★vlines()★선형회귀★평균제곱 오차(MSE)★Tensorflow이용 머신러닝-[Chapter 03-01]딥러닝★
1. 가장 훌륭한 예측선 긋기 : 선형 회귀
==> 딥러닝은 자그마한 통계의 결과들이 무수히 얽히고 설켜 이루어지는 복잡한 연산
==> 가장 말단에서 일어나는 2가지 계산원리 ==> '선형회귀' , '로지스틱 회귀'
1-1> 선형회귀(Linear Regression)
==> 학생들의 중간고사 성적이 [ ] 에 따라 다 다르다.
==> [ ] 애 들어갈 내용을 '정보' 라고 한다. ==> 머신러닝과 딥러닝은 이 정보가 필요하다.
==> 성적을 변하게 하는 '정보' 요소를 x
==> 이 x 값에 따라 변하는 '성적'을 y
==> x값이 변함에 따라 y값도 변한다. ==> 독립적으로 변할 수 있는 값 x를 독립변수라고 한다.
https://knowallworld.tistory.com/189
--> 참고
==> 이 독립변수에 따라 종속적으로 변하는 y를 종속 변수라고 한다.
==> 선형 회귀란 독립 변수 x를 사용해 종속 변수 y의 움직임을 예측하고 설명
1-2> 단순 선형 회귀(Simple Linear Regression)
==>하나의 x값만으로도 y값 설명 가능
EX) 단순 선형회귀
A = list("2시간 4시간 6시간 8시간".split(" "))
B = list(map(int, "81 93 91 97".split(" ")))
C = pd.DataFrame([B] , columns=A)
C.index = ['성적']
Cfig = plt.figure(figsize=(15,8))
ax = sns.scatterplot(x= A , y = B)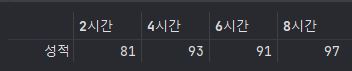
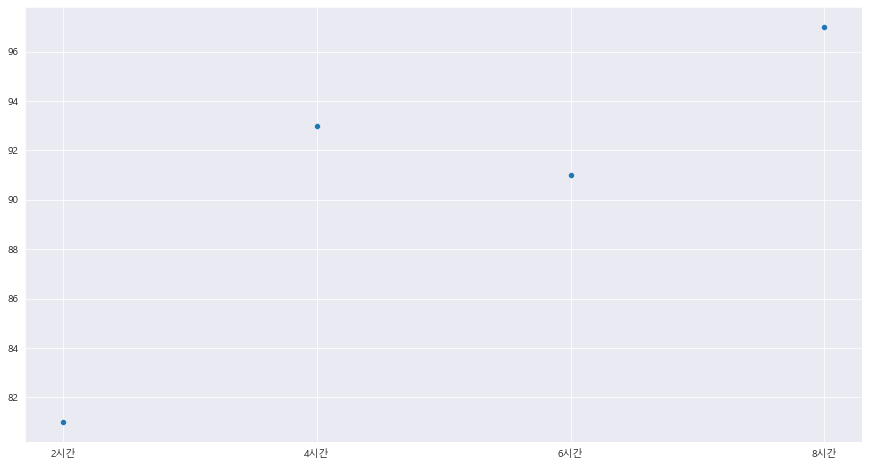
==> 선은 직선 ==> 1차 함수 그래프 ==> y= ax + b
==> x값의 변화에 따라 y 값은 반드시 변화
==> 직선의 기울기 a값과 y절편 b값을 정확히 예측해야 한다. ==> 선형회귀의 작업
1-3> 다중 선형 회귀(Multiple Linear Regression)
==> x값이 여러개 필요할때
2-1> 최소 제곱법(Method of least squares)
==> 선형회귀의 중요 목표 : 가장 정확한 직선 긋기
==> 최소 제곱법 이용하여 일차 함수의 기울기 a와 y절편 b를 바로 구할 수 있다.
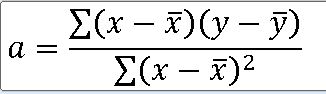


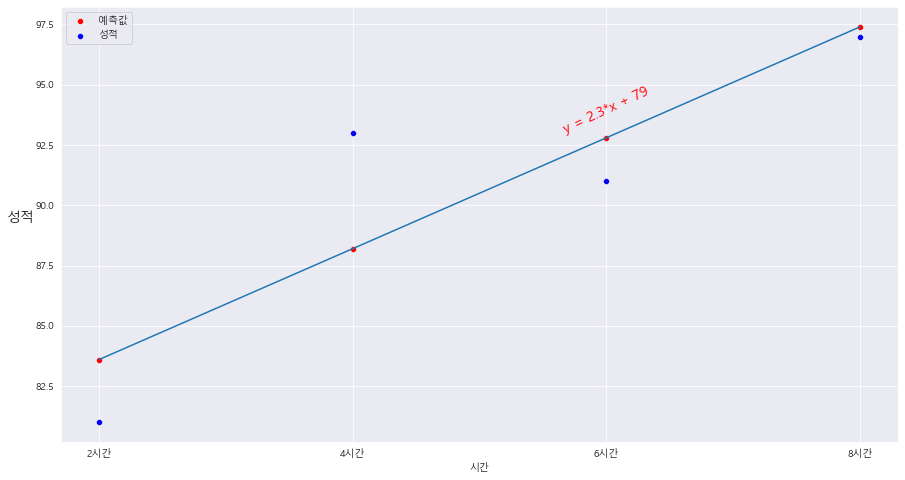
fig = plt.figure(figsize=(15,8))
ax = sns.scatterplot(x= D['시간'] , y = D['예측값'] , color='red')
ax = sns.scatterplot(x= D['시간'] , y = D['성적'] , color='blue' )
plt.legend(labels = ['예측값', '성적' ])
ax = sns.lineplot(x= D['시간'] , y = D['예측값'])
ax.set_ylabel('성적' , fontsize = 14 , labelpad= 14 ,rotation = 0)
plt.annotate('y = {}*x + {}'.format(alpha,int(beta)) , xy=(7,95) , rotation = 25 , ha ='center' , va = 'baseline' , fontsize = 14 , color= 'red')==> annotate 주목!
3> 평균 제곱 오차(Mean Square Error , MSE)
==> 위의 성적 데이터의 경우 X변수가 1개
BUT. 딥러닝 활용 데이터는 X변수가 다양하다.
==>가장 많이 사용하는 방법은 '조금씩 수정하기'
==> X변수에 대한 변화를 주어 오차가 최소가 될 때까지 이 과정을 계속 반복
fig = plt.figure(figsize=(15,8))
#ax = sns.scatterplot(x= D['시간'] , y = D['예측값'] , color='red')
ax = sns.scatterplot(x= D['시간'] , y = D['성적'] , color='blue' )
#plt.legend(labels = ['예측값', '성적' ])
plt.legend(labels = ['성적'])
#ax = sns.lineplot(x= D['시간'] , y = D['예측값'])
x = np.arange(1,10,0.5)
def graph(x):
return (3*x + 76)
ax = sns.lineplot(x , graph(x))
ax.set_ylabel('성적' , fontsize = 14 , labelpad= 14 ,rotation = 0)
#a = pd.DataFrame(graph(D['시간']) - D['성적'])
time = D['시간'].tolist()
score = D['성적'].tolist()
#(graph(time[i]) - score[i]) //2
for i in range(len(time)):
ax.vlines(x= time[i], ymin= score[i] , ymax=graph(time[i]) , color = 'blue' , linestyle ='solid' , label ='{}'.format(2))
ax.text(time[i]+0.1 , max(score[i],graph(time[i])) - abs((score[i]- graph(time[i]))//2) , f'오차 : {round(a[i])}',fontsize=13)==> ax.axvline() 이 아닌 vlines() 사용이 편하다! ==> 좌표 기준으로 막대기를 그릴 수 있다!
max(score[i],graph(time[i])) - abs((score[i]- graph(time[i]))//2)==> ax.text()의 좌표 구할때
==> 잘 생각해봐~~

errors = []
for i in range(len(score)):
errors.append(score[i] - graph(time[i]))
D['오차'] = errors
D = D.iloc[:, [0,2,3]].transpose()
D
오차의 합: 예측값 - 실제값

평균제곱오차(MSE)

errors = []
for i in range(len(score)):
errors.append(score[i] - graph(time[i]))
D['오차'] = errors
D = D.iloc[:, [0,2,3]]
D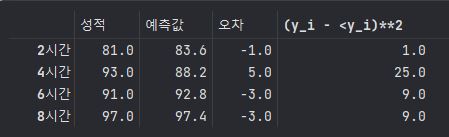
D['(y_i - <y_i)**2'] = (D['오차'])**2
b = np.mean(D.loc[:,'(y_i - <y_i)**2'])
print('평균 제곱 오차(MSE) : {}'.format(b))평균 제곱 오차(MSE) : 11.0
==> np.mean() 주목!
==> 평균 제곱 오차의 계산 결과가 가장 작은 선을 찾는 작업!!!
==> 선형 회귀란 임의의 직선을 그어 이에 대한 평균 제곱 오차 구하기
==> 이 값을 가장 작게 만들어 주는 a와 b값을 찾아가는 작업!!
'딥러닝 > 선형회귀_로지스틱회귀' 카테고리의 다른 글
| ★Sympy 이용 PYTHON 미분★딥러닝 기초수학★Tensorflow이용 머신러닝-02 딥러닝★ (0) | 2022.11.29 |
|---|---|
| ★Tensorflow이용 머신러닝-01 딥러닝★ (0) | 2022.11.28 |