[PYTHON - 머신러닝_XGBoost]★pd.options.display.max_columns★정밀도, 재현율, F1-score
1. 부스팅 알고리즘
==> 랜덤 포레스트는 각 트리를 독립적으로 만드는 알고리즘 ==> 서로 관련 없이 생성한다.
==> 부스팅은 순차적으로 트리를 만들어 이전 트리로부터 학습한 내용이 다음 트리를 만들 때 반영한다.
==> 랜덤 포레스트보다 훨씬 빠른 속도와 더 좋은 예측 능력
==> XGBoost , LightGBM , CatBoost 가 있다.
장점 :
㉠ 예측 속도가 빠르고, 예측력이 좋다.
㉡ 변수 종류가 많고 데이터가 클수록 상대적으로 뛰어난 성능을 보인다.
단점 :
㉠ 복잡한 모델인 만큼 , 해석에 어려움이 있다.
㉡ 더 나은 성능을 위한 하이퍼파라미터 튜닝이 까다롭다.
유용한 곳 :
1. 종속변수가 연속형 데이터인 경우, 범주형 데이터인 경우 모두 사용 가능
2. 이미지나 자연어가 아닌 표로 정리된 데이터의 경우
2. 데이터 확인
file_url = "https://media.githubusercontent.com/media/musthave-ML10/data_source/main/dating.csv"
pd.options.display.max_columns = 40
data = pd.read_csv(file_url , skipinitialspace= True) #빈칸 모두 제거
data.head()pd.options.display.max_columns = 40 ==> 볼 수 있는 컬럼의 수 지정
3. 전처리
data.isna().mean() # 결측치 비율 구하기==> 피처 엔지니어링에서 중요도 X 점수로 계산하기 때문에, 중요도와 관련된 변수들은 결측치를 제거하는 방향으로 처리해야한다.
data = data.dropna(subset =['pref_o_attractive' , 'pref_o_sincere' , 'pref_o_intelligence' , 'pref_o_funny' , 'pref_o_ambitious' , 'pref_o_shared_interests',
'attractive_important' , 'sincere_important' , 'intellicence_important' , 'funny_important' , 'ambtition_important' , 'shared_interests_important']) # 일부 변수에서 결측치 제거
data = data.fillna(-99) # 나머지 변수의 결측치는 -99로 대체4. 전처리 : 피처 엔지니어링
==> 데이터에 상대방 나이, 본인 나이가 있어서 , 나이차가 얼마나 나는지 계산 가능.
==> 결측치의 경우 -99를 채워넣었으므로, 단순히 나이차를 계산해서는 안된다.
==> 성별의 경우 단순한 나이 차이보다는 남자가 여자보다 많은지, 반대 경우인지도 고려하는 것이 좋다.
1> 나이 전처리
def age_gap(x):
if x['age'] == -99: # 본인 나이
return -99
elif x['age_o'] == -99: # 상대방 나이
return -99
elif x['gender'] == 'female': # gender가 female이라면
return x['age_o'] - x['age'] # age_o 에서 age를 뺀값 리턴
else:
return x['age'] - x['age_o'] # age에서 age_o를 뺀 값 리턴
# 남녀 중 한명이라도 나이가 -99이면 -99를 반환한다.data['age_gap'] = data.apply(age_gap , axis = 1)
data['age_gap_abs'] = abs(data['age_gap']) # 절댓값 적용
data
2> 같은 인종 여부
def same_race(x) : # 함수 정의 ==> 인종 데이터 관련 피처 엔지니어링
if x['race'] == -99: # race가 -99 면(결측치 이면)
return -99
elif x['race_o'] == -99 :
return -99
elif x['race'] == x['race_o']: # 인종이 같으면
return 1
else: # 인종이 다르면
return -1data['same_race'] = data.apply(same_race , axis = 1)
data
3> 같은 인종의 중요도 전처리
def same_race_point(x):
if x['same_race'] == -99:
return -99
else:
return x['same_race'] * x['importance_same_race']data['same_race_point'] = data.apply(same_race_point , axis =1)
# data에 same_race_point 함수를 적용한 결과를 same_race_point 변소로 저장
==> 1과 -1로 선정해야 적절한 변별력을 가질 수 있다.
parther_imp = data.columns[8:14] # 상대방 중요도
parttner_rate_me = data.columns[14:20] # 본인에 대한 상대방의 평가
my_imp = data.columns[20:26] # 본인의 중요도
my_rate_partner = data.columns[26:32] # 상대방에 대한 본인의 평가new_label_partner = ['attractive_p' , 'sincere_partner_p' , 'intelligence_p' , 'funny_p' , 'ambition_p' , 'shared_interests_p']
# 상대방 관련 새 변수
new_label_me = ['attractive_m' , 'sincere_partner_m' , 'intelligence_m' , 'funny_m' , 'ambition_m' , 'shared_interests_m']
# 본인 관련 새 변수def rating(data, importance , score) : # 함수 정의
if data[importance] == -99 :
return -99
elif data[score] == -99 :
return -99
else:
return data[importance] * data[score];==> 평가점수 x 중요도 계산 함수
for i,j,k in zip(new_label_partner , partner_imp , partner_rate_me) :
data[i] = data.apply(lambda x : rating(x,j,k) , axis =1 ) # x= 데이터프레임, j = 중요도 변수 이름 , k = 평가 변수
for i,j,k in zip(new_label_me, my_imp , my_rate_partner):
data[i] = data.apply(lambda x : rating(x,j,k) , axis =1 )data = pd.get_dummies(data , columns = ['gender' , 'race' , 'race_o'] , drop_first= True) # 더미 변수로 변환
data==> object 타입 변수들은 문자 형태이기 때문에, 숫자 형태가 되게끔 더미변수로 전환
https://knowallworld.tistory.com/372
[PYTHON - 머신러닝_로지스틱선형회귀]★로지스틱 선형회귀★상관관계★원-핫 인코딩★정확도★
1. 로지스틱 회귀 ==> 로지스틱 회귀 또한 선형 회귀처럼 기본 분석 모델이다. ==>선형 회귀 분석은 연속된 변수를 예측하는 반면 , 로지스틱 회귀 분석은 Yes/No처럼 2가지로 나뉘는 분류 문제를 다
knowallworld.tistory.com
==>파이썬은 자료형이 object인 변수들 , 데이터가 숫자가 아닌 문자인 변수를 이해 못한다.
EX) object형을 숫자로 대체하는 방법, 계절의 경우 봄,여름,가을,겨울을 각각 1,2,3,4로 변환
5. 모델링 및 평가
from sklearn.model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split(data.drop('match', axis =1) , data['match'] , test_size= 0.2 , random_state= 100) # 훈련셋/ 시험셋 분리==> 훈련 셋 , 시험셋 분리
import xgboost as xgb
model = xgb.XGBClassifier(n_estimators = 500 , max_depth = 5 , random_state = 100) # 모델 객체 생성
model.fit(X_train , y_train) # 훈련
pred = model.predict(X_test) # 예측
from sklearn.metrics import accuracy_score , confusion_matrix , classification_report
accuracy_score(y_test , pred) # 정확도==> 독립변수 훈련 셋 X_train , 종속변수 훈련 셋 y_train으로 훈련
==> 독립변수 훈련 셋으로 예측 진행
==> 정확도는 (종속변수 시험셋, 예측값과의 차이) 를 이용하여 계산
==> 0.8616236162361623
==> 86% 정확도 ==> 종속변수 match의 평균값은 0.164이다.
==> 매칭된 경우가 16% 정도라는 것이다. 나머지 84%는 매칭되지 않았다.
==> 모델링 없이 모든 경우를 0으로만 예측해도 84%는 맞출 수 있다.
https://knowallworld.tistory.com/374
[PYTHON - 머신러닝_나이브베이즈]★string.punctuation 특수문자★join함수★nltk.download('stopword')★불용
1. 나이브 베이즈 ==> 조건부 확률 기반의 분류 모델 https://knowallworld.tistory.com/232 ★Multi Indexing★곱의 법칙★조건부 확률★기초통계학-[Chapter04 - 확률-04] 1. 조건부확률(Conditional Probability) ==> 0보다
knowallworld.tistory.com
==> confusion_matrix() ==> 혼동(오차) 행렬 ==> 제 1종오류 , 제 2종오류 출력 가능
[[1291 74]
[ 151 110]]
| 실제값 \ 예측값 | 0 | 1 |
| 0 | 1291 | 74 |
| 1 | 151 | 110 |
==> 실제로 매칭이 안되었는데, 실제로 매칭이 안되었다고 예측한 경우 : 1291 건
==> 실제로 매칭이 되었는데, 실제로 매칭되었다고 예측한경우 : 110 건
==> 실제로 매칭이 안되었는데, 매칭이 되었다고 예측한 경우 : 74 건(제 1종 오류)
==> 실제로 매칭이 되었는데 , 매칭이 안되었다고 예측한 경우 : 151 건 (제 2종 오류)
==> 모델 간의 비교/평가를 진행할 때는 오류 유형에 따른 평가를 해야한다.
print(classification_report(y_test , pred))
precision recall f1-score support
0 0.90 0.95 0.92 1365
1 0.60 0.42 0.49 261
accuracy 0.86 1626
macro avg 0.75 0.68 0.71 1626
weighted avg 0.85 0.86 0.85 1626
==> 정밀도, 재현율 , F1-점수 , 인덱스에 해당하는 개수
==> 예측하려는 값 1에 대한 해석
정밀도(precision)은 1로 예측한 경우 중, 얼마만큼이 실제로 1인지를 나타낸다.
==> 양성을 양성으로 판단 / (양성을 양성으로 판단 + 1종오류) ==> 1 종오류가 중요하면 정밀도에 주목
재현율(recall)은 실제로 1 중에, 얼마만큼을 1로 예측했는지를 나타낸다.
==> 양성을 양성으로 판단/ (양성을 양성으로판단 + 2종오류) ==> 2 종오류가 중요하면 재현도에 주목
F1-점수(F1-score)은 정밀도와 재현율의 조화평균을 의미한다.
==> 2 * (정밀도 * 재현율) / (정밀도 + 재현율) ==> 1 종오류, 2종오류 중요한 오류가 없다면 F1-SCORE 활용
※ 조화평균 : 주어진 수들의 역수의 산술평균의 역수
H = 2 * a_1 * a_2 / (a_1 + a_2)
※ 산술평균 : 주어진 수의 합을 수의 개수로 나눈 값
A = (a_1 + a_2) / 2
6. 그리드 서치 : 하이퍼파라미터 튜닝
==> 이전의 하이퍼파라미터 뉴닝은 임의 값들을 넣어 더 나은 결과를 찾는 방식
==> 단순작업의 반복 결함 문제 ==> 그리드 서치로 한 번 시도로 수백 가지 하이퍼파라미터 값 시도 가능
==> 그리드 서치에 입력할 하이퍼파라미터 후보들을 입력 ==> 각 조합에 대해 모두 모델링 해보고 최적의 결과가 나오는 하이퍼 파라미터 조합을 알려준다.
max_depth = [3,5,10]
learning_rate = [0.01, 0.05 , 0.1]
#==> 그리드 서치 적용시 9가지 조합 생성
# 9가지 조합을 각각 모델링 ==> 그리드 서치에서는 교차검증도 함께 사용 ==> 교차검증의 횟수만큼 곱해진 횟수가 모델링==> K-폴드값을 5로 교차검증한다면 9*5 = 45회의 모델링 진행
https://knowallworld.tistory.com/376
[PYTHON - 머신러닝_랜덤 포레스트]★str.split(expand= True)★K-폴드 교차검증★하이퍼파라미터 튜닝
1. 랜덤 포레스트 ==> 결정 트리의 단점인 오버피팅 문제를 완화시켜주는 발전된 형태의 트리 모델이다. https://knowallworld.tistory.com/375 [PYTHON - 머신러닝_결정트리]★예측력, 설명력★빈칸 제거_skipin
knowallworld.tistory.com
데이터를 특정 개수(K개) 로 쪼개어서 그중 하나씩을 선택하여 시험셋으로 사용하되, 이 과정을 K번만큼 반복
from sklearn.model_selection import GridSearchCV #import
parameters = {
'learning_rate' : [0.01 , 0.1 , 0.3] ,
'max_depth' : [5 , 7 , 10] ,
'subsample' : [0.5 , 0.7 , 1] ,
'n_estimators' : [300, 500 , 1000]
} # 하이퍼파라미터 셋 정의
1> learning_rate : 경사하강법에서 '매개변수'를 얼만큼씩 이동해가면서 최소 오차를 찾을지, 그 보폭의 크기를 결정하는 하이퍼파라미터
==> 보폭은 미분계수에 의해 결정된다. ==> 학습률이라고도 한다.
==> 너무 작은 학습률(보폭)을 가지면 최소 에러값을 찾는데 상당한 시간이 들고, 지역 최소해에 빠질 가능성이 있다.
==> 너무 큰 학습률(보폭)을 가지면, 최소 에러를 정확히 찾지 못하고 좌우로 계속 넘어다닌다.
2> max_depth : 각 트리의 깊이 제한
3> subsample : 모델을 학습시킬 때 일부 데이터만 사용하여 각 트리 생성. 0.5를 쓰면 데이터의 절반씩만 랜덤 추출하여 트리 생성
4>n_estimators : 전체 나무의 개수
gs_model = GridSearchCV(model , parameters ,n_jobs=-1 , scoring='f1' , cv = 5) # n_jobs 는 사용할 코어 수 , scoring은 모델링할때 어떤 기준으로 최적의 모델을 평가할지, cv는 K-FOLD 값gs_model.fit(X_train , y_train) # 학습==> 하이퍼파라미터셋이 총 4종류 , 3개씩 값이 있으므로 , 3**4 = 81번의 모델링
==> 교차검증 5회 ==> 81 * 5 = 405번의 모델링 작업 ==> 소요시간이 길다.
gs_model.best_params_ # 최적의 하이퍼파라미터 출력==> 최적의 파라미터 출력
==> {'learning_rate': 0.300,
'max_depth': 5,
'n_estimators': 1000,
'subsample': 0.500}
pred = gs_model.predict(X_test)==> 예측값 생성
accuracy_score(y_test , pred)==> 0.8610086100861009 => 정확도 계산
print(classification_report(y_test , pred)) precision recall f1-score support
0 0.90 0.94 0.92 1365
1 0.59 0.44 0.50 261
accuracy 0.86 1626
macro avg 0.74 0.69 0.71 1626
weighted avg 0.85 0.86 0.85 1626
==> 이전에 비해 정확도는 미세하게 올라갔고, F1-점수는 0.02 상승했다.
==> 하이퍼파라미터 튜닝으로 엄청난 개선을 얻기는 힘들다. 예측에는 피처 엔지니어링과 모델 알고리즘 선정이 큰 영향을 미친다. 하이퍼파라미터 튜닝은 조금이라도 더 나은 모델을 만드는 역할이다.
7. 중요 변수 확인
==> 선형 회귀와 로지스틱 회귀에서는 계수로, 결정 트리에서는 노드의 순서로 변수의 영향력을 확인했다.
==> XGBoost에 내장된 함수는 변수의 중요도 까지 계산해준다.
==> 그리드 서치로 학습된 모델에서는 이 기능을 사용할 수 없다. ==> 그리드 서치에서 찾은 최적의 하이퍼파라미터 매개변수 조합으로 다시 한번 학습시킨다.
model = xgb.XGBClassifier(learning_rate = 0.3 , max_depth = 5 , n_estimators = 1000 , subsample = 0.5 , random_state = 100)
model.fit(X_train , y_train)model.feature_importances_ # 변수 중요도 확인
feature_imp = pd.DataFrame({'features' : X_train.columns , 'values' : model.feature_importances_}) #데이터프레임으로 전환
feature_imp
plt.figure(figsize = (20 , 10))
sns.barplot(x='values' , y='features' , data = feature_imp.sort_values(by = 'values' , ascending=False).head(10))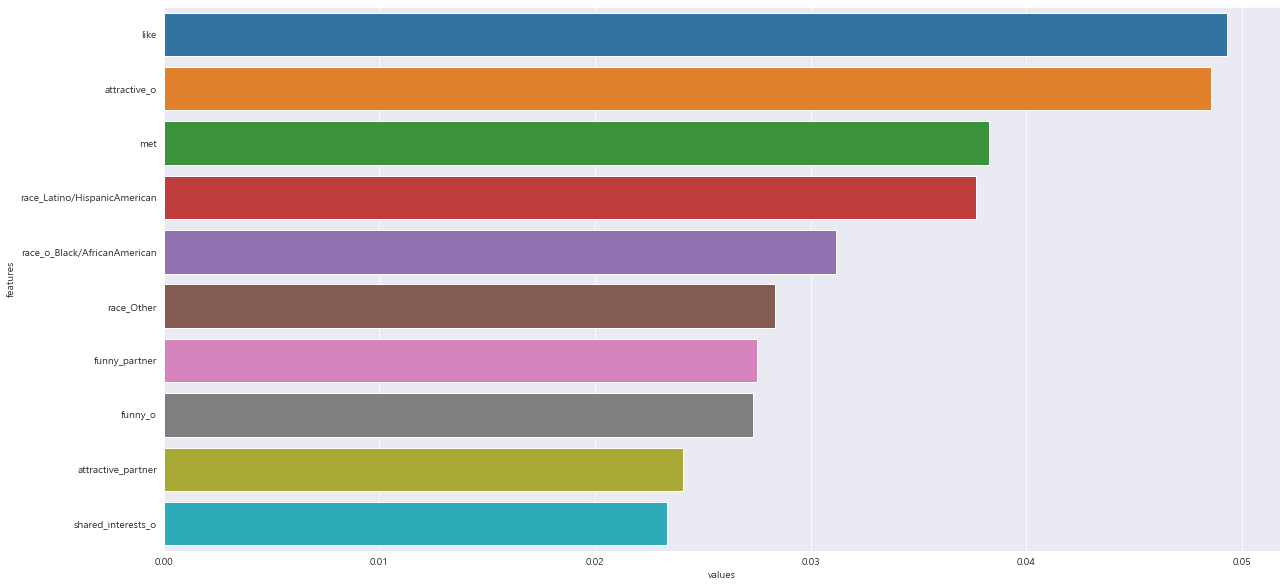
출처 : 데싸노트의 실전에서 통하는 머신러닝
(Golden Rabbit , 저자 : 권시현)
※혼자 공부용