1. 랜덤 그리드 서치
==> 랜덤 그리드 서치를 활용하여 하이퍼파라미터 튜닝을 진행
==> 기존 그리드 서치와 달리 모든 조합이 아닌 랜덤으로 일부만 선택하여 모델링
https://knowallworld.tistory.com/377
[PYTHON - 머신러닝_XGBoost]★pd.options.display.max_columns★정밀도, 재현율, F1-score
1. 부스팅 알고리즘 ==> 랜덤 포레스트는 각 트리를 독립적으로 만드는 알고리즘 ==> 서로 관련 없이 생성한다. ==> 부스팅은 순차적으로 트리를 만들어 이전 트리로부터 학습한 내용이 다음 트리
knowallworld.tistory.com
※ 그리드 서치
==> 단순작업의 반복 결함 문제 ==> 그리드 서치로 한 번 시도로 수백 가지 하이퍼파라미터 값 시도 가능
==> 그리드 서치에 입력할 하이퍼파라미터 후보들을 입력 ==> 각 조합에 대해 모두 모델링 해보고 최적의 결과가 나오는 하이퍼 파라미터 조합을 알려준다.
from sklearn.model_selection import RandomizedSearchCV
params = {
'n_estimators' : [100, 500 , 1000] , # 반복 횟수
'learning_rate' : [0.01 , 0.05 , 0.1 , 0.3] , # 러닝 메이트
'lambda_l1' : [0 , 10 , 20 , 30 ,50] , # L1 정규화
'lambda_l2' : [0 , 10 , 20 , 30 , 50] , # L2 정규화
'max_depth' : [5 , 10 , 15 , 20] , # 최대 깊이
'subsample' : [0.6 , 0.8 , 1] # 서브샘플 비율
}
피처 셀렉션 : 머신러닝 학습에 사용할 피처를 선택하는 것을 의미
==> 기본적으로 많은 피처(독립변수) 가 있는 것이 풍분한 데이터이기 때문에 머신러닝 학습에 있어서 좋다고 볼 수 있다.
==> 적절하지 못한 피처가 섞인 경우에는 예측결과가 좋지 못할 수 있다. ==> 특정 피처만을 선택하여 모델링했을 때 더 좋은 결과가 나온다.
==> L1 정규화는 피처 셀렉션의 역할을 해주어 불필요한 변수들을 자동으로 학습에서 배제
==> 회귀분석은 모든 피처를 사용하기 때문에 피처 셀렉션을 지원하는 라쏘 회귀, 포워드 셀렉션, 백워드 제거, 재귀적 피처 제거 방법 사용

2. L1 정규화
==> 라쏘 회귀
선형 회귀 모델을 만들면 각 변수에 대한 기울기, 즉 계수가 구해진다. ==> 이 계수에 패널티를 부과하여 너무 큰 계수가 나오지 않도록 강제

==> x는 각 변수에 돌아가는 값이고, w는 해당 변수에 대한 기울기인 계수이다.
==> 각 변수에 들어가는 값과 기울기값을 곱한값 = ^y_i(예측값)
==> L1 정규화는 w에 절대값이 붙어진 채로 더해진다.
==> 큰 기울기값들이 많으면 오차가 더 큰 것으로 간주하여 최적의 모델을 찾을 때 배제된다.
==> 람다는 이 패널티에 대한 가중치를 의미
==> 람다는 우리가 직접 정의할수 있는 하이퍼파라미터 ==> 높은 값을 넣으면 패널티를 더 크게 만들고, 작은 값을 넣으면 패널티의 역할 또한 작아진다.
==> 매개변수에 패널티를 가해서 영향력을 감소시킨다 ==> 오버피팅을 방지하는 목적으로 쓰인다.
==> L1 정규화에서는 람다가 커질 수록 계수가 0이 된다. ==> 변수의 영향력이 사라진다.
==> 불필요한 변수를 제거할 수 있다.
3. L2 정규화
==> 릿지 회귀

==> 추가된 항의 w에 절대값 대신 제곱을 사용하여 기울기의 마이너스 부호를 해결한다
==> L1 정규화와 L2 정규화는 모두 람다값이 커질수록 강한 패널티를 부과하기 때문에 , 크기가 커질수록 변수들에 대한 계수의 절댓값이 작은 모델이 나온다.
==> L2 정규화에서는 람다가 커질 수록 계수의 절대값들이 0에 가깝게 수렴
==> 0에 수렴하여 미미하게나마 변수의 영향력이 존재하여 모든 변수들이 모델에 반영 된다.
4. 랜덤 그리드 서치 모델링
model_2 = lgb.LGBMClassifier(random_state= 100) # 모델 객체 생성
rs = RandomizedSearchCV(model_2 , param_distributions= params , n_iter= 30 , scoring= 'roc_auc' , random_state= 100 , n_jobs= -1) # 랜덤 그리드 서치 객체 생성
#n_iter = 30 ==> 몇 번을 반복할 것인가 ==> 전체 하이퍼파라미터의 조합 중 몇 개를 사용할 것인가import time
start = time.time()
rs.fit(X_train , y_train)
print(time.time())[LightGBM] [Warning] lambda_l1 is set=0, reg_alpha=0.0 will be ignored. Current value: lambda_l1=0
[LightGBM] [Warning] lambda_l2 is set=20, reg_lambda=0.0 will be ignored. Current value: lambda_l2=20
1674798443.4121811
rs.best_params_
==> subsample = 1 ==> 일부가 아닌 전체 사용
=> lambda_l1 : 0 ==> L1 정규화 사용 X
roc_auc_score(y_test , proba_1) # 정확도 확인==> 튜닝 이전 : 0.9366
rs_proba = rs.predict_proba(X_test) # 예측
roc_auc_score(y_test , rs_proba[: , 1]) # 정확도 확인0.9953122884656392
==> AUC 값이 훨씬 높아진 모습을 보인다.
rs_proba_int = (rs_proba[: , 1] > 0.2).astype('int') # 0.2기준으로 분류
print(confusion_matrix(y_test , rs_proba_int)) # 혼동 행렬 확인==> 0.2를 기준으로 0과 1로 분류
[[522519 1130]
[ 504 1508]]
print(classification_report(y_test , rs_proba_int))
정밀도 : 0.62==>0.57==> 감소
재현율 : 0.59==>0.75 ==> 증가
f1-score : 0.61==>0.65 ==> 증가
5. LightGBM의 train() 함수 사용하기
==> XGBoost와 LightGBM에서는 기본적으로 회귀와 분류의 fit() 함수를 사용하여 모델링이 가능하다.
==> train() 함수를 활용하여 모델링 가능하다.
| lgb.train() | lgb.LGBMRegressor.fit() lgb.LGBMClassifier.fit() |
|
| 검증셋 | 모델링 과정에 검증셋 지원 | 모델링에 검증셋 포함 X |
| 데이터셋 | 데이터프레임을 별도의 포맷으로 변환 | 별도의 포맷 필요없이 자동 처리 |
| 하이퍼파라미터 | 무조건 지정 | 기본값으로 모델링 |
| 사이킷런과 연동(그리드 서치, CV) | 불가능 | 가능 |
train = data[data.index < '2020-01-01'] # 훈련셋 설정
val = data[(data.index >= '2020-01-01') & (data.index < '2020-07-01')] # 검증셋 설정
test= data[data.index >= '2020-07-01'] # 시험셋 설정==> val ==> 검증셋
X_train = train.drop('is_fraud' , axis =1 ) # X_train 설정
X_val = val.drop('is_fraud' , axis =1 ) # X_val 설정
X_test= test.drop('is_fraud' ,axis = 1) # X_test 설정
y_train = train['is_fraud'] # y_train 설정
y_val = val['is_fraud'] # y_val 설정
y_test = test['is_fraud'] # y_test 설정d_train = lgb.Dataset(X_train , label=y_train) # 데이터 타입 변환
d_val = lgb.Dataset(X_val , label =y_val) # 데이터 타입 변환
# LightGBM의 Dataset()함수로 LightGBM에서 제시하는 고유한 데이터셋 형태를 취한다.
# 시험셋은 모델링할 때 사용하지 않아 훈련셋과 검증셋에 대해서만 처리해준다.params_set = rs.best_params_ # 최적 파라미터 설정
params_set['metrics'] = 'auc' # 평가 기준 추가
params_set # 하이퍼파라미터 확인
model_3 = lgb.train(params_set , d_train , valid_sets=[d_val] , early_stopping_rounds= 100 , verbose_eval=100) #학습시간 제한 , 출력물은 특정간격으로 보여주기early_stopping_rounds= 100
==> 향후 100개의 트리를 생성하였는데도 개선이 보이지 않는다면 학습을 진행하지 않는다.
verbose_eval=100
==> 100번째, 200번째 , 300번째 의 결과만 보여준다.

pred_3 = model_3.predict(X_test) # 예측==> train()함수로 훈련된 모델은 lgb.LGBMClassifier 의 predict_proba() 역할을 predict()가 대신한다.
roc_auc_score(y_test , pred_3) # 정확도 확인
==> LGBMClassifier/LGBMRegressor 를 사용시 사이킷런의 그리드 서치와 연동되고 데이터 포맷을 변경할 필요가 없어 편리하다.
feature_imp = pd.DataFrame({'feature_name' : X_train.columns , 'importance' : model_1.feature_importances_}).sort_values('importance' , ascending = False) # 중요 변수 정리
plt.figure(figsize=(20, 10))
sns.barplot(x='importance' , y = 'feature_name' , data = feature_imp.head(10))
plt.show()==> feature_importance_
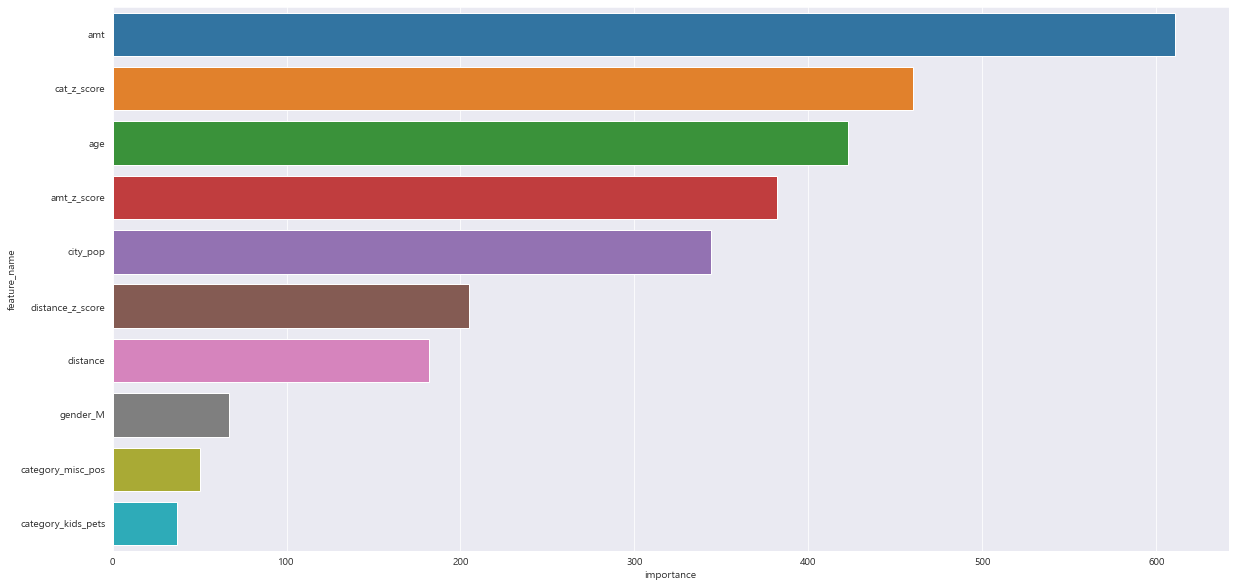
feature_imp_3 = pd.DataFrame(sorted(zip(model_3.feature_importance() , X_train.columns)) , columns = ['Value' , 'Feature']) # 중요 변수 정리
plt.figure(figsize=(20, 10))
sns.barplot(x='importance' , y = 'feature_name' , data = feature_imp.head(10))
plt.show()==> train()함수를 사용하면 검증셋을 활용할 수 있어서 조금 더 신뢰할 만한 결과를 보여준다.
==> feature_importance_

6. 정리
==> LightGBM은 XGBoost와 마찬가지로 트리 기반 모델의 최신 알고리즘.
==> 둘의 가장 큰 차이점은 트리의 가지를 어떤 식으로 뻗어나가는지.
==> XGBoost는 균형 분할 방식으로 각 노드에서 같은 깊이를 형성하도록 한층 한층 밑으로 내려온다.
==> LightGBM은 좌우 노드 수가 균등하지 않고 가지가 깊게 펼쳐진다. ==> 속도가 빠르고, 복잡성은 더 증가하고, 오버피팅 문제를 야기할 가능성이 높다.
==> GPU를 사용한다면 XGBoost가 더 빠른 속도를 보이고, CPU를 사용하면 LightGBM이 더 빠르다.
출처 : 데싸노트의 실전에서 통하는 머신러닝
(Golden Rabbit , 저자 : 권시현)
※혼자 공부용
'머신러닝 > LightGBM' 카테고리의 다른 글
| [LightGBM활용_Kaggle-타이타닉-04] 모델 돌려보기(단독_ Descision Tree) (0) | 2023.05.23 |
|---|---|
| [LightGBM활용_Kaggle-타이타닉-03] 피처별 전처리하기★pd.cut (0) | 2023.05.20 |
| [LightGBM활용_Kaggle-타이타닉-02] 피처별 전처리하기 (1) | 2023.05.20 |
| [LightGBM활용_Kaggle-타이타닉-01] EDA 및 전처리하기 (0) | 2023.05.20 |
| [PYTHON - 머신러닝_LightGBM]★geopy.distance이용한 거리계산★groupby★agg활용한 통계계산★time 라이브러리★민감도, ROC곡선★ (0) | 2023.01.27 |