래', '양성', '원유', '인공지능', '인재', '청년']
#문서단어행렬(DTM)을 데이터 프레임으로 변환
DTM = pd.DataFrame(features.toarray(), columns = vocab).head()
DTM
| 개발 | 과정 | 기술사 | 대한민국 | 데이터 | 미래 | 양성 | 원유 | 인공지능 | 인재 | 청년 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
| 2 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| 3 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
#문서단어행렬에 일치하는 단어 확인
count_vect.transform(['기술사 대한민국 인재 만세']).toarray()
array([[0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0]], dtype=int64)
#TF-IDF : 단어의 빈도와 역 문서 빈도를 사용하여 DTM내의 각 단어들마다 중요한 정도를 가중치로 주는 방법
#TF-IDF 값이 낮으면 중요도가 낮은 것이며, TF-IDF값이 크면 중요도가 큰것이다.
from sklearn.feature_extraction.text import TfidfVectorizer
#Tfid'f'
corpus
['청년 인재 개발 양성 과정', '인공지능 청년 양성', '미래 인공지능 데이터 대한민국', '데이터 원유 기술사 청년 개발']
#TF-IDF 벡터라이저 생성
tfid = TfidfVectorizer()
#단어 카운트
tfid.fit(corpus)
TfidfVectorizer()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
TfidfVectorizer()
#단어사전 확인
tfid.vocabulary_
{'청년': 10,
'인재': 9,
'개발': 0,
'양성': 6,
'과정': 1,
'인공지능': 8,
'미래': 5,
'데이터': 4,
'대한민국': 3,
'원유': 7,
'기술사': 2}
#단어 벡터화한 값을 array로 변환하여 확인
tfid.transform(corpus).toarray()
array([[0.41263976, 0.52338122, 0. , 0. , 0. ,
0. , 0.41263976, 0. , 0. , 0.52338122,
0.33406745],
[0. , 0. , 0. , 0. , 0. ,
0. , 0.61366674, 0. , 0.61366674, 0. ,
0.49681612],
[0. , 0. , 0. , 0.55528266, 0.43779123,
0.55528266, 0. , 0. , 0.43779123, 0. ,
0. ],
[0.41263976, 0. , 0.52338122, 0. , 0.41263976,
0. , 0. , 0.52338122, 0. , 0. ,
0.33406745]])
#단어 벡터화
features_idf = tfid.transform(corpus)
features_idf
<4x11 sparse matrix of type '<class 'numpy.float64'>' with 17 stored elements in Compressed Sparse Row format>
#4) 문서 단어행렬로 변환
#속성 이름만 반환
vocab_idf= count_vect.get_feature_names()
C:\Users\user\anaconda3\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead. warnings.warn(msg, category=FutureWarning)
vocab_idf
['개발', '과정', '기술사', '대한민국', '데이터', '미래', '양성', '원유', '인공지능', '인재', '청년']
#문서단어행렬(DTM)을 데이터 프레임으로 변환
DTM_idf = pd.DataFrame(features_idf.toarray(), columns = vocab_idf).head()
DTM_idf
| 개발 | 과정 | 기술사 | 대한민국 | 데이터 | 미래 | 양성 | 원유 | 인공지능 | 인재 | 청년 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.41264 | 0.523381 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.412640 | 0.000000 | 0.000000 | 0.523381 | 0.334067 |
| 1 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.613667 | 0.000000 | 0.613667 | 0.000000 | 0.496816 |
| 2 | 0.00000 | 0.000000 | 0.000000 | 0.555283 | 0.437791 | 0.555283 | 0.000000 | 0.000000 | 0.437791 | 0.000000 | 0.000000 |
| 3 | 0.41264 | 0.000000 | 0.523381 | 0.000000 | 0.412640 | 0.000000 | 0.000000 | 0.523381 | 0.000000 | 0.000000 | 0.334067 |
'IT에대해 알아보자 > 쥬피터(ANACONDA)' 카테고리의 다른 글
| JETBRAINS(INTELLIJ , DATASPELL 등) 한국어 설치하는 방법 (0) | 2023.01.08 |
|---|---|
| ★TensorFlow 설치★Keras 설치★ in Anaconda Prompt (0) | 2022.11.28 |
| anaconda 파이썬 업데이트시 생기는 오류 해결 (0) | 2022.10.19 |
| Could not fetch URL https://pypi.org/simple/missingno/ (0) | 2022.09.13 |
| 쥬피터(아나콘다) 가상화 사용하기(anaconda Virtual environment) (0) | 2022.07.25 |
ORACLE_SQL 설치부터 SQL_DEVELOPER 까지(오류 해결)
1. ORACLE 홈페이지 21c 다운로드(22.07.08 기준 최신버전)


캡쳐를 잘 못했지만 경로 설정부분 default로 되어있는 거 체크하고 그냥 계속 다음 누른다.
==> 관리자 계정 설정시
아이디 : system
비밀번호 : 1234
==> 어쩌구어쩌구 하는데 무시하고 생성
SQL DEVELOPER
================================================================
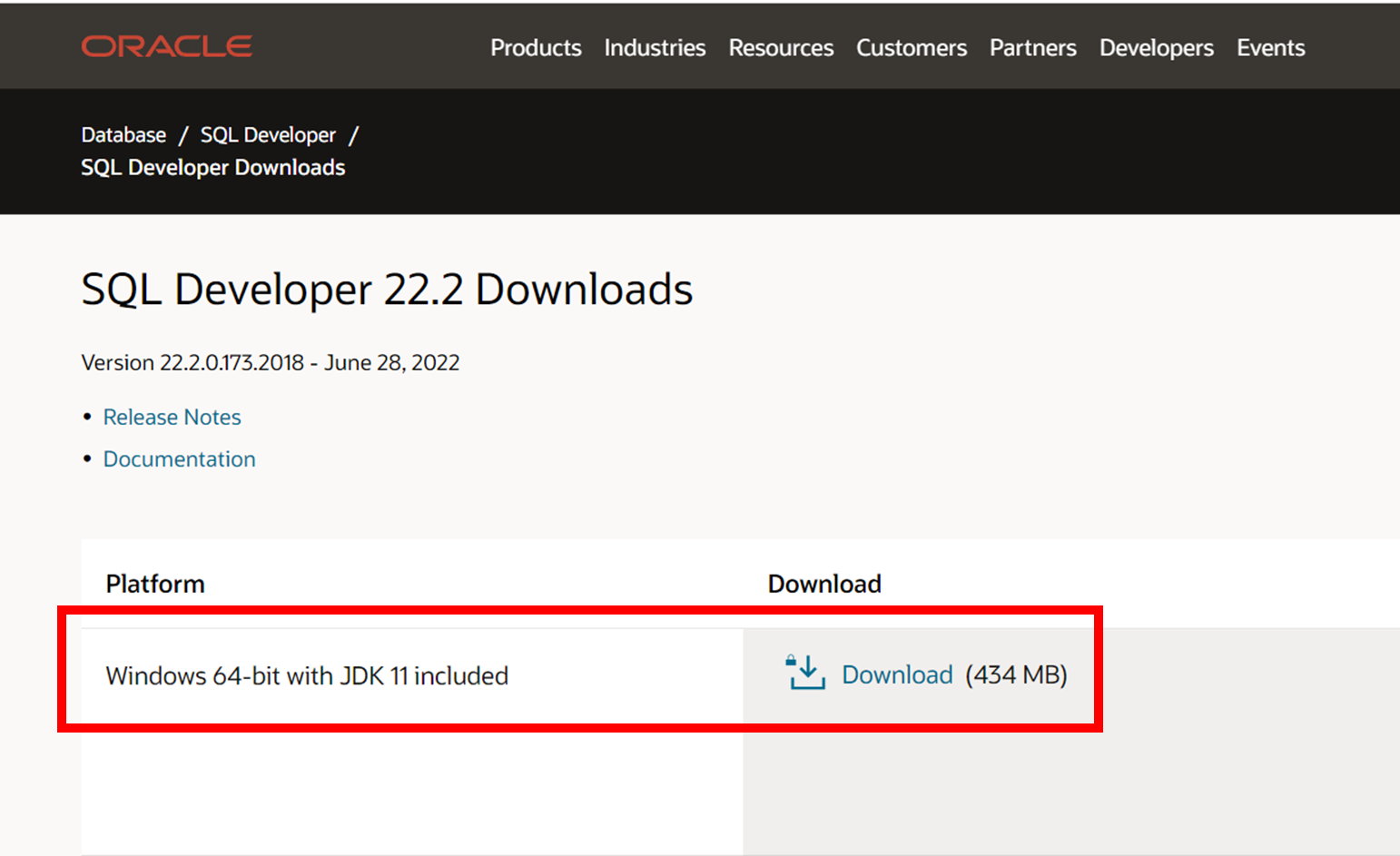
1. SQL > sqlplus system/1234
==> 내가 ORACLE 설치 할때 초기설정
2. SCOTT 대소문자 구분
3. ALTER SESSION SET "_ORACLE_SCRIPT"=true;
==> ORACLE 최신버전 부터 사용자명에 c##을 붙여야 하지만, 붙이지 않고 기존의 명령어로 사용할 수 있다.
create user scott identified by tiger;
==> scott 계정을 tiger 비밀번호로 생성한다.
grant connect, resource , dba to scott;
==> scott 계정의 권한 부여
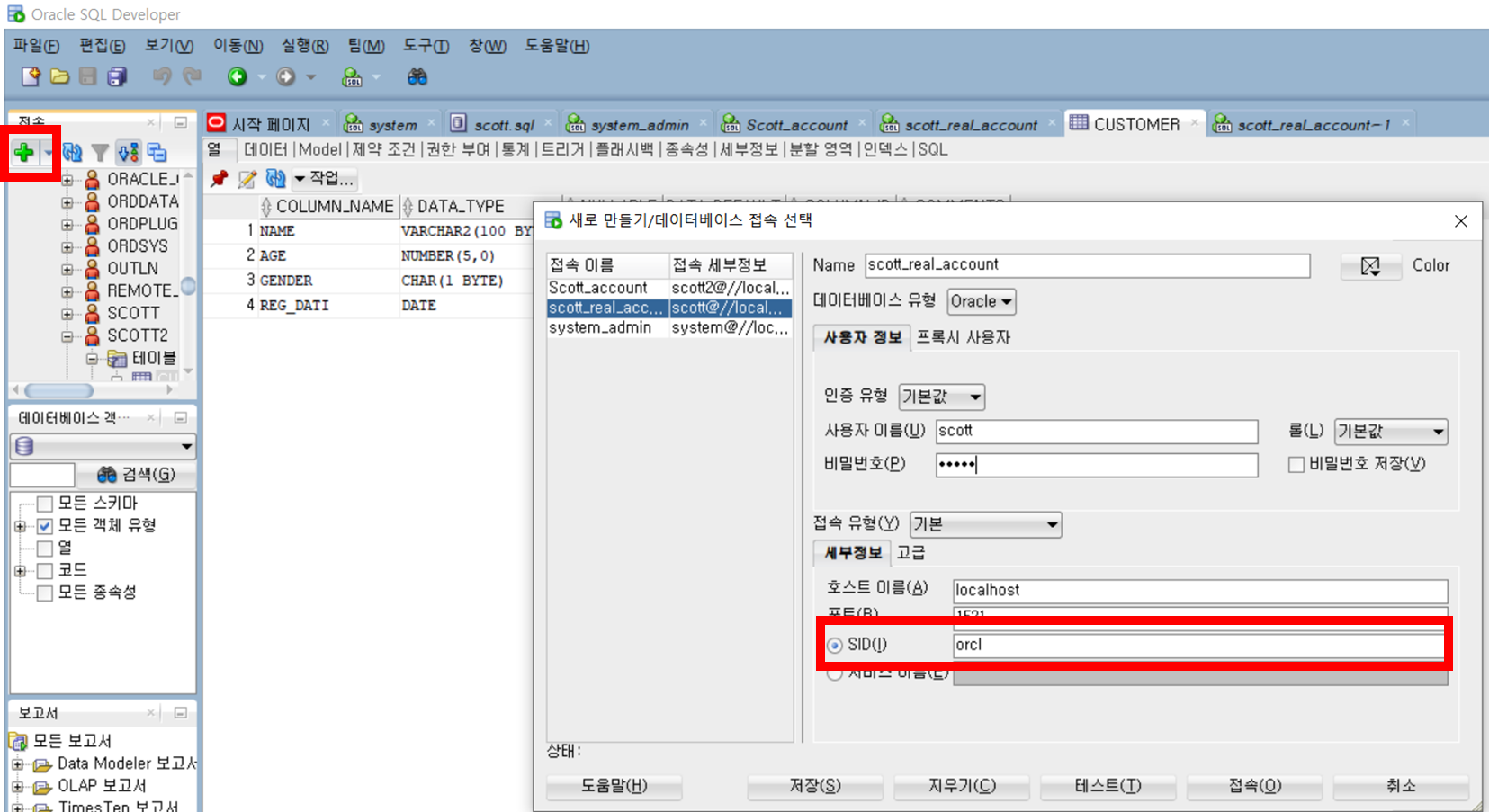
중요: SID 값 xe로 설정되어있는데 오류가 난다면 orcl로 변경한다.
이후 테스트 --> 성공 ===> 접속 클릭

scott.sql 열어준다.
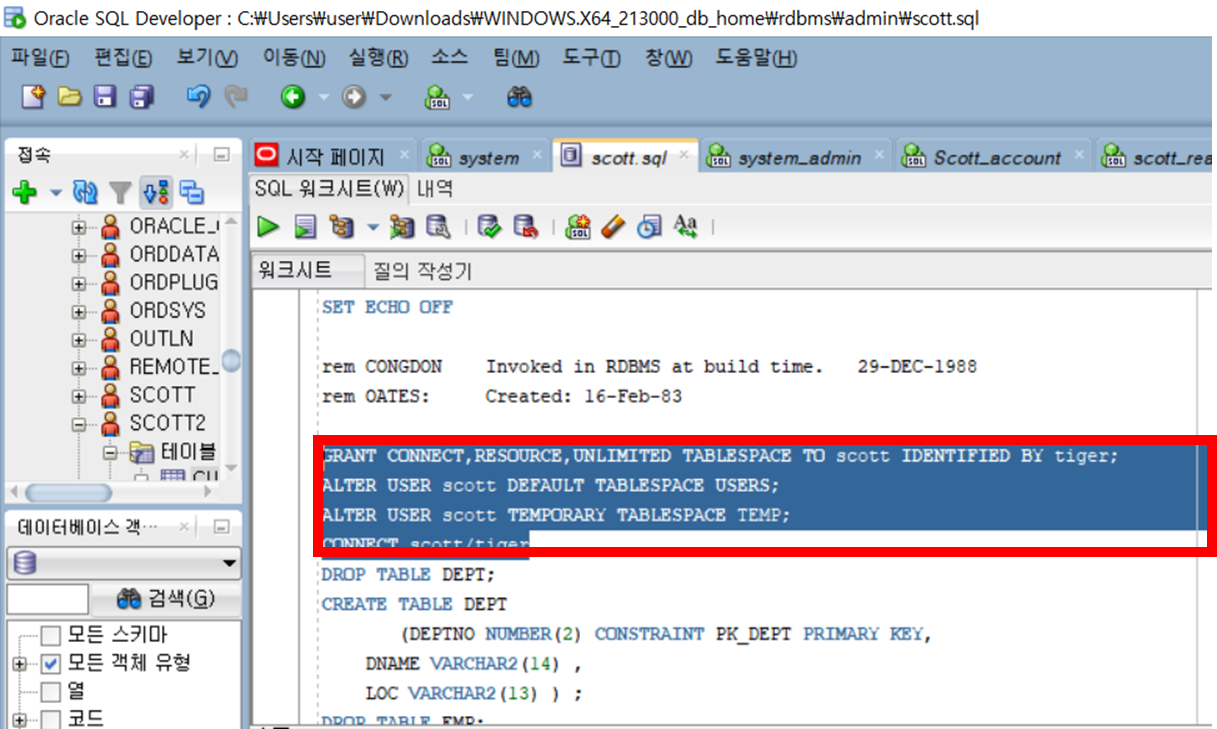
대소문자 11c 버전부터 구분하기 때문에 이부분 유의하면서 자기가 생성한 계정 대소문자 구분하여 수정할것!!
이후 오류 나서 이부분 추가
ALTER SESSION SET nls_date_language='american';
ALTER SESSION SET nls_date_format='dd-MON-rr';
계속해서 업데이트 하겠다.(대소문자 구분때문에 3시간 날림;;)
'IT에대해 알아보자 > SQL' 카테고리의 다른 글
| JetBrains DataGrip(sql IDE) 사용해보기 (0) | 2023.03.06 |
|---|